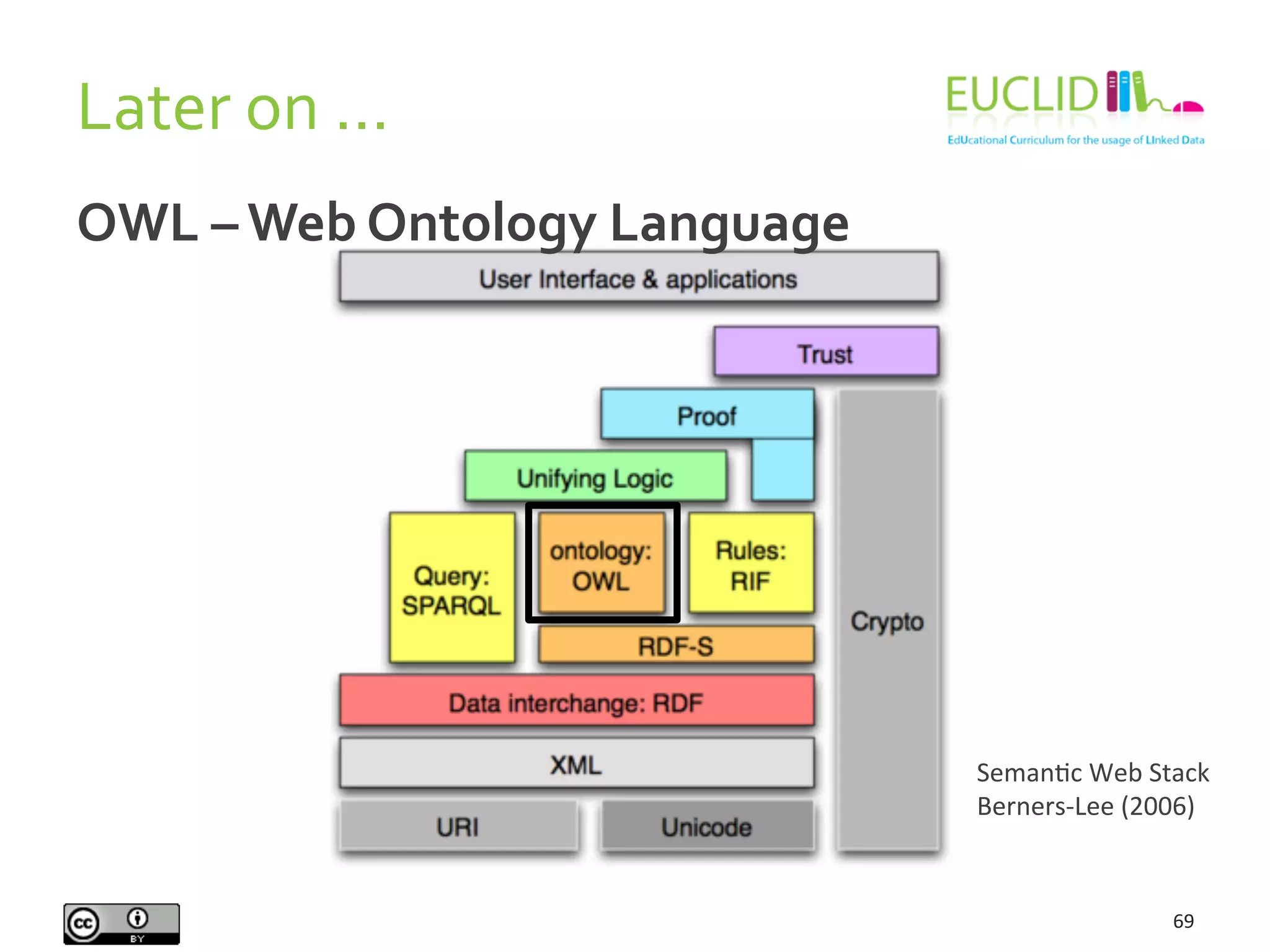
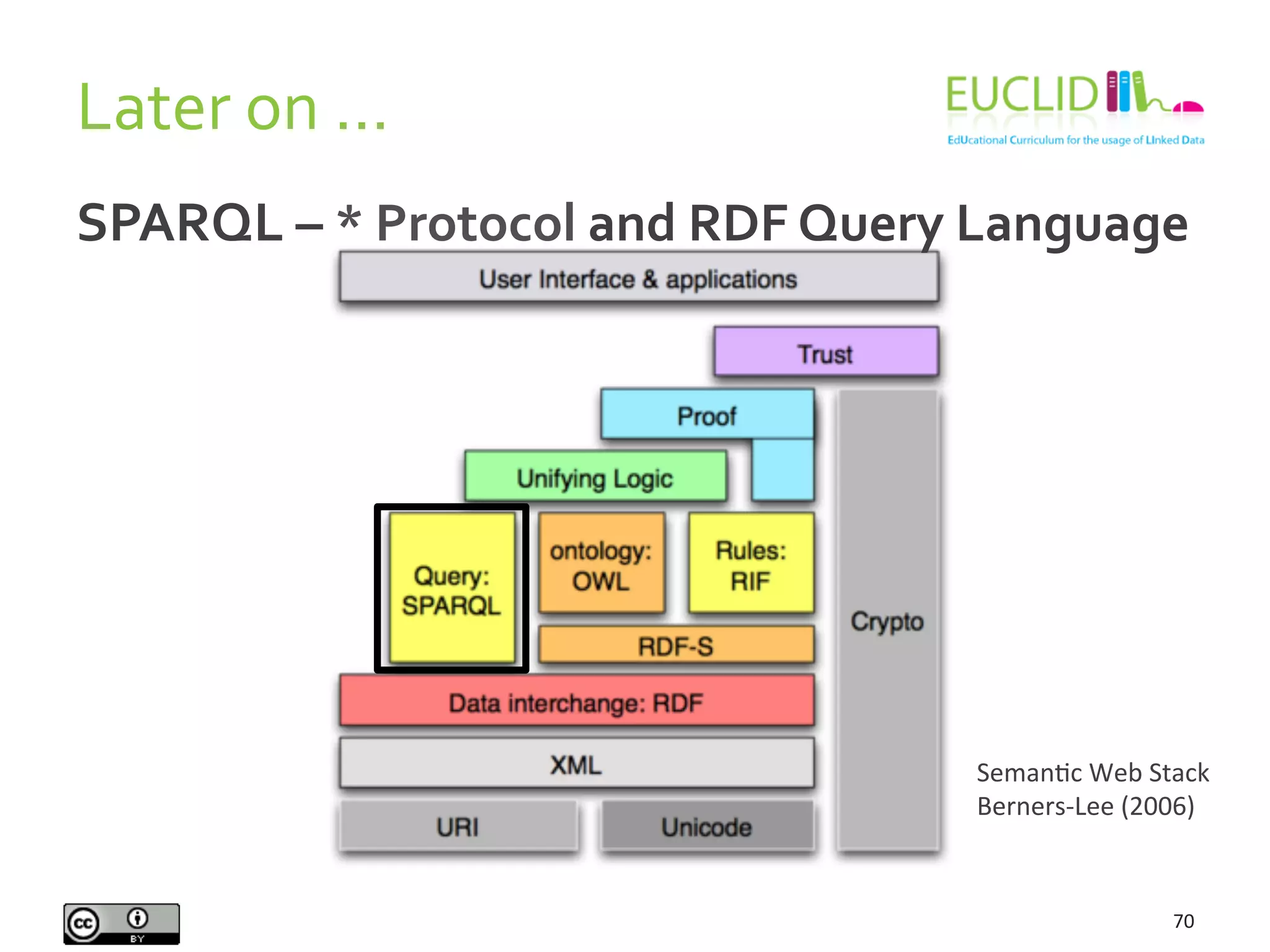
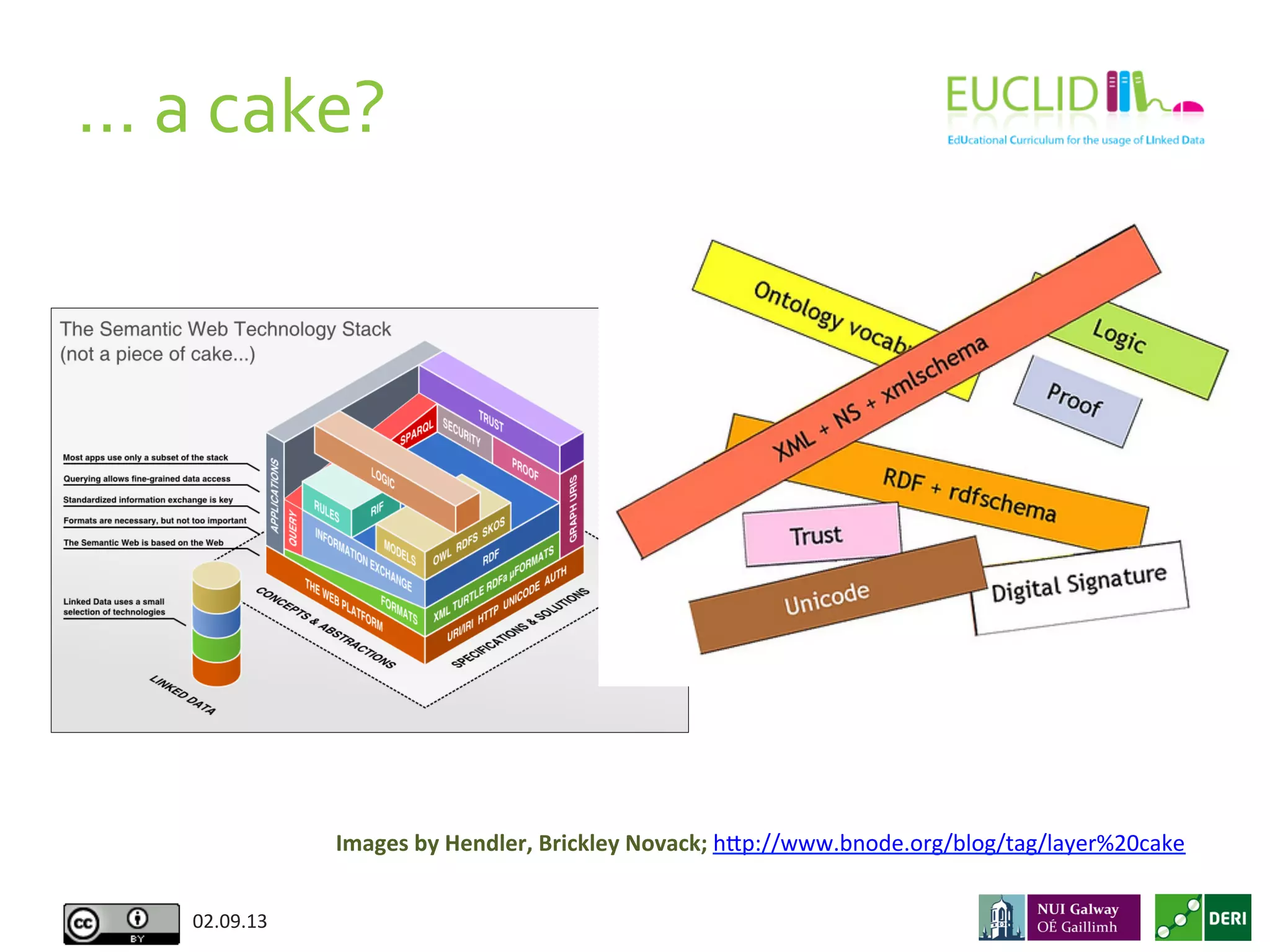
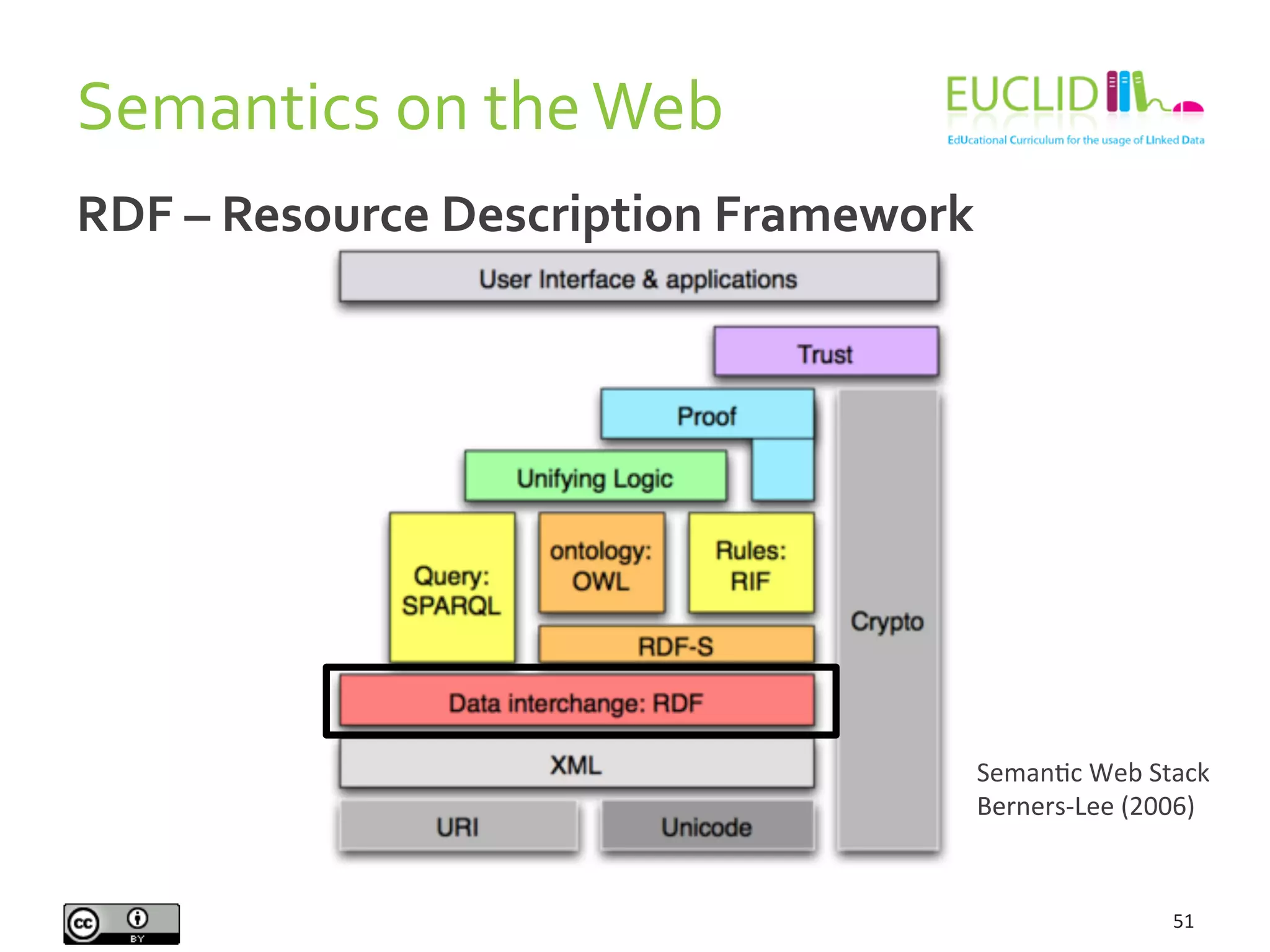
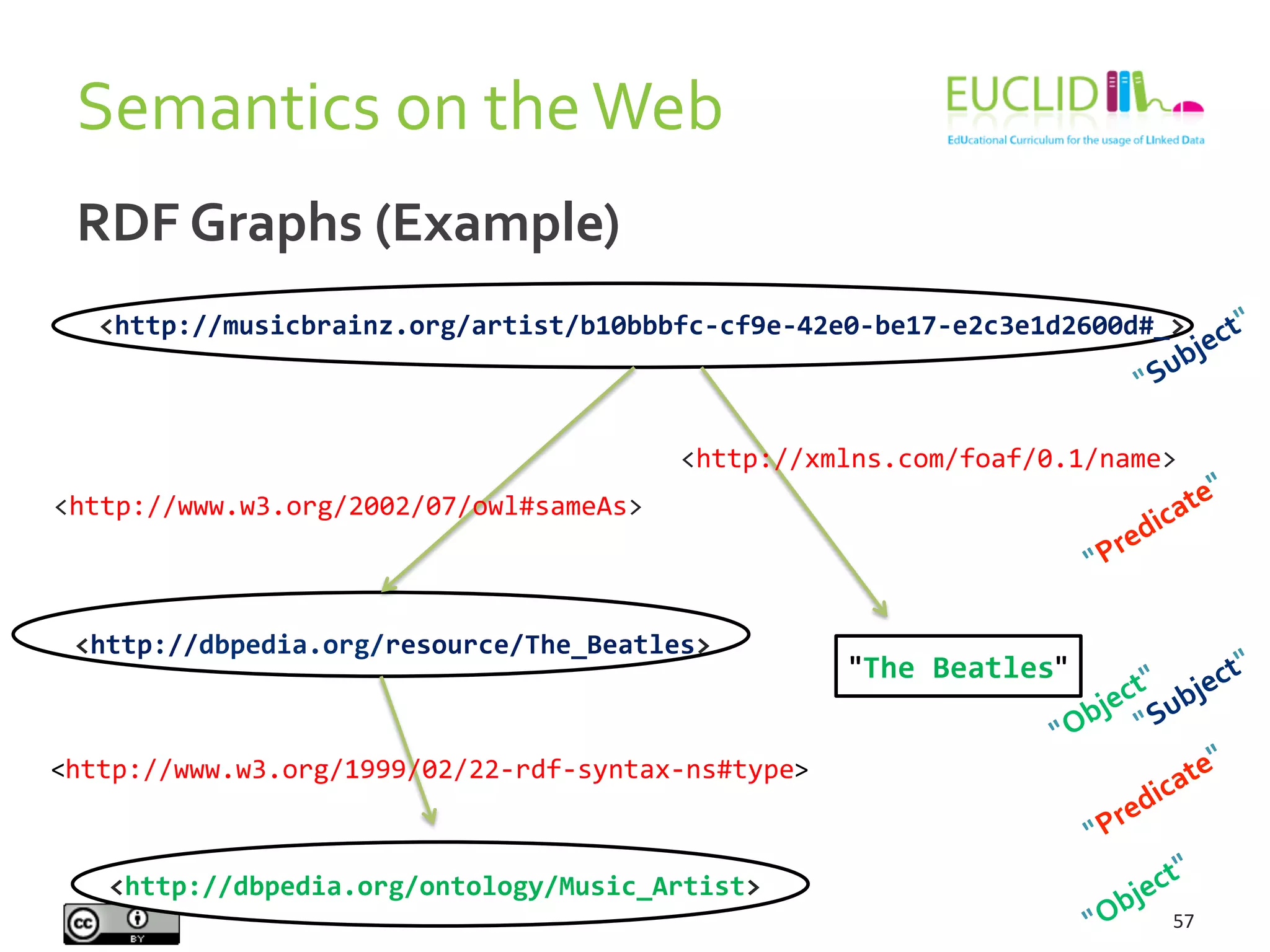
This document provides an introduction to the semantic web presented by Aidan Hogan. It begins with various definitions and explanations of what the semantic web is, including