Download to read offline


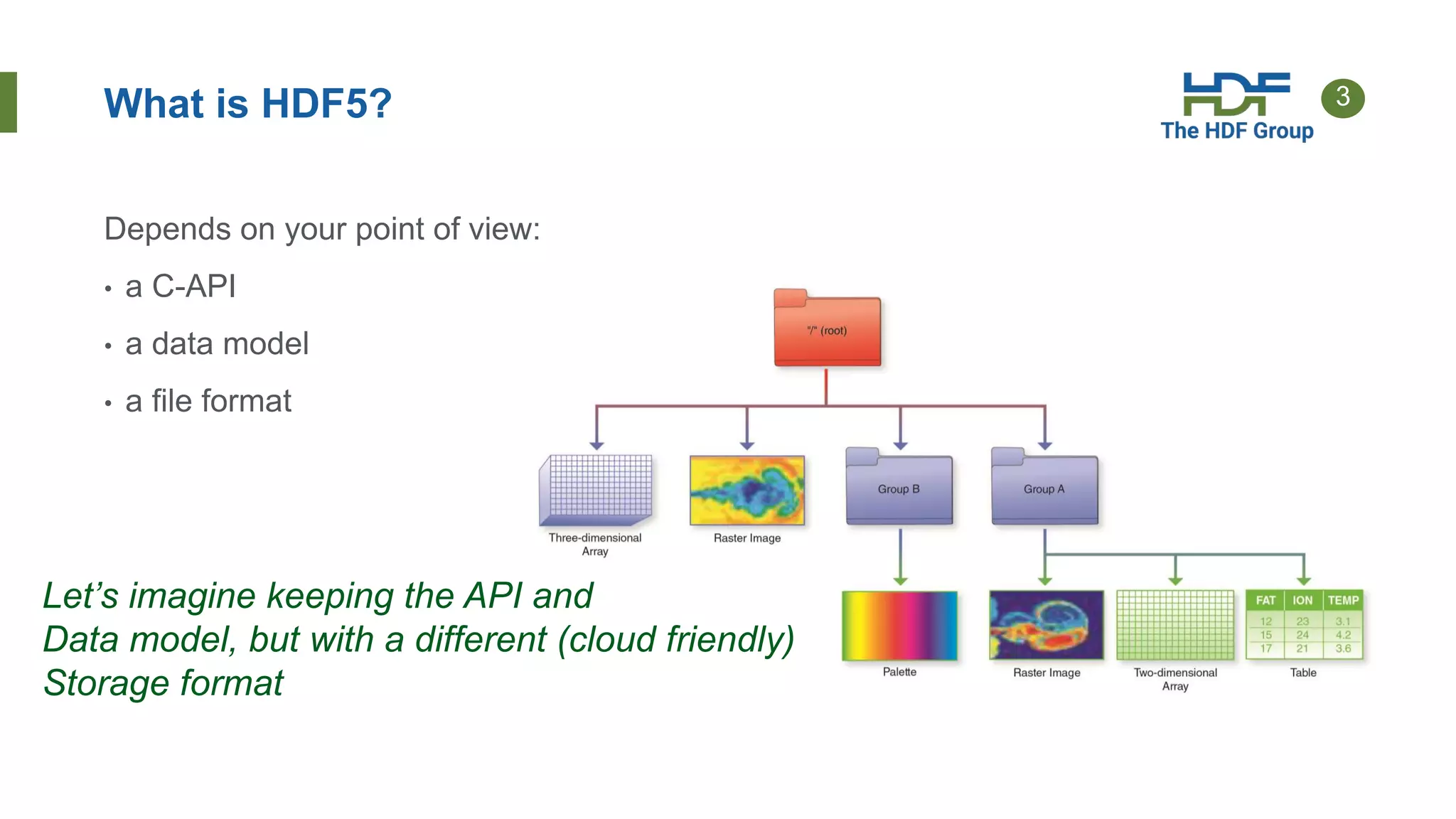
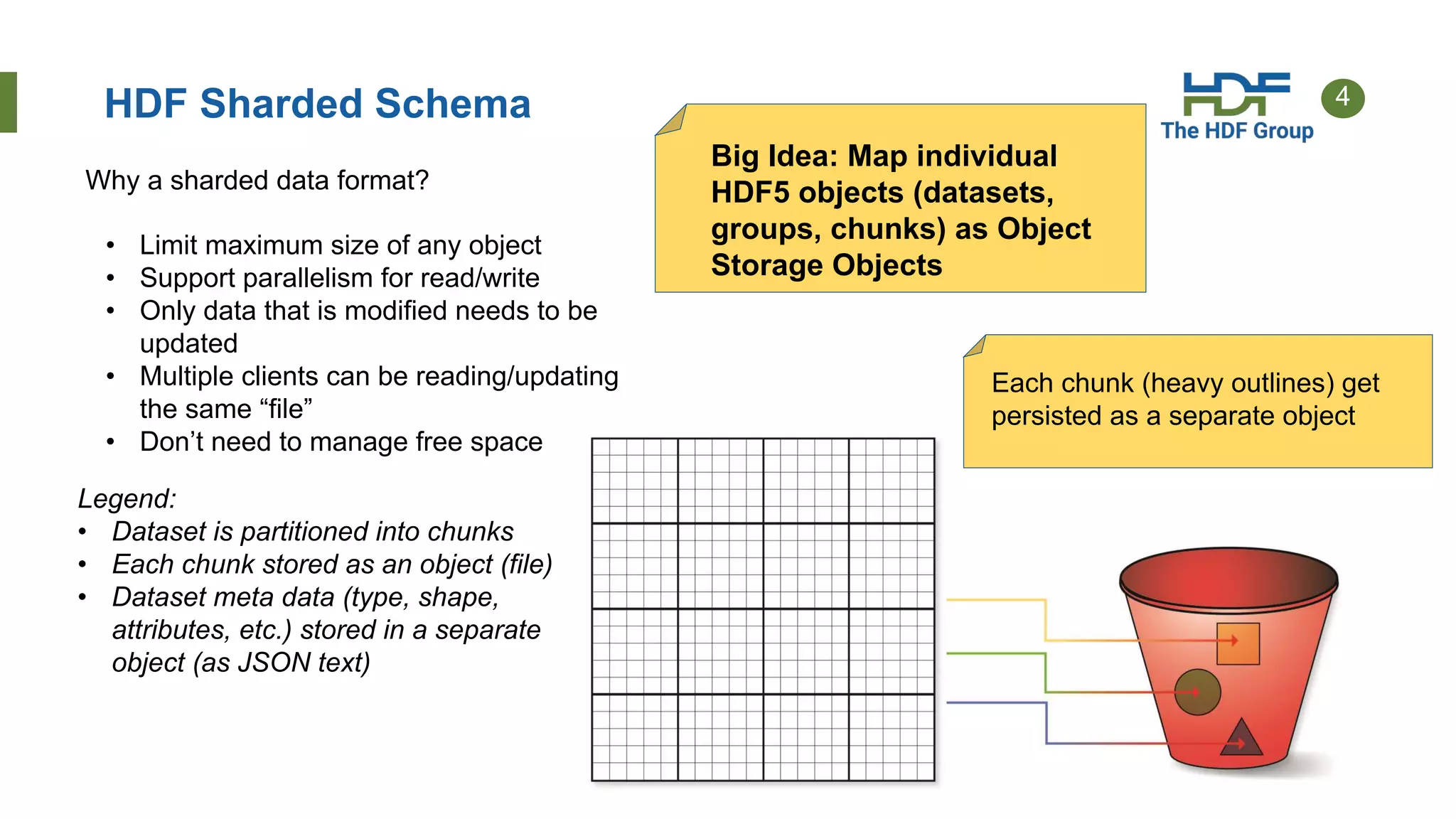



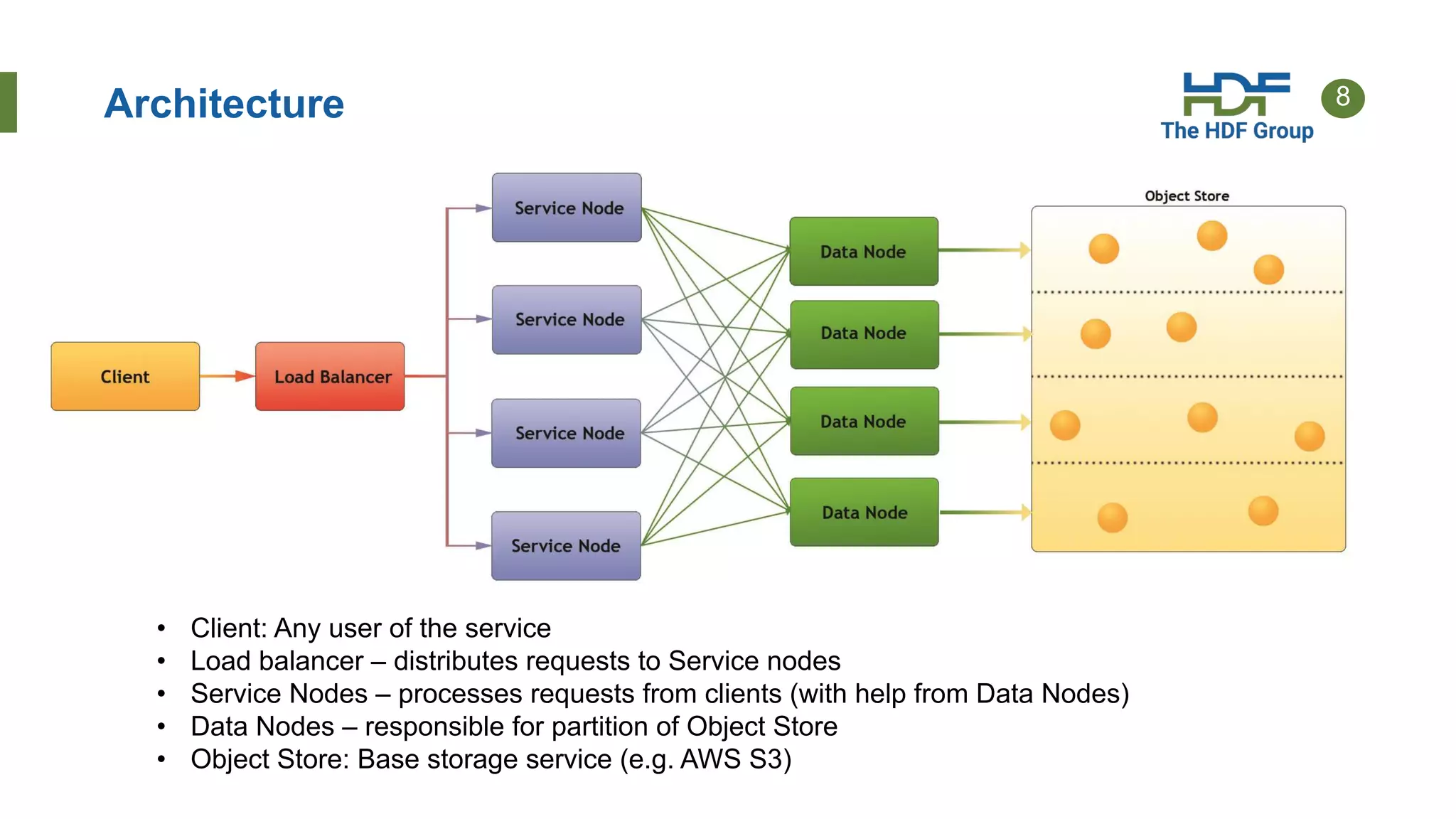

