Download to read offline


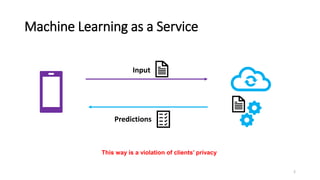
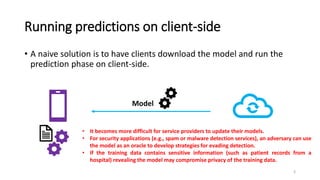

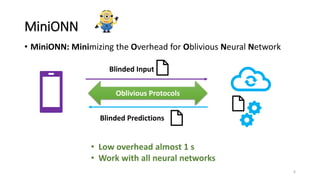
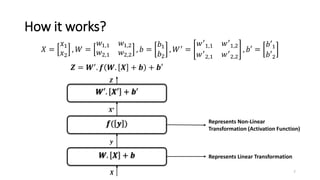
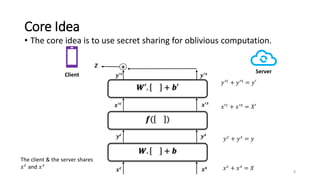
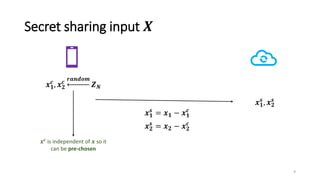
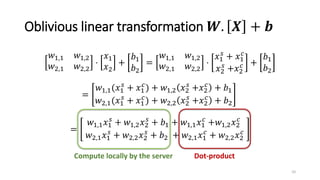
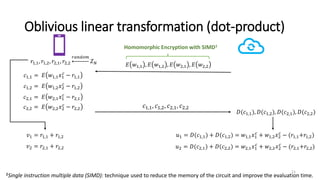
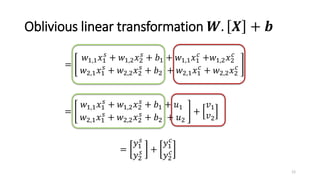

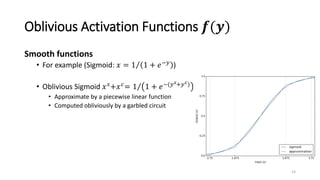
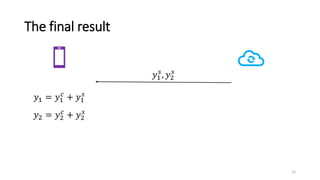



This document summarizes the Oblivious Neural Network Predictions via MiniONN Transformations paper. 1) MiniONN is a technique that allows a server to perform predictions using a neural network model on a client's private input, while revealing no information about the input or model. It uses secret sharing and oblivious computation to perform predictions without privacy violations. 2) MiniONN works by having the client and server secretly share the client's input between them. Oblivious linear transformations and activation functions are then computed to produce the prediction, without either party learning the other's data. 3) Experiments show MiniONN can perform predictions on common models like CNNs and LSTMs with low