Downloaded 88 times





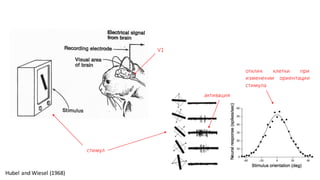
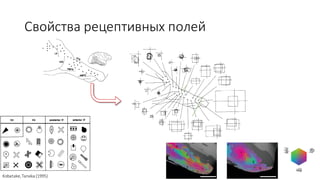
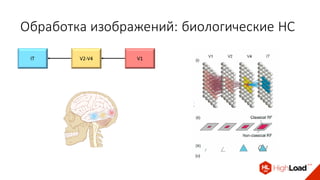


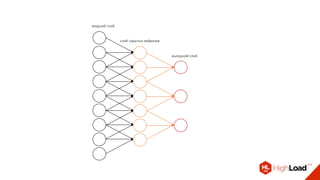




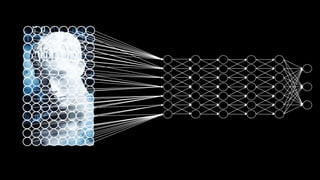
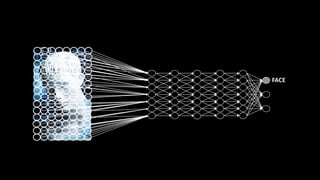

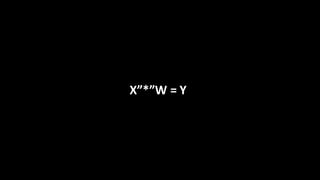


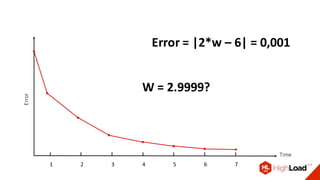







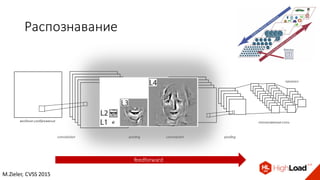

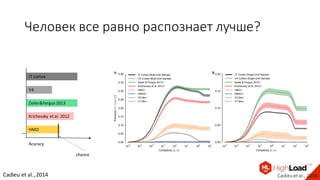



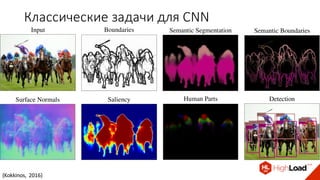

















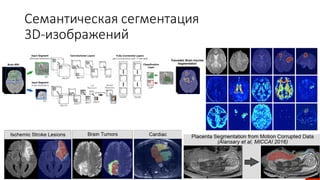




Документ посвящен видам нейронных сетей и их применению в различных областях, таких как обработка изображений, распознавание лиц и робототехника. Он охватывает основные архитектуры, включая свёрточные и рекуррентные нейронные сети, и их использование в современных задачах, таких как идентификация объектов и распознавание эмоций. Также рассматривается высокоточная работа систем идентификации на больших объемах данных и нестандартные применения нейронных сетей.














![[SuperSliv.biz] Как работают нейросети .pdf](https://cdn.slidesharecdn.com/ss_thumbnails/supersliv-250629200120-acab90ca-thumbnail.jpg?width=640&height=640&fit=bounds)
































