Download as PDF, PPTX





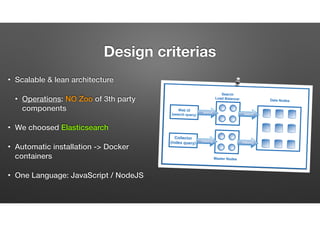
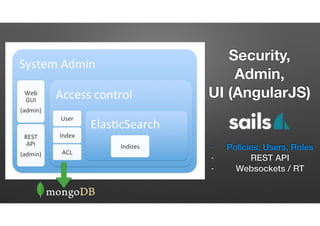
