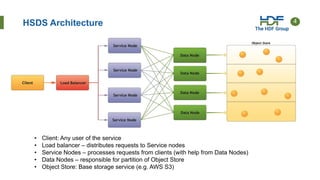
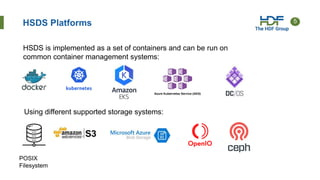
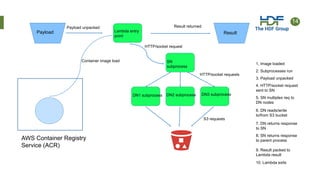
Download to read offline













![16
HSDS Lambda Performance Results
• Simple performance test:
• (10000, 1602, 2976) dimension data, hyperslab selection of [:, x, y]
• 400 chunks access (~1GB data)
• 10,000 elements returned (~39KB)
• Results
• Server HSDS w/ 4 nodes: 5.04s, 204 MB/s
• Lambda HSDS w/ 1GB mem: 25.6s (cold), 40 MB/s
• Lambda HSDS w/ 1GB mem: 18.1s (warm), 56 MB/s
• Lambda HSDS w/ 10GB mem: 10.2s (warm), 102 MB/s](https://image.slidesharecdn.com/jxr-210802144851/85/HDF-for-the-Cloud-Serverless-HDF-16-320.jpg)


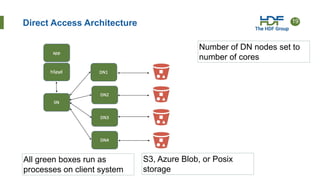




HSDS provides HDF as a service through a REST API that can scale across nodes. New releases will enable serverless operation using AWS Lambda or direct client access without a server. This allows HDF data to be accessed remotely without managing servers. HSDS stores each HDF object separately, making it compatible with cloud object storage. Performance on AWS Lambda is slower than a dedicated server but has no management overhead. Direct client access has better performance but limits collaboration between clients.











































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)





![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

