Downloaded 38 times















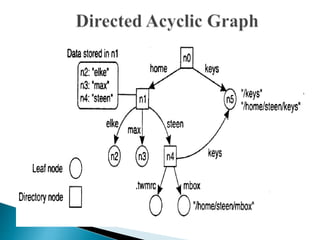













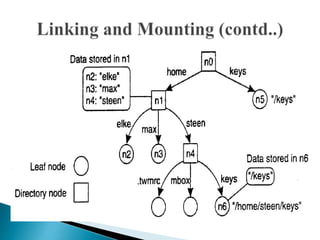





In distributed systems, names are used to identify entities and can refer to various resources like hosts and files, while an access point is defined by an address. A unique identifier for an entity is preferred over using addresses, as addresses can frequently change, making them unreliable for identification. Name resolution processes convert string representations into meaningful access paths in a naming graph, utilizing mechanisms such as aliases and directory nodes to efficiently manage and retrieve information.



































