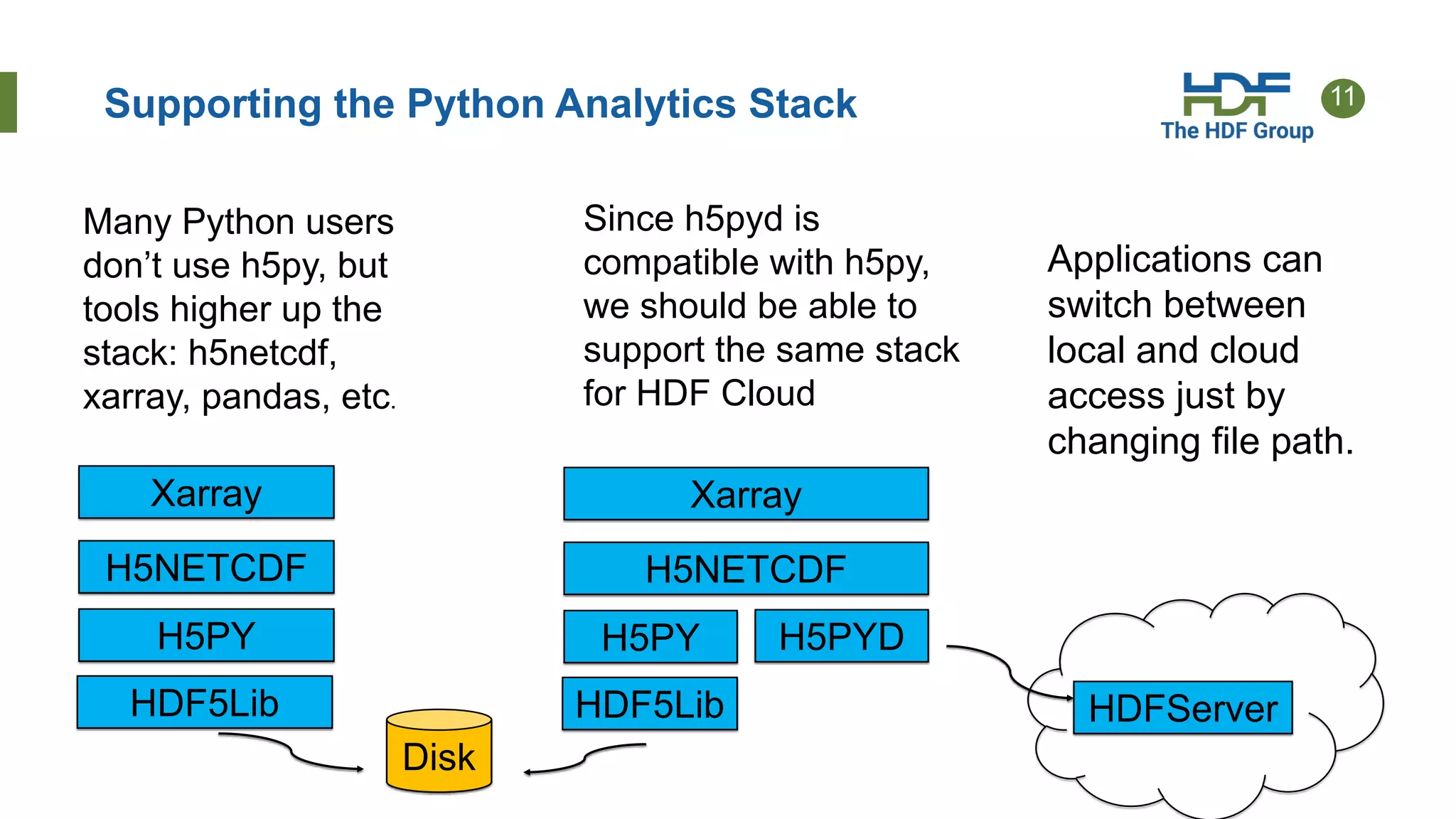




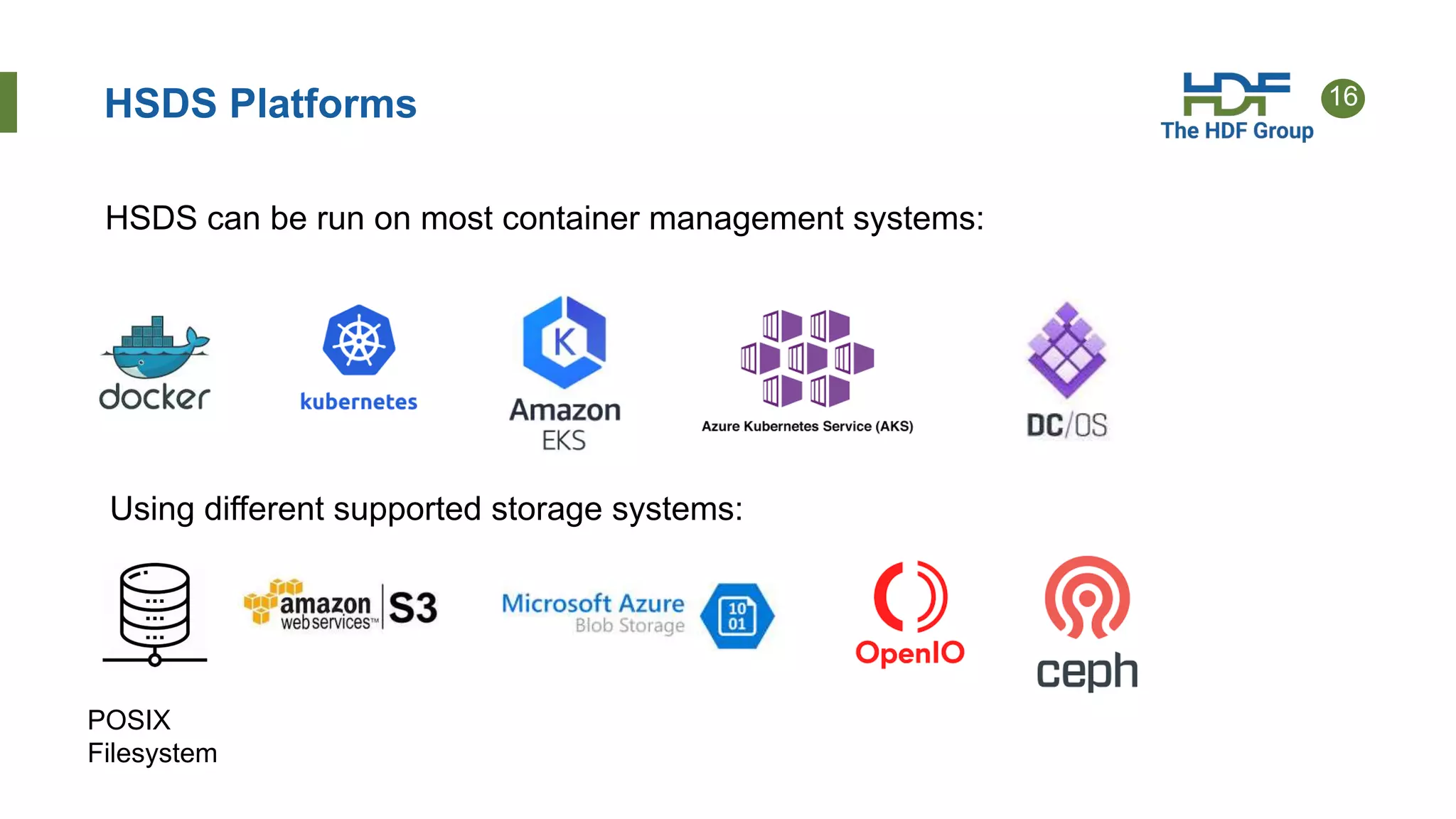

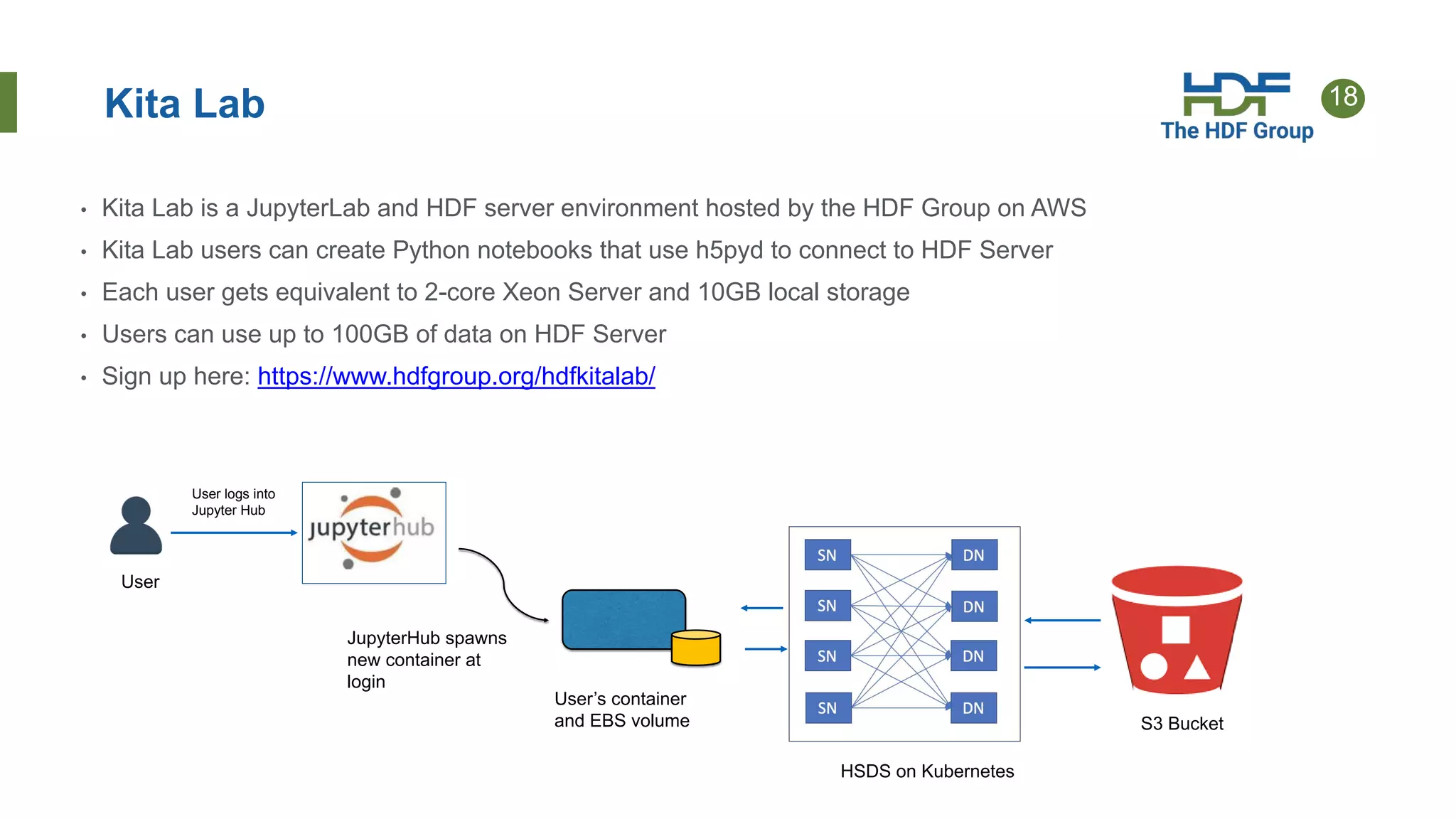


The document discusses HDF for the cloud, including new features of the HDF Server and what's next. Key points: - HDF Server uses a "sharded schema" that maps HDF5 objects to individual storage objects, allowing parallel access and updates without transferring entire files. - Implementations include HSDS software that uses the sharded schema with an API and SDKs for different languages like h5pyd for Python. - New features of HSDS 0.6 include support for POSIX, Azure, AWS Lambda, and role-based access control. - Future work includes direct access to storage without a server intermediary for some use cases.
















































































