Download as PDF, PPTX







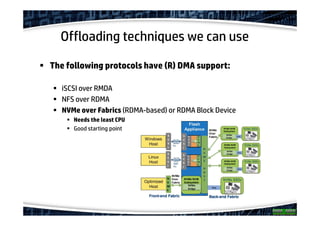
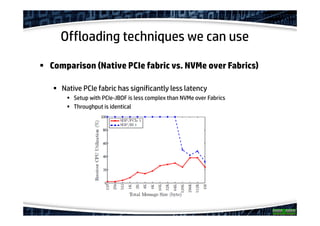

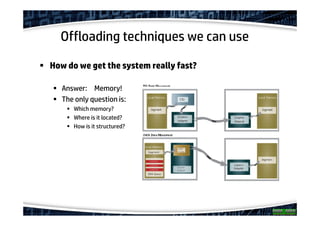
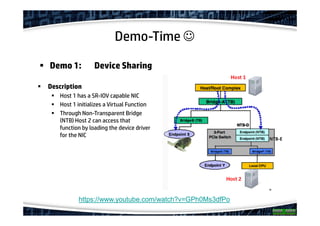

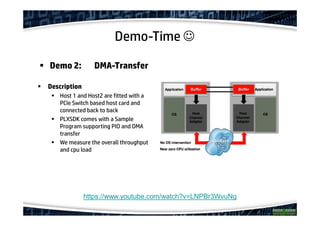









The document explores the concept of offloading in database management, showcasing various techniques and implementations that can help save resources on database servers. It includes discussions of hardware setups, such as DMA engines, and protocols like RDMA for improving data transfer efficiency. The presentation concludes with findings about generic offloading capabilities and the performance potential of fabric-attached memory in database contexts.






















































![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)


