Downloaded 16 times









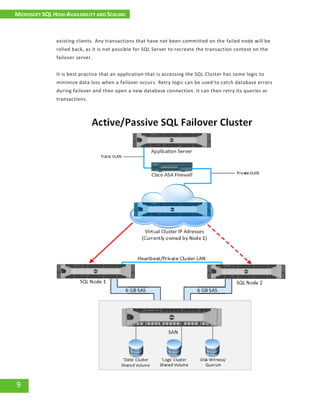


This white paper outlines Microsoft SQL Server high availability and scaling options, detailing technologies like log shipping, SQL mirroring, and SQL clustering, along with their definitions, use-cases, and pros and cons. It provides a methodology for sales personnel to determine when to apply each technology based on recovery time and recovery point objectives. The document serves as an internal resource for understanding how to maintain continuous service and manage potential system failures.



























































