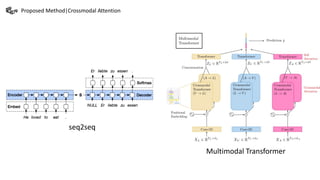
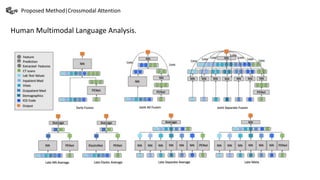
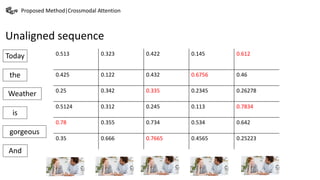
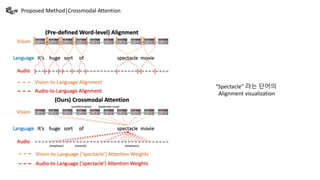
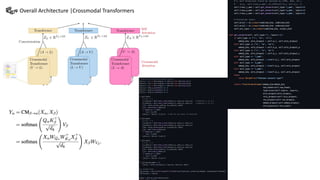
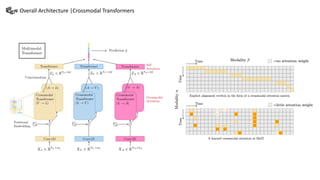
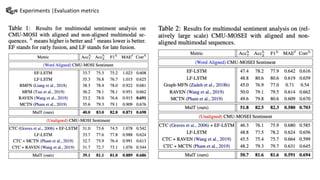
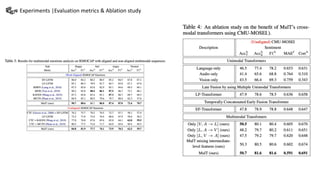
This document summarizes a presentation on multimodal language analysis using multimodal transformers for unaligned multimodal language sequences. It discusses how multimodal transformers can analyze text, vision, and audio inputs simultaneously using crossmodal attention. The proposed method is shown to generate embeddings that capture the relationships between different input modalities without strict alignment between the sequences. Various experiments are conducted to evaluate the model using different metrics and ablation studies.
































![[2023] Cut and Learn for Unsupervised Object Detection and Instance Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/cutler2-230408040939-266c2db0-thumbnail.jpg?width=640&height=640&fit=bounds)