comparisons to a machine readable web, standards, ontologies, linked data, and naming everything. It then discusses why the semantic web is needed due to the growing amount of data being produced and the inability of humans alone to understand it all. Finally, it provides examples of how the semantic web could help solve problems by linking related data together from various sources.


































![Web
Technology
Basics
47
Uniform
Resource
Identifier
(URI)
• Compact
sequence
of
characters
that
idenHfies
an
abstract
or
physical
resource.
• Examples:
ldap://[2001:db8::7]/c=GB?objectClass?one
mailto:John.Doe@example.com
news:comp.infosystems.www.servers.unix
tel:+1-‐816-‐555-‐1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
http://dbpedia.org/resource/Karlsruhe](https://image.slidesharecdn.com/monday-module1-part1-20-28aidan-20hogan-29-130904112644-/75/ESWC-SS-2013-Monday-Tutorial-Aidan-Hogan-Intro-to-Semantic-Web-47-2048.jpg)






![Semantics
on
the
Web
58
RDF
Blank
Nodes
• RDF
graphs
can
also
contain
unidenHfied
resources,
called
blank
nodes:
• Blank
nodes
can
group
related
informaHon,
but
their
use
is
oden
discouraged
[]
<hOp://www.w3.org/
2003/01/geo/
wgs84_pos#Point>
<http://www.w3.org/1999/02/
22-‐rdf-‐syntax-‐ns#type>
<hAp://www.w3.org/
2003/01/geo/
wgs84_pos#lat>
<hAp://www.w3.org/
2003/01/geo/
wgs84_pos#long>
49.005
8.386](https://image.slidesharecdn.com/monday-module1-part1-20-28aidan-20hogan-29-130904112644-/75/ESWC-SS-2013-Monday-Tutorial-Aidan-Hogan-Intro-to-Semantic-Web-58-2048.jpg)