Downloaded 15 times










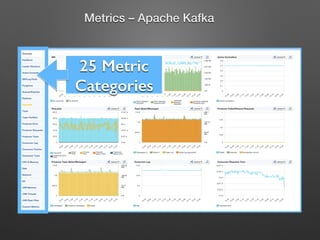


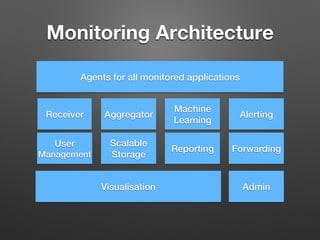
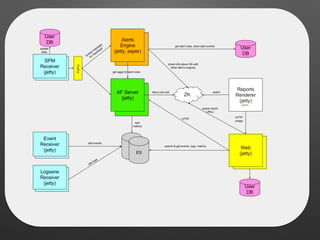


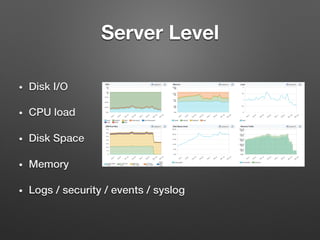

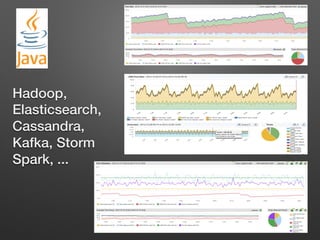

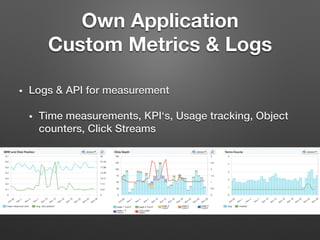
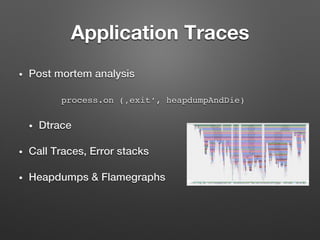

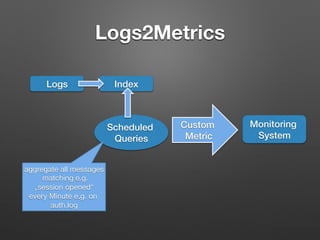






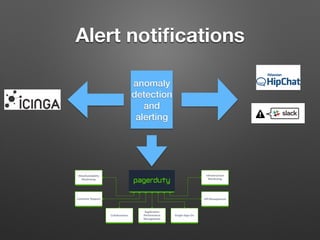

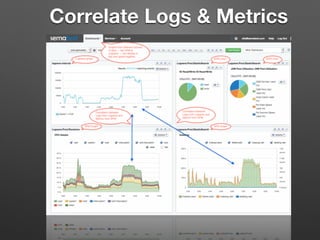

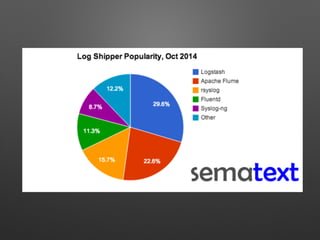
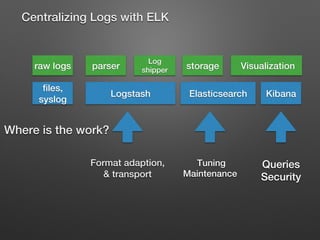






The document discusses the importance of monitoring big data systems at scale, highlighting the need to tune performance, detect bugs, and ensure stability while managing vast amounts of data points from various applications. It outlines key components of a monitoring infrastructure, including metric sources, alerting workflows, and the integration of machine learning for event analysis. Effective monitoring solutions require defining criteria, mapping application landscapes, and custom metrics management, along with tools like ELK for log centralization and visualization.








































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


