Download to read offline


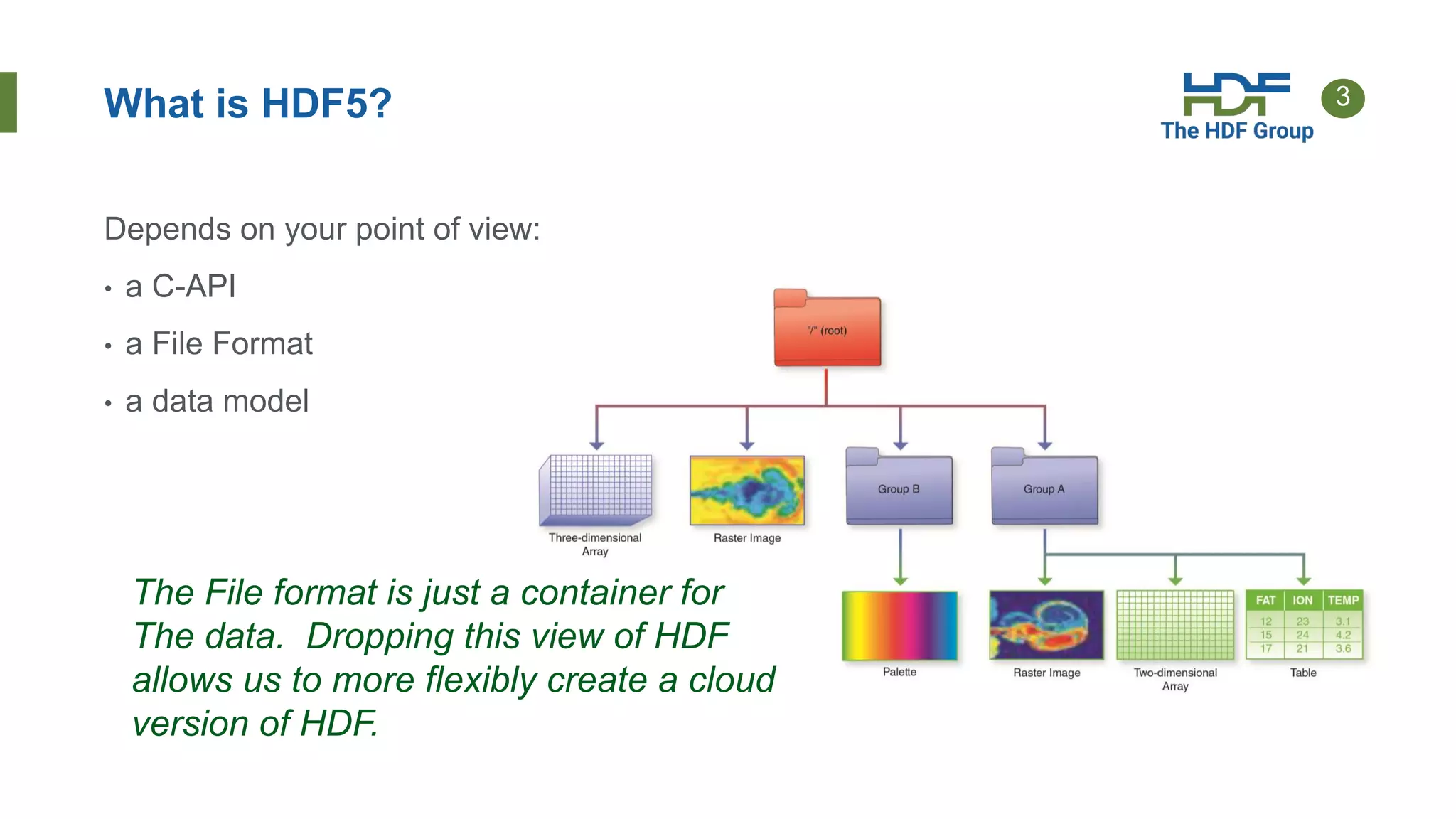

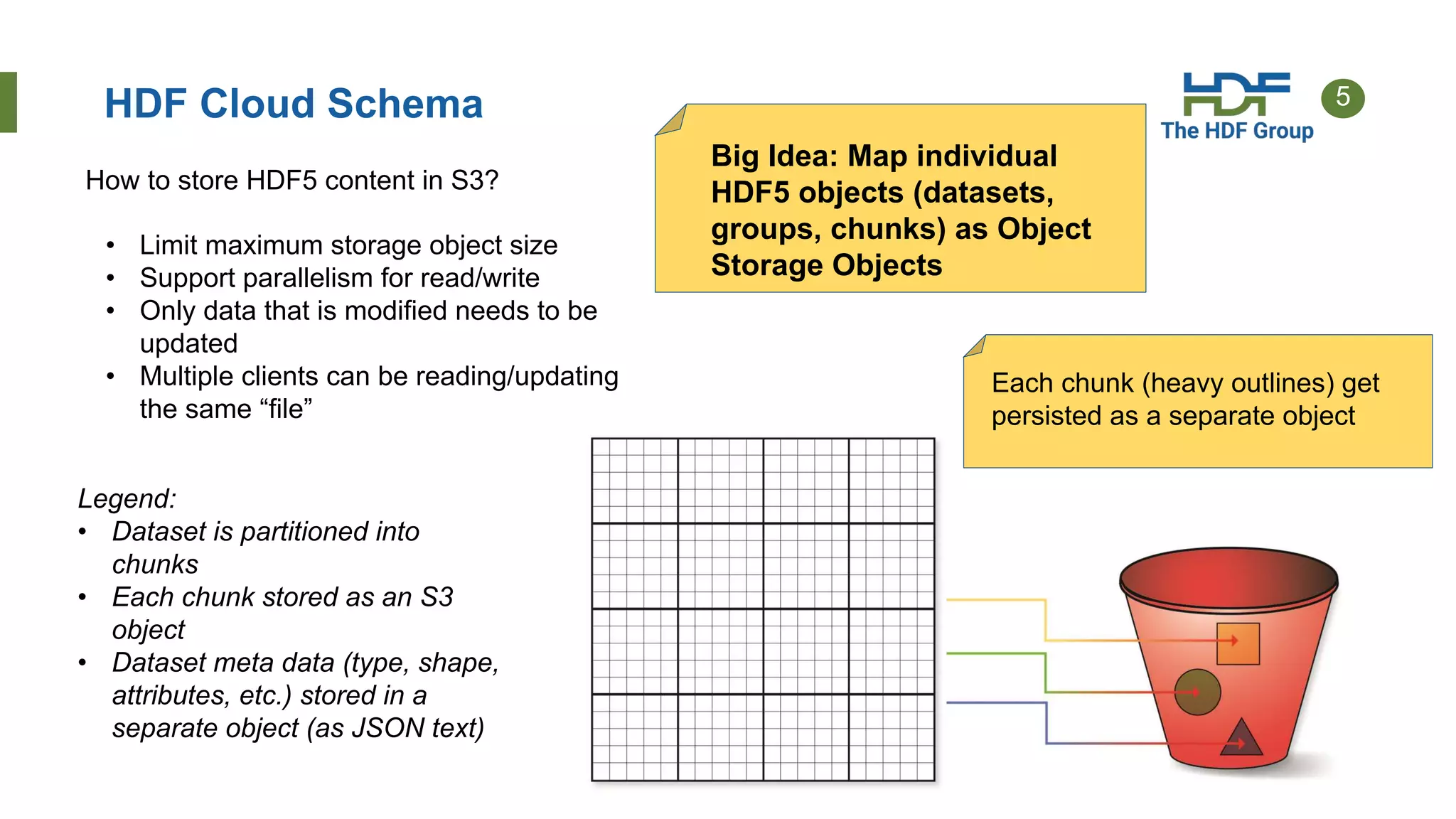
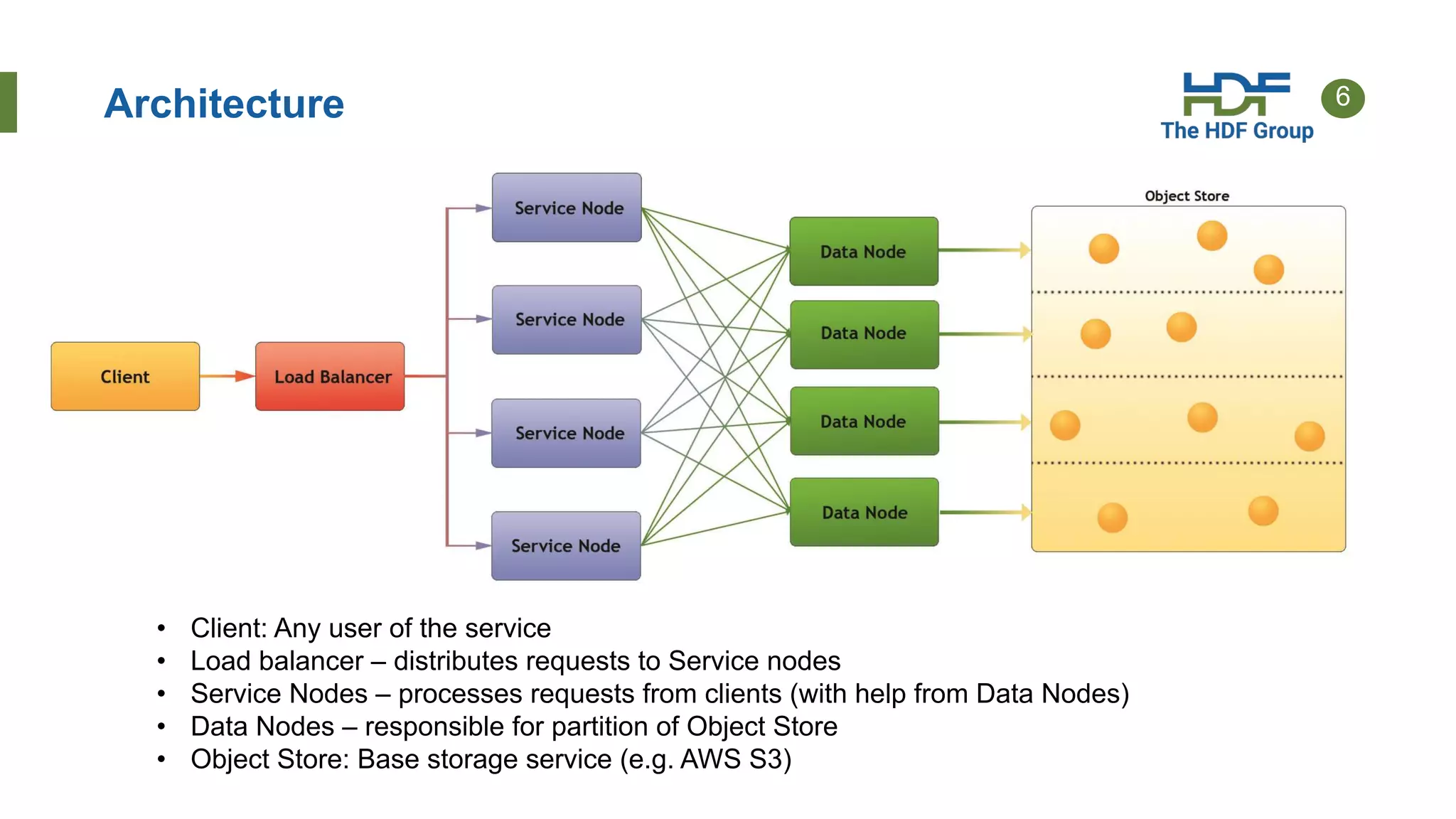


