










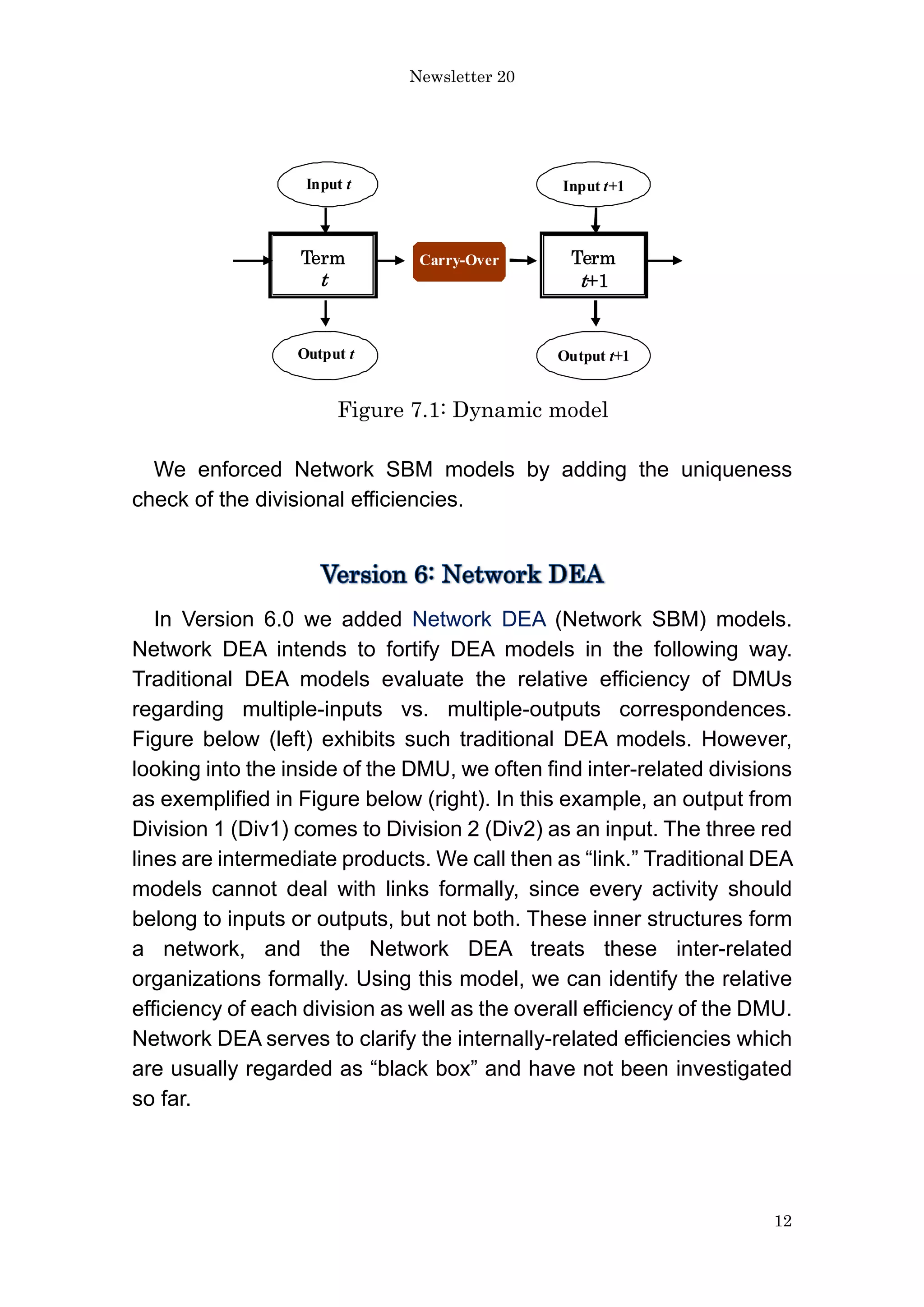






The document discusses various models in Data Envelopment Analysis (DEA) for evaluating efficiency in decision-making units (DMUs), particularly focusing on handling large data sets, undesirable outputs, and the introduction of desirable inputs. It outlines the evolution of models from traditional methods to newer approaches such as the SBM_bounded model, directional distance model, and the dynamic SBM with network structures. Additionally, it highlights the importance of these models in addressing practical constraints and improving efficiency evaluations across diverse fields.



































































