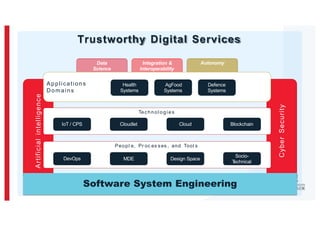
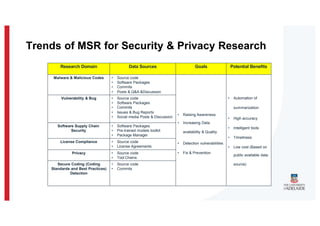
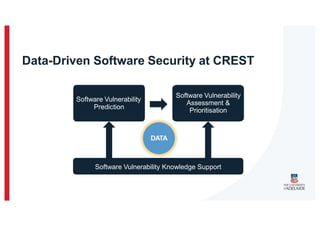
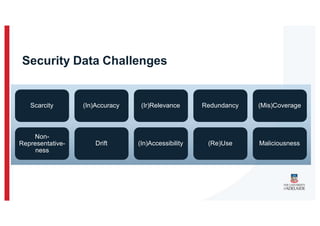
The document discusses the challenges and data quality issues in mining software repositories (MSR) for security purposes. It highlights the prevalence of vulnerabilities in software and the limitations of current frameworks like the Software Bill of Materials (SBOM) in ensuring security. Recommendations for addressing data-related challenges, such as improving data collection and sharing practices, are also provided.



















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)










