Download to read offline





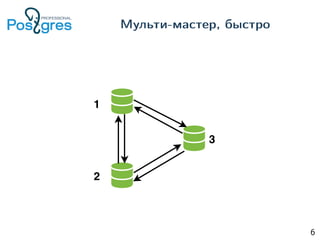






















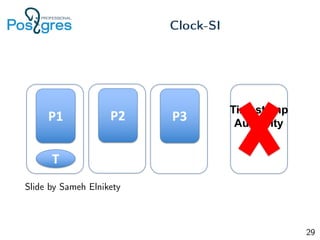

































Документ рассматривает реализацию мульти-мастер репликации в PostgreSQL, акцентируя внимание на транзакциях, уровнях изоляции и распределённых транзакциях. Описываются особенности работы с версиями баз данных, подходы к атомарности, обработке конфликтов и управления состоянием транзакций. Также представлены практические аспекты настройки и тестирования системы, включая вопросы, касающиеся совместимости и производительности.





















