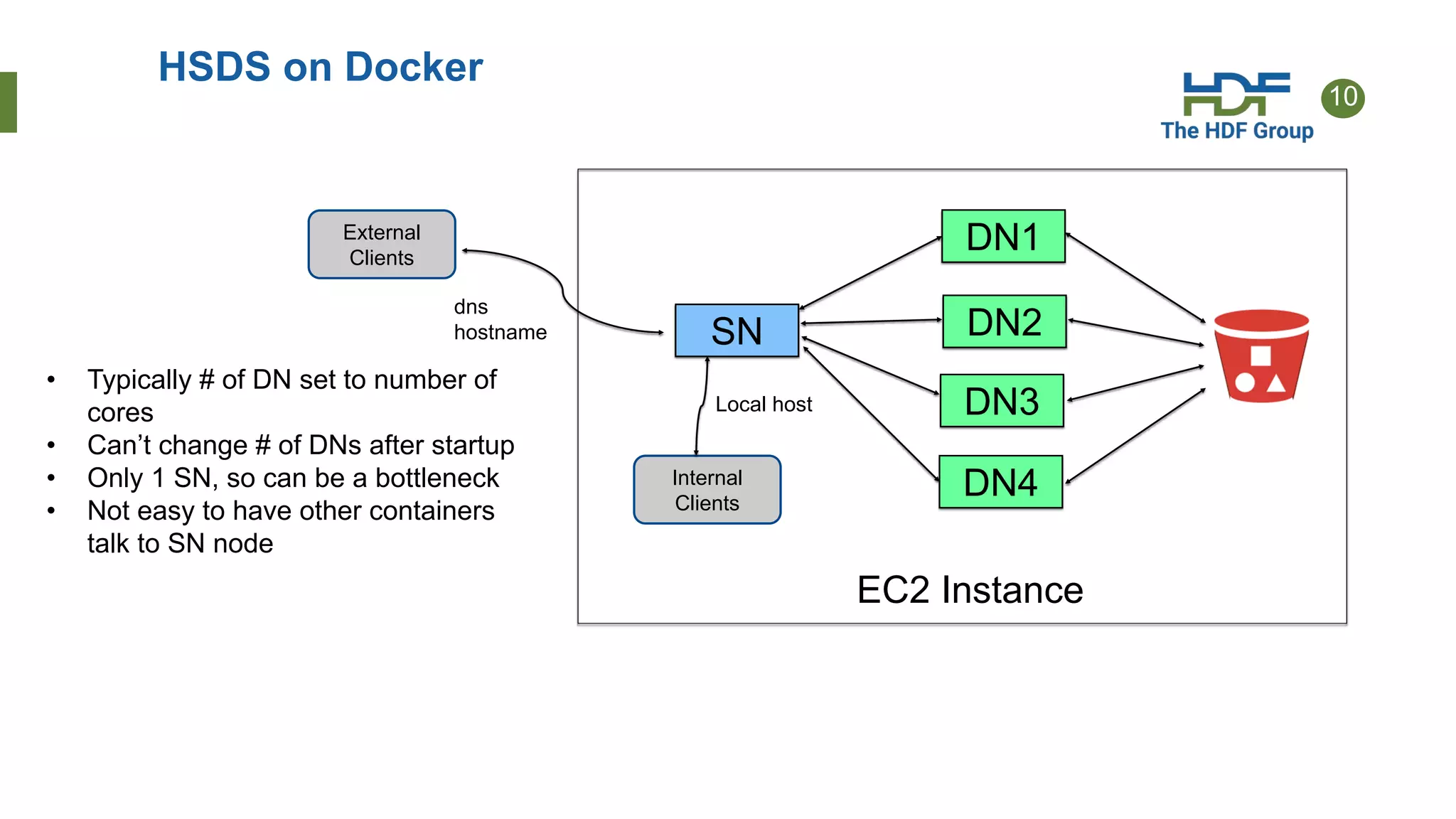
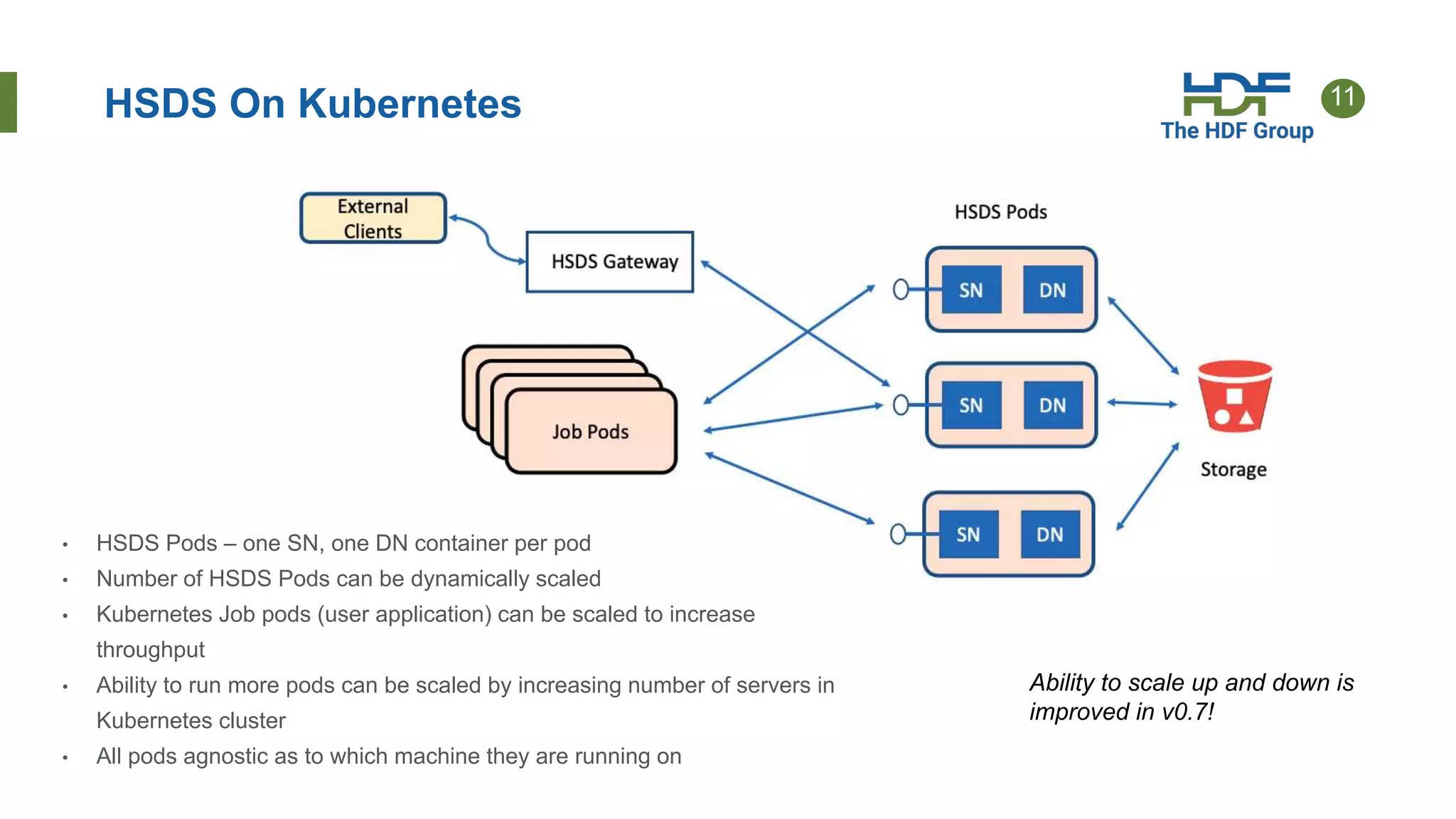
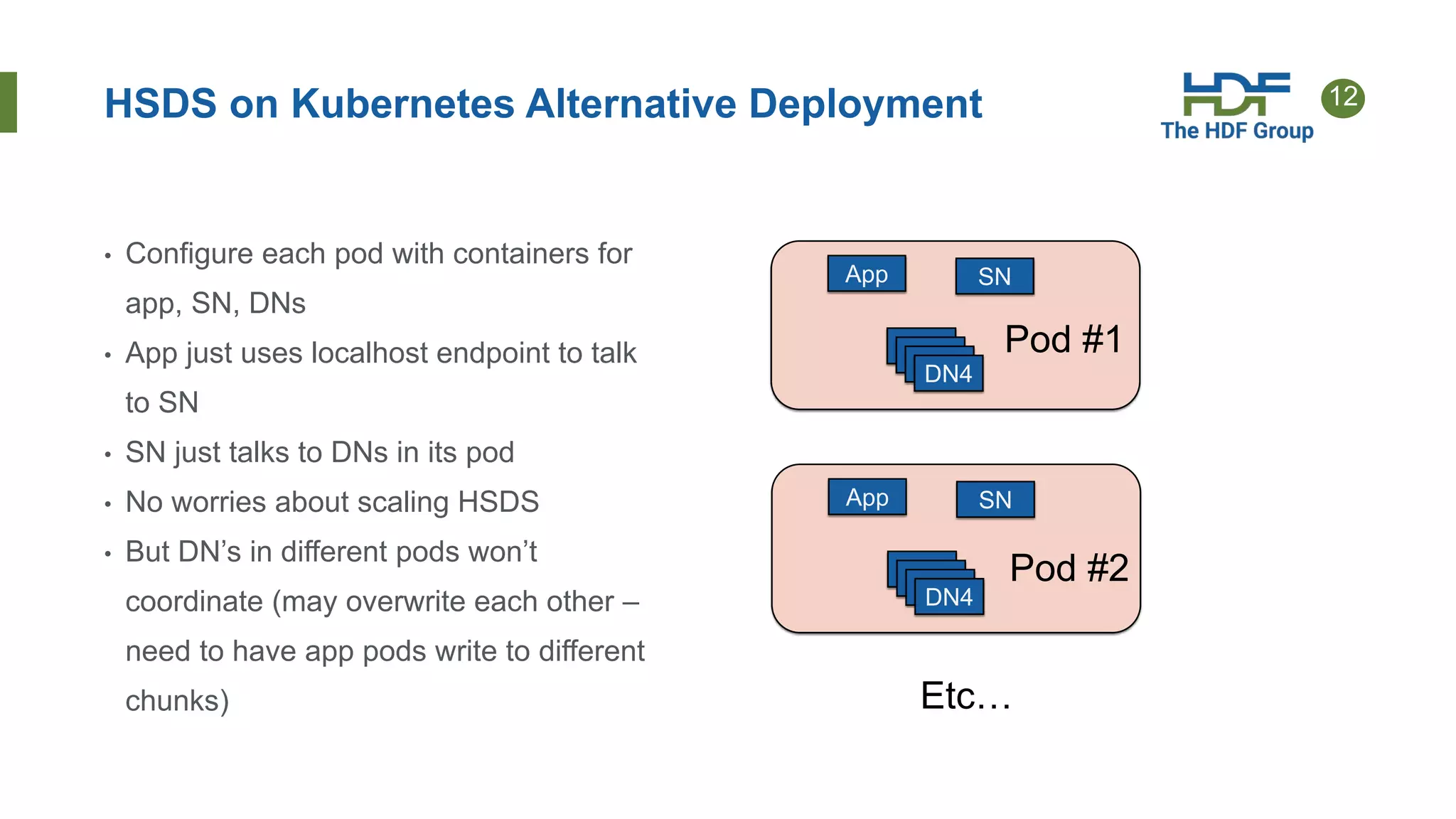
