Downloaded 42 times






















![41
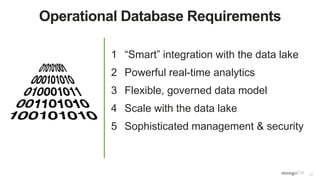
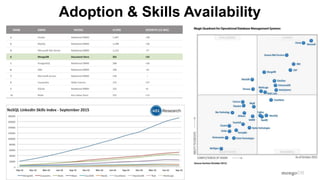
Handling Multi-Structured Data from the Data Lake
Flexible, Governed Data Model
{
first_name: ‘Paul’,
surname: ‘Miller’,
cell: 447557505611,
city: ‘London’,
location: [45.123,47.232],
Profession: [‘banking’, ‘finance’, ‘trader’],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
]
}
Fields can contain an array
of sub-documents
Typed field values
Fields can contain arrays
Number](https://image.slidesharecdn.com/operationaldatalakewebinar1-160615200554/85/Unlocking-Operational-Intelligence-from-the-Data-Lake-41-320.jpg)

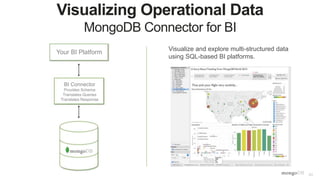

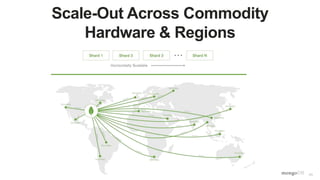


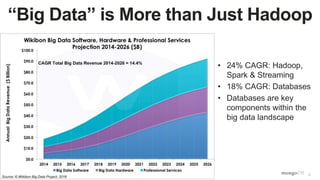
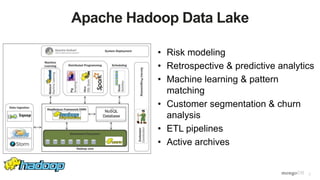
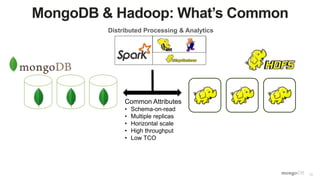
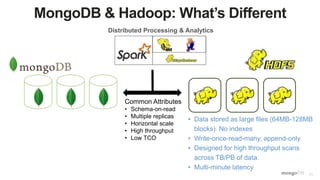
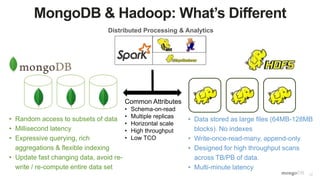
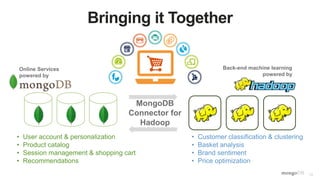
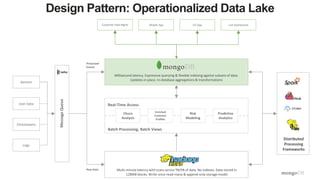
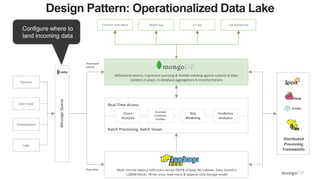
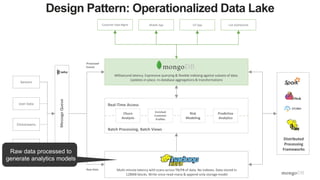
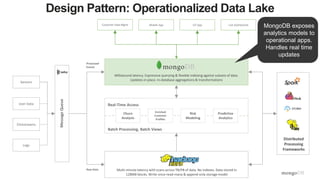
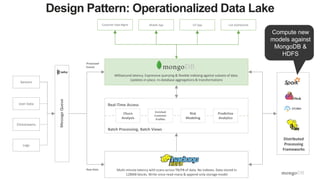
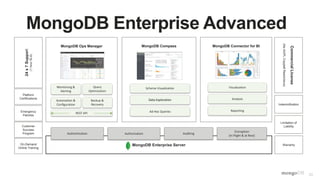
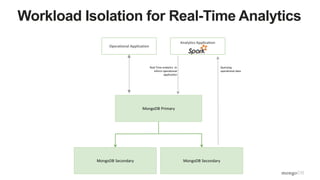
The document discusses unlocking operational intelligence from data lakes using MongoDB. It begins by describing how digital transformation is driving changes in data volume, velocity, and variety. It then discusses how MongoDB can help operationalize data lakes by providing real-time access and analytics on data stored in data lakes, while also integrating batch processing capabilities. The document provides an example reference architecture of how MongoDB can be used with a data lake (Hadoop) and stream processing framework (Kafka) to power operational applications and machine learning models with both real-time and batch data and analytics.











































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































