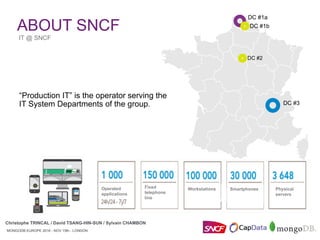
Download as PDF, PPTX





![MONGODB EUROPE 2016 - NOV 15th - LONDON
Christophe TRINCAL / David TSANG-HIN-SUN / Sylvain CHAMBON
MONGODB EUROPE 2016 - NOV 15th - LONDON
r = requests.post(host +
"/api/public/v1.0/groups",
auth=HTTPDigestAuth(user, key),
headers=headers,
data=json.dumps(payload))
j = r.json()
group_id = j["id"]
agent_api_key = j["agentApiKey"]
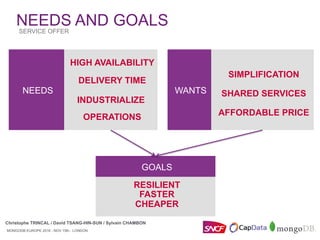
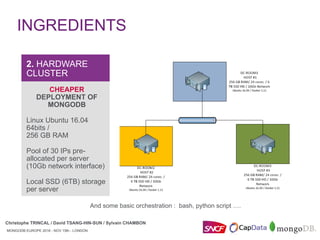
RECIPE & ORCHESTRATION
Christophe TRINCAL / David TSANG-HIN-SUN / Sylvain CHAMBON
Ops Manager API –
Create Group
Docker – Create Image
Capacity Planning](https://image.slidesharecdn.com/mongodbeurope2016-mongodbopsmanagerdockeratsncf-161117101134/85/MongoDB-Europe-2016-MongoDB-Ops-Manager-Docker-at-SNCF-17-320.jpg)



![MONGODB EUROPE 2016 - NOV 15th - LONDON
Christophe TRINCAL / David TSANG-HIN-SUN / Sylvain CHAMBON
MONGODB EUROPE 2016 - NOV 15th - LONDON
Ops Manager Backup API
Ops Manager Alerts API
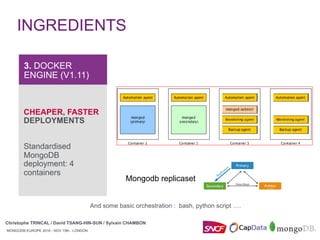
create_replicaset.py –help
-group group_name
-size container’s size S/M/XL
–name replicaset-name
-nb nodes (3/3a/5/5a)
-file passwordfile.csv
-backup policy
-alerting policy
-env prod/preprod
-version 3.2.10
-dryrun (reporting only)
-help This help message
"replicaSets": [
{
"_id": "testReplicaSet",
"members": [
{
"_id": 0,
"arbiterOnly": false,
"hidden": false,
"host": "testReplicaSet_0",
"priority": 10,
"slaveDelay": 0,
"votes": 1
},
{
"_id": 1,
"arbiterOnly": false,
"hidden": false,
"host": "testReplicaSet_1",
"priority": 1,
"slaveDelay": 0,
"votes": 1
},
{
"_id": 2,
"arbiterOnly": true,
"hidden": false,
"host": "testReplicaSet_2",
"priority": 1,
"slaveDelay": 0,
"votes": 1
}
]
}
Ops Manager
Automation API
RECIPE & ORCHESTRATION
Christophe TRINCAL / David TSANG-HIN-SUN / Sylvain CHAMBON](https://image.slidesharecdn.com/mongodbeurope2016-mongodbopsmanagerdockeratsncf-161117101134/85/MongoDB-Europe-2016-MongoDB-Ops-Manager-Docker-at-SNCF-22-320.jpg)

![MONGODB EUROPE 2016 - NOV 15th - LONDON
Christophe TRINCAL / David TSANG-HIN-SUN / Sylvain CHAMBON
MONGODB EUROPE 2016 - NOV 15th - LONDON
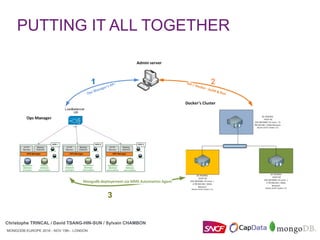
Ops Manager Backup API
Ops Manager Alerts API
Ops Manager Automation API
{
"eventTypeName": "MONITORING_AGENT_DOWN",
"groupId": "GROUP-ID",
"notifications": [
{
"delayMin": 0,
"emailEnabled": true,
"intervalMin": 60,
"smsEnabled": false,
"typeName": "GROUP"
}
],
"typeName": "AGENT",
}
RECIPE & ORCHESTRATION
Christophe TRINCAL / David TSANG-HIN-SUN / Sylvain CHAMBON](https://image.slidesharecdn.com/mongodbeurope2016-mongodbopsmanagerdockeratsncf-161117101134/85/MongoDB-Europe-2016-MongoDB-Ops-Manager-Docker-at-SNCF-24-320.jpg)




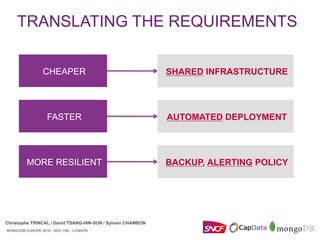
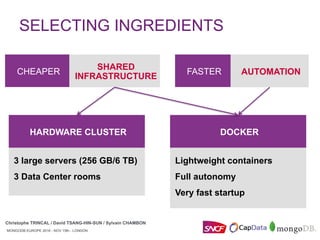
The document discusses how SNCF deployed MongoDB replicasets using Docker and MongoDB Ops Manager. It describes combining these tools to create replicasets faster and more reliably. Specific steps included using Ops Manager's API to create groups and policies for backups and alerts. Docker was used to standardize MongoDB deployments across containers and automate operations like starting containers and mounting volumes. The overall goal was to make MongoDB deployments cheaper, faster, and more resilient through automation.




![[QCon.ai 2019] People You May Know: Fast Recommendations Over Massive Data](https://cdn.slidesharecdn.com/ss_thumbnails/qconaisf2019-pymk-190424130904-thumbnail.jpg?width=640&height=640&fit=bounds)






































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)


























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