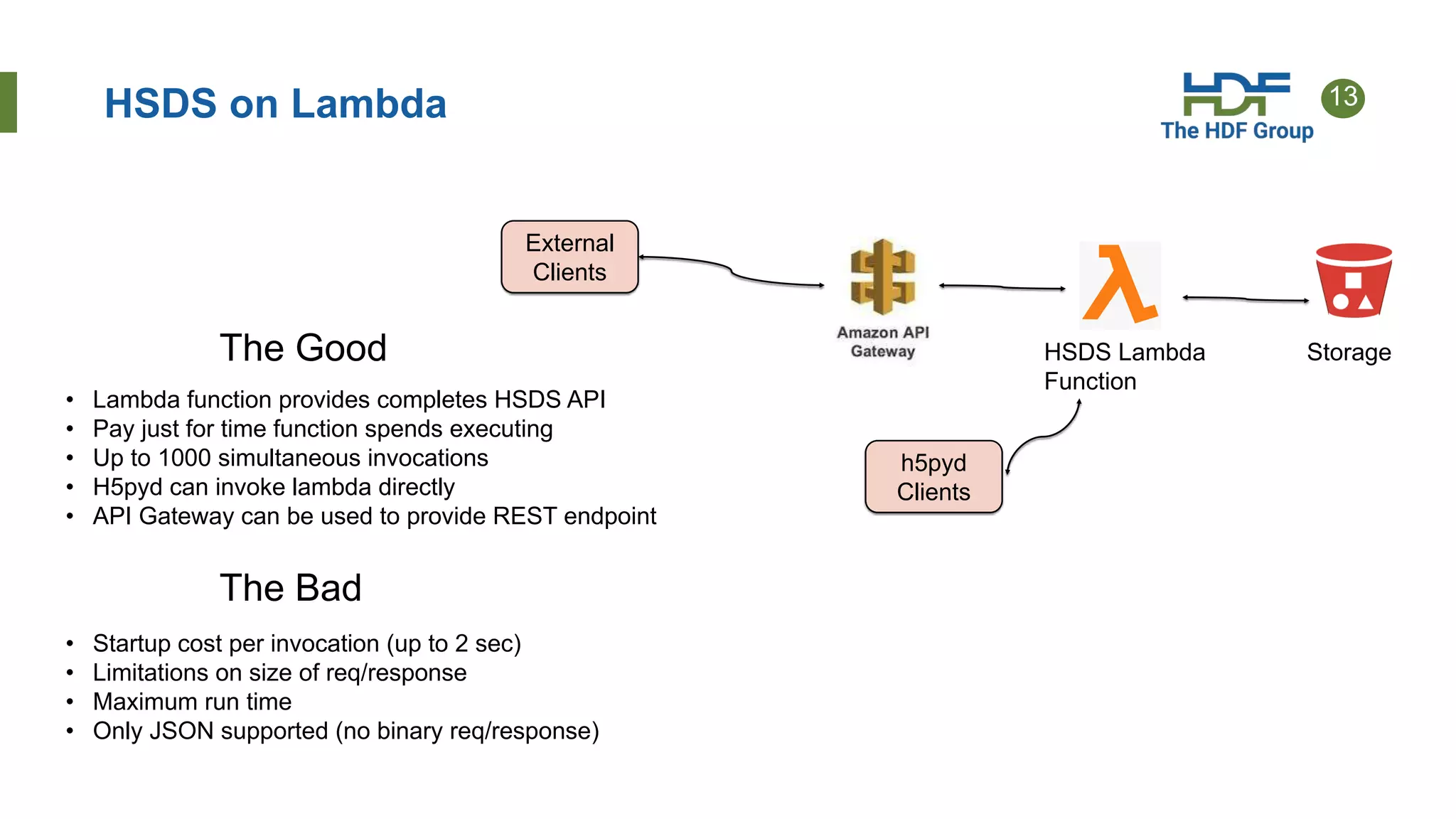




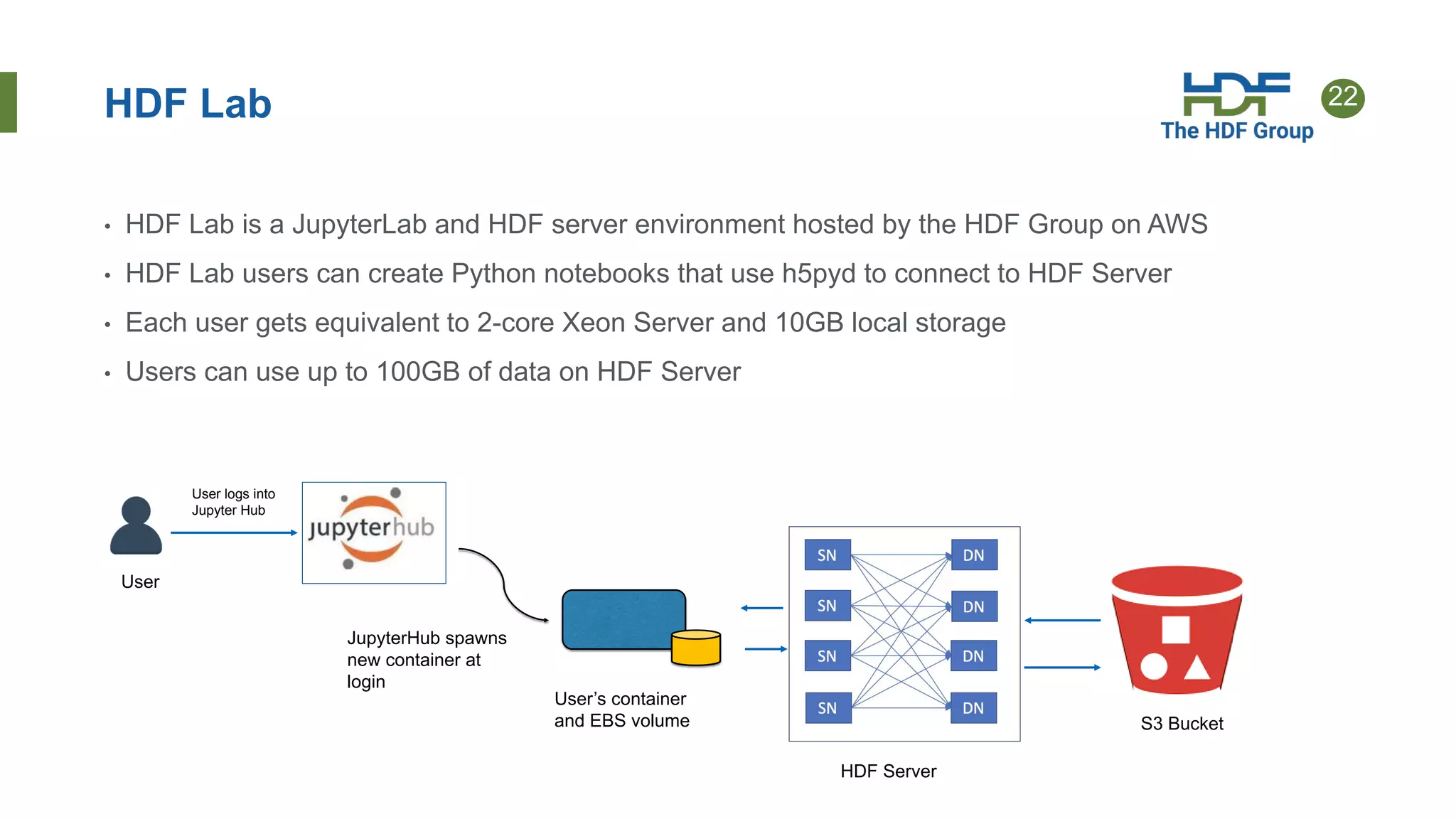

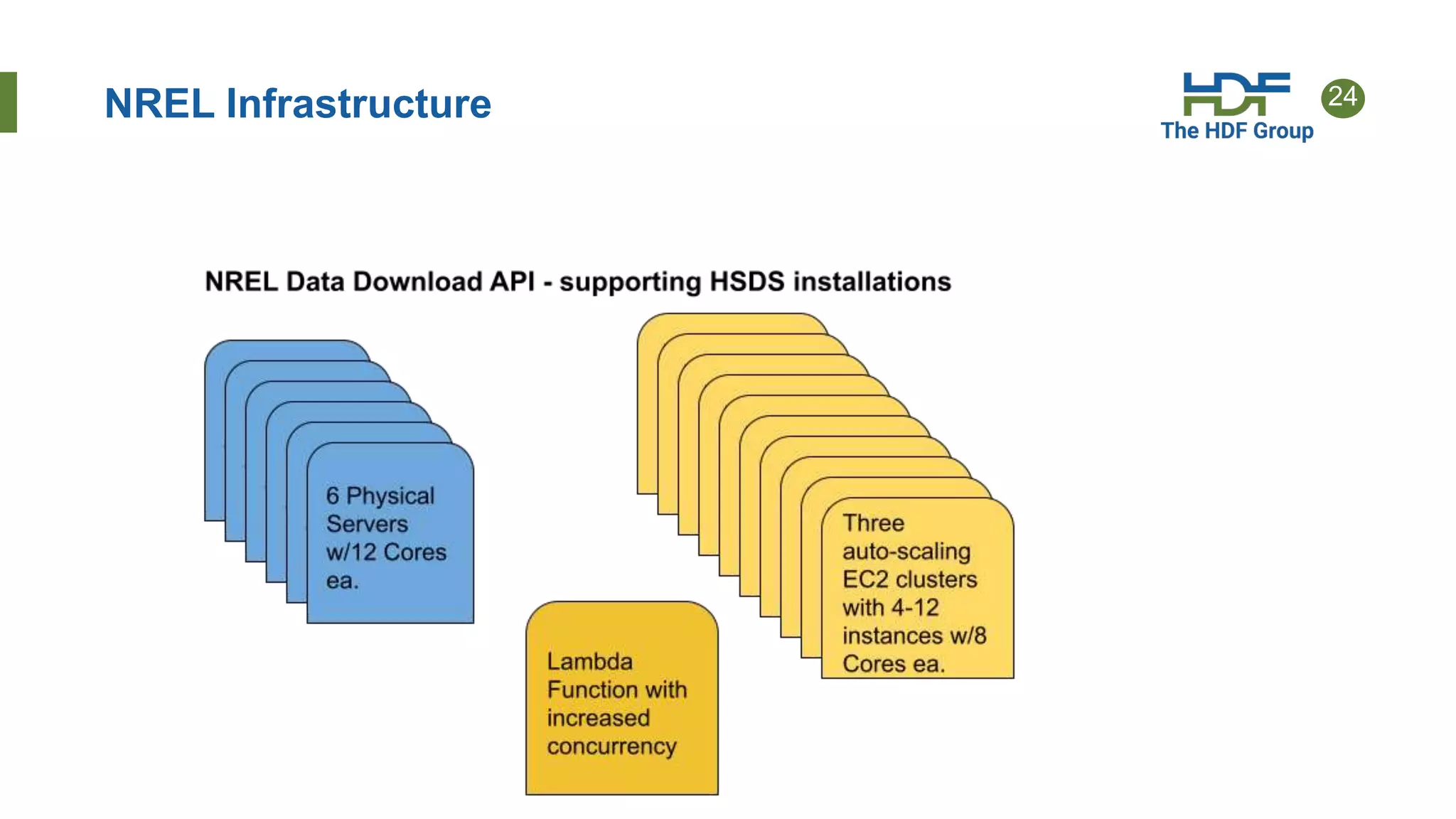
