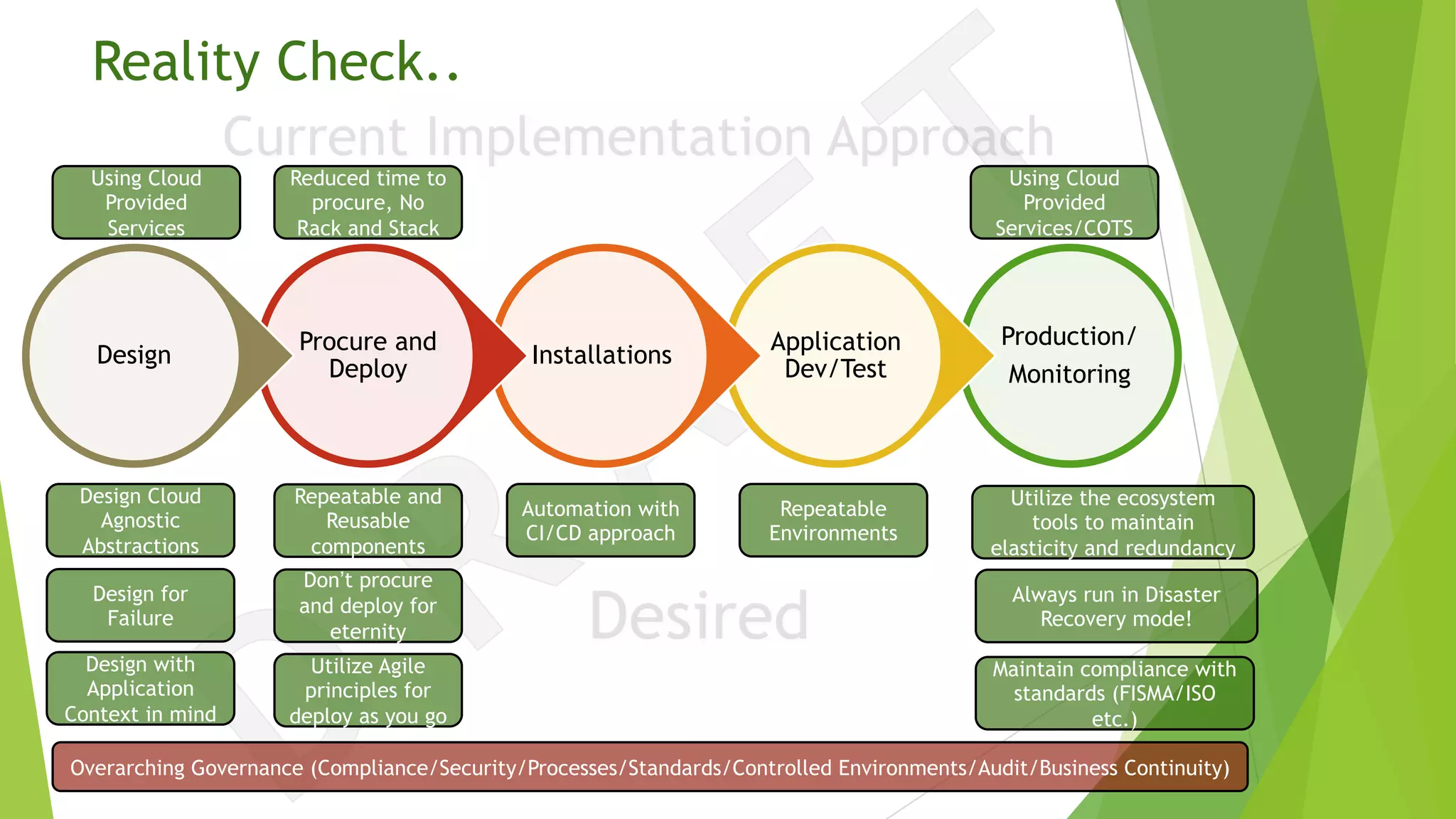
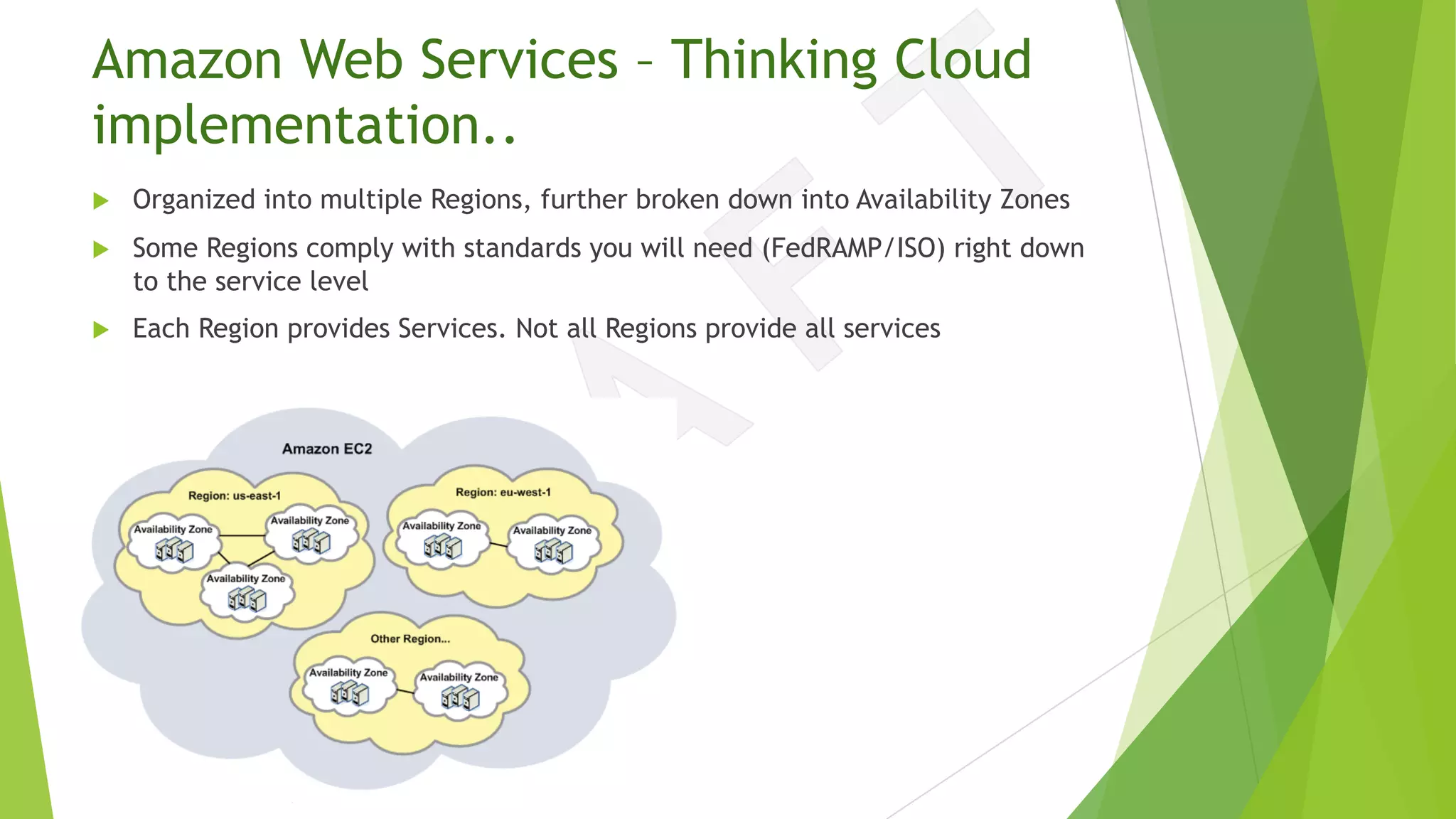
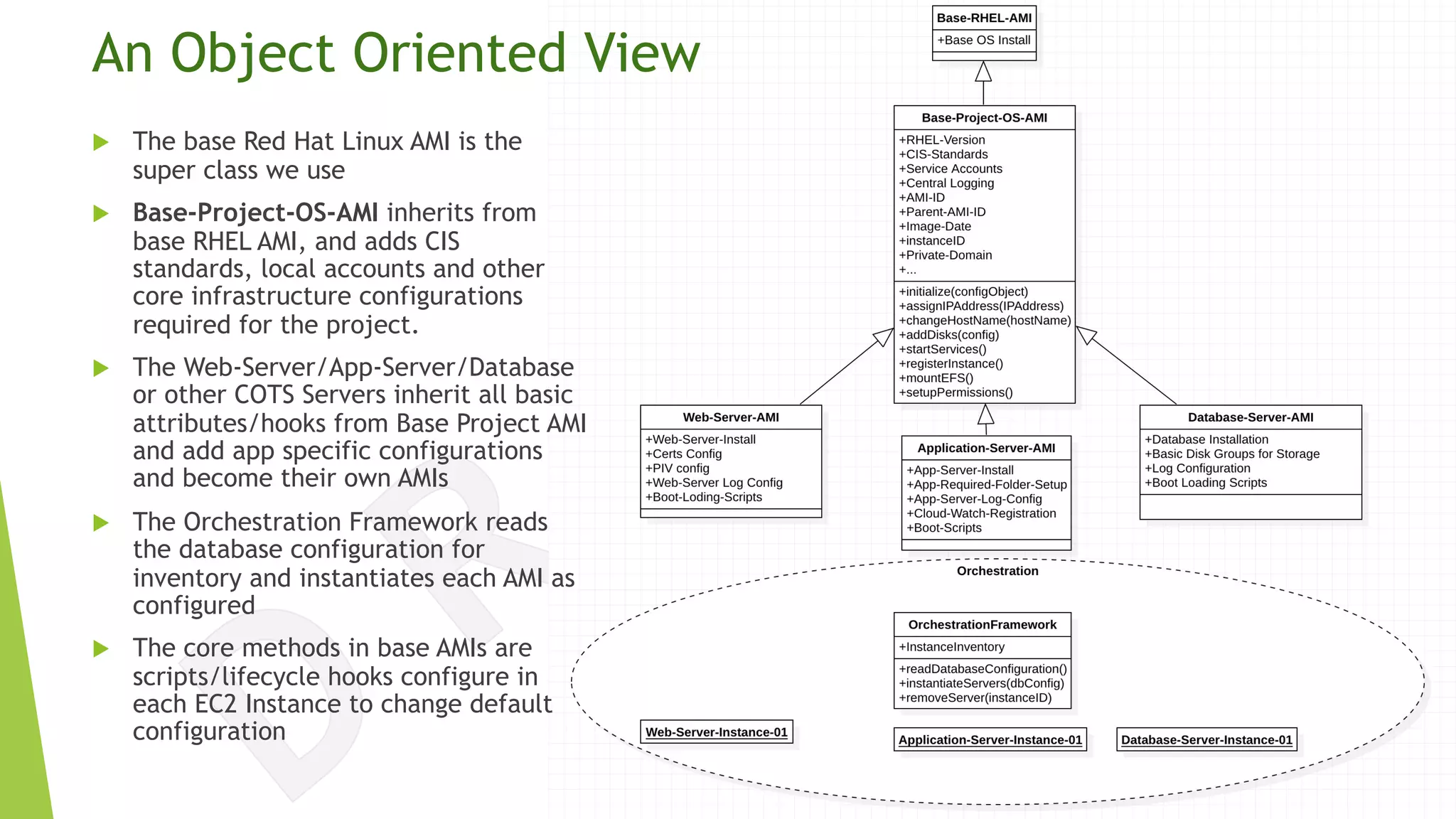
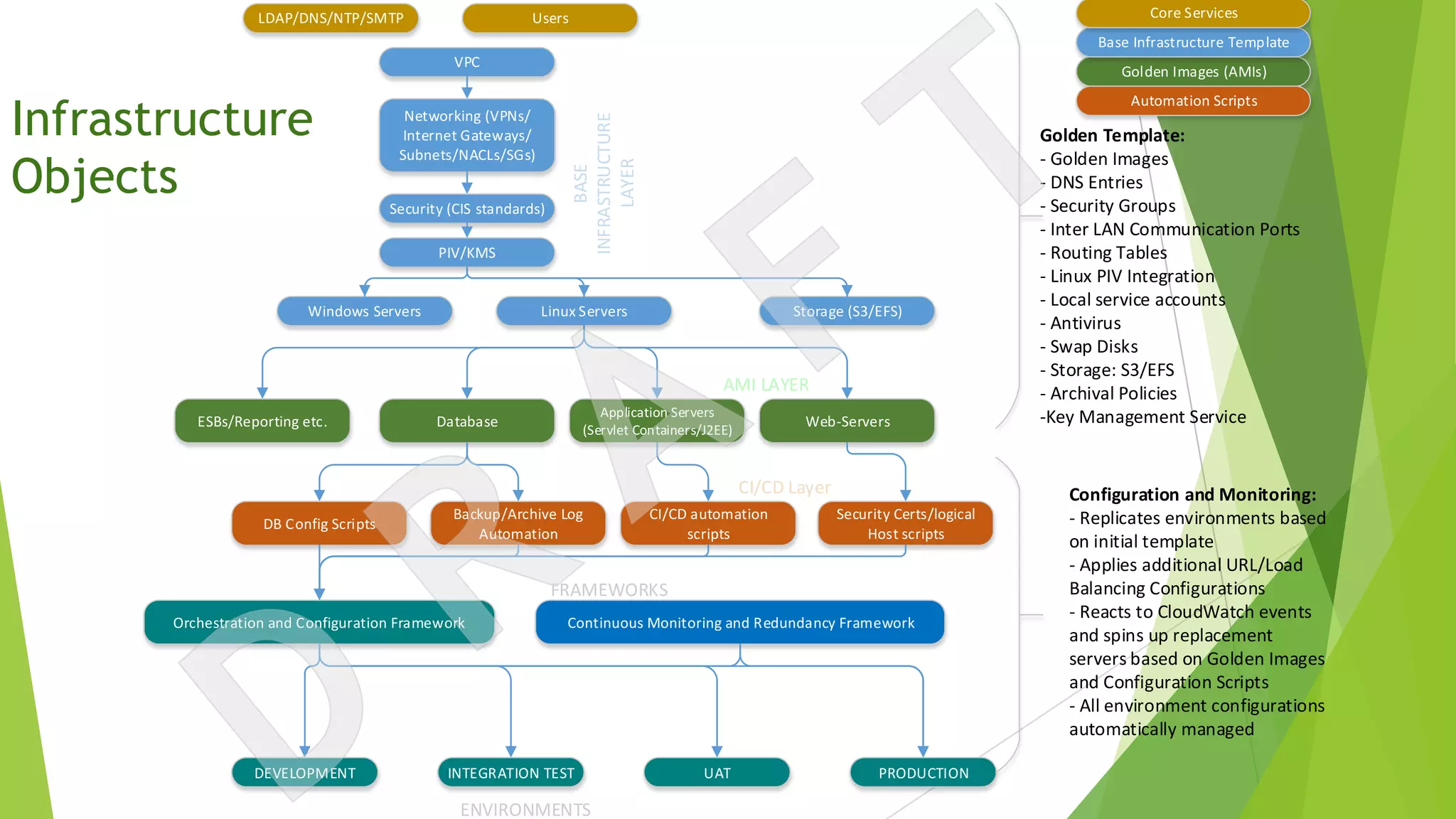
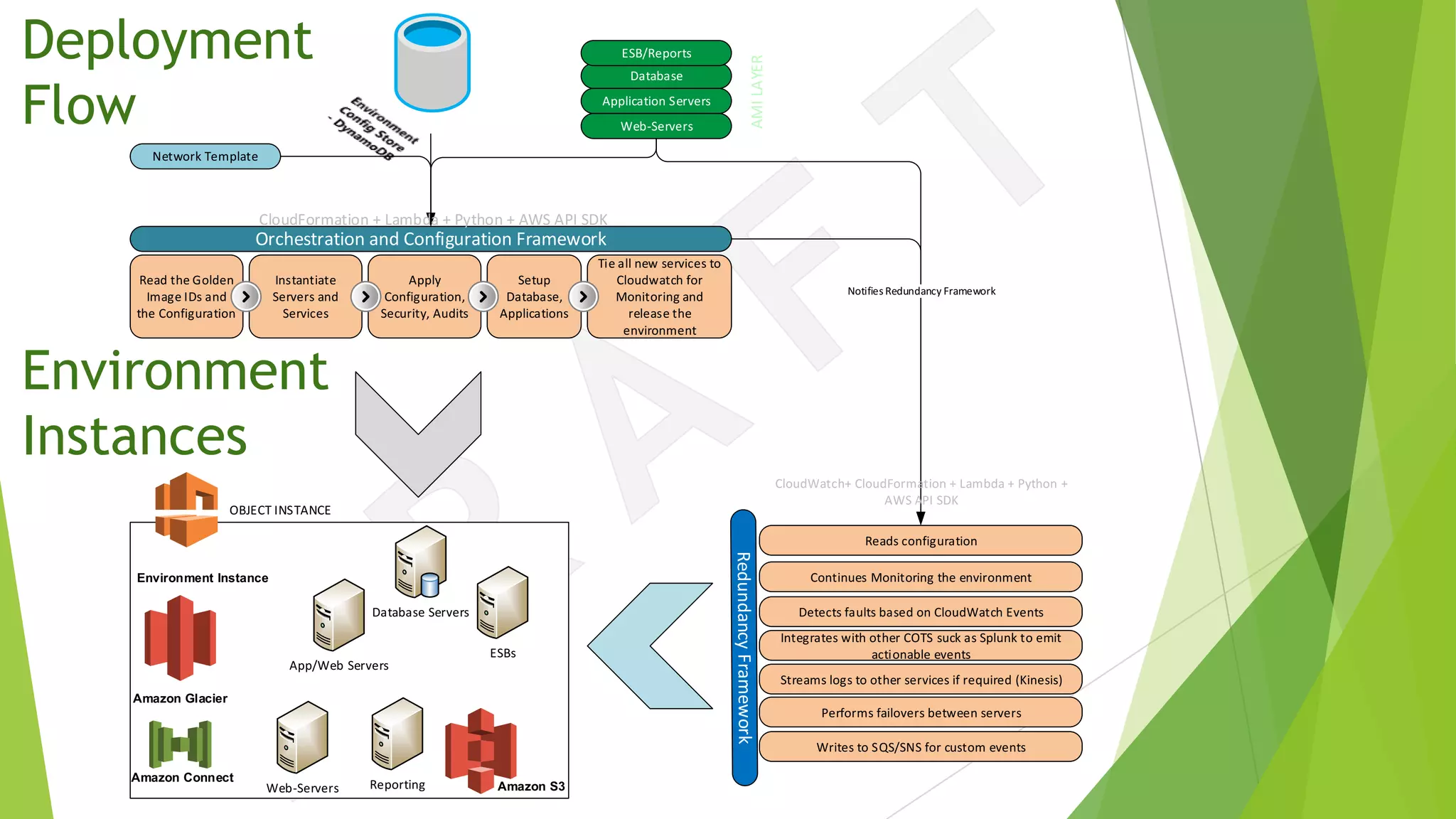
The document discusses the transition from traditional data center application deployment to cloud infrastructure governance, highlighting the inefficiencies of pre-cloud (B.C.) processes and the improvements seen post-cloud (A.C.). It emphasizes the importance of leveraging cloud ecosystems, automation, and infrastructure as code to enhance efficiency and reduce errors, while also outlining best practices for migrating applications and managing cloud resources effectively. The use of Amazon Web Services (AWS) as a case study illustrates the benefits of cloud services, including scalability, redundancy, and compliance with various standards.























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















