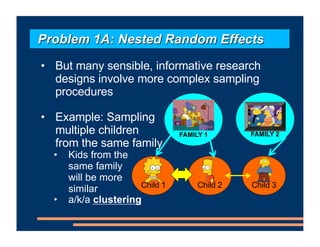
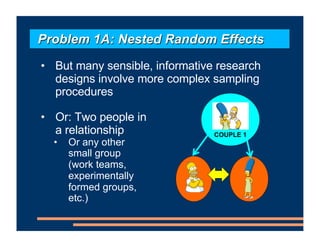
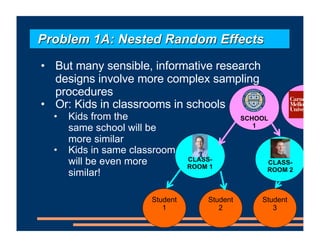
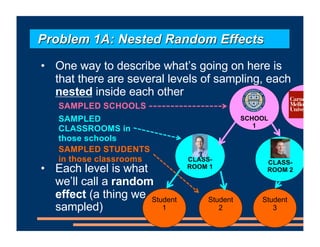
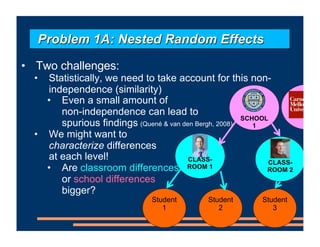
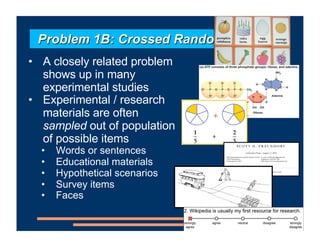
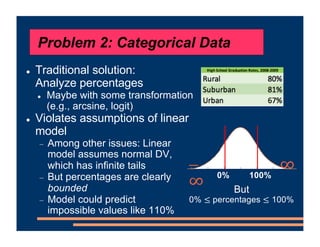
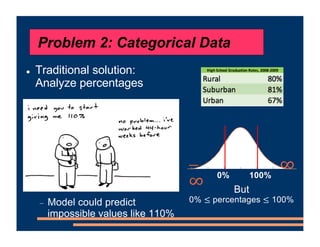
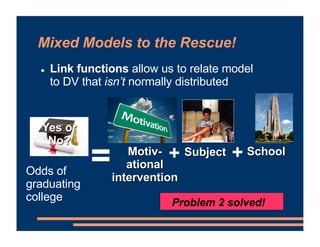
This document discusses an upcoming course on using mixed effects models in psychology. The course will cover applying mixed effects models to common research designs, fitting models in R, and addressing issues that arise. Mixed effects models are motivated by research designs involving multiple random effects, nested random effects, crossed random effects, categorical dependent variables, and continuous predictors. Accounting for these complex sampling procedures and non-independent observations is important for making valid statistical inferences.