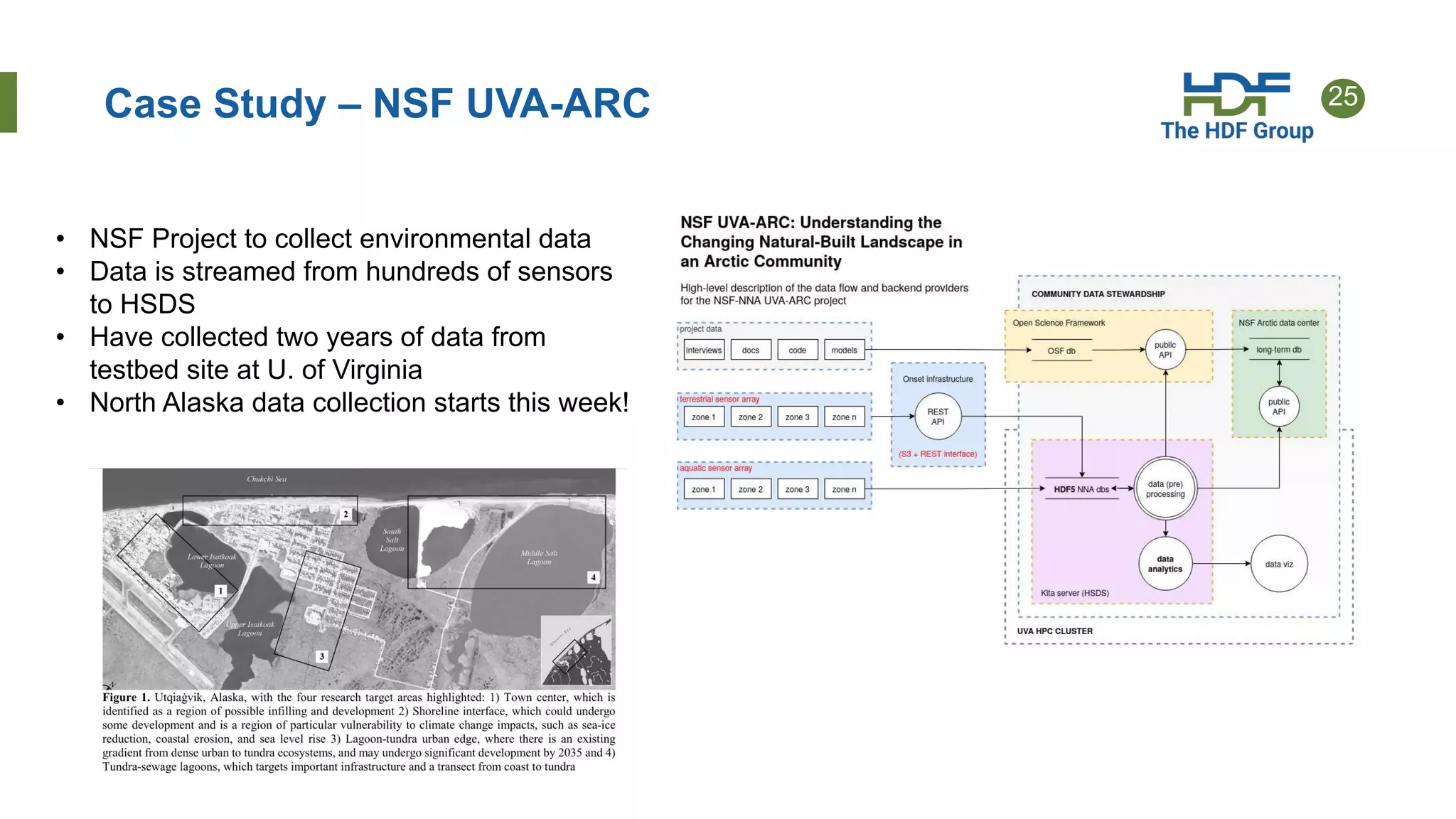

This document provides an overview of HSDS (HDF Server and Data Service), which allows HDF5 files to be stored and accessed from the cloud. Key points include: - HSDS maps HDF5 objects like datasets and groups to individual cloud storage objects for scalability and parallelism. - Features include streaming support, fancy indexing for complex queries, and caching for improved performance. - HSDS can be deployed on Docker, Kubernetes, or AWS Lambda depending on needs. - Case studies show HSDS is used by organizations like NREL and NSF to make petabytes of scientific data publicly accessible in the cloud.



































































