Downloaded 77 times




















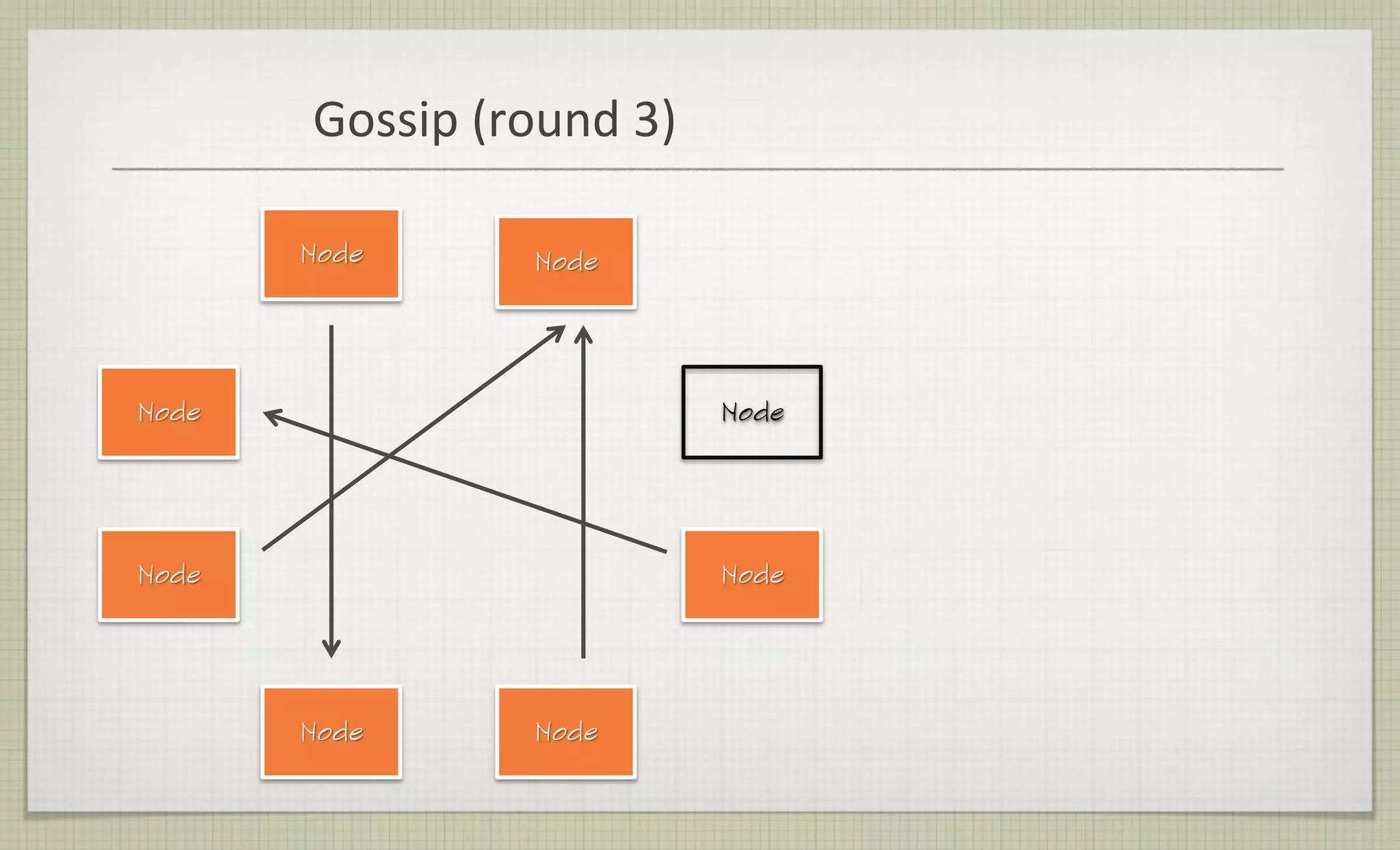
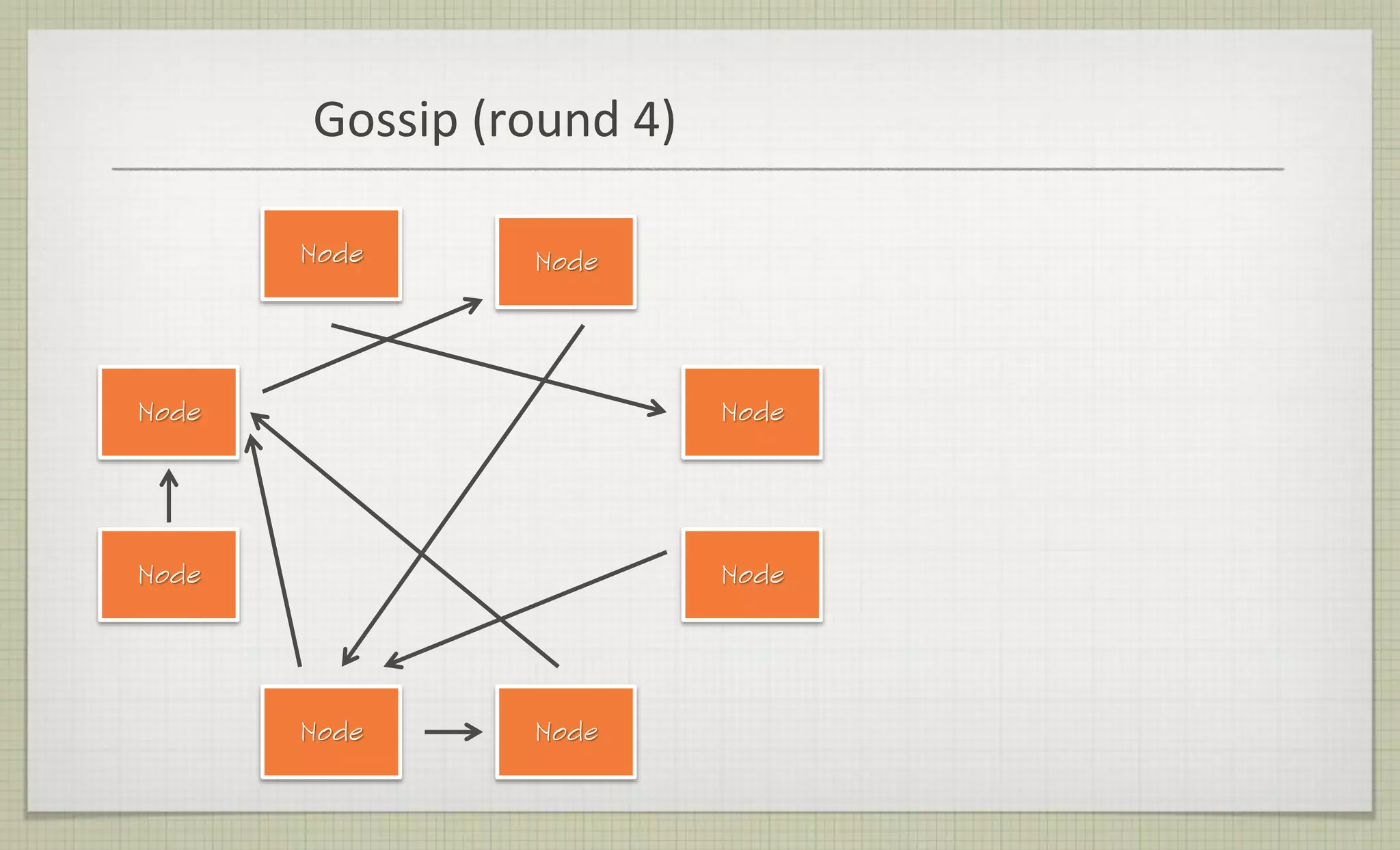




This document provides an overview of NoSQL databases, including why they are used, common types, and how they work. The key points are: 1) SQL databases do not scale well for large amounts of distributed data, while NoSQL databases are designed for horizontal scaling across servers and partitions. 2) Common types of NoSQL databases include document, key-value, graph, and wide-column stores, each with different data models and query approaches. 3) NoSQL databases sacrifice consistency guarantees and complex queries for horizontal scalability and high availability. Eventual consistency is common, with different consistency models for different use cases.























































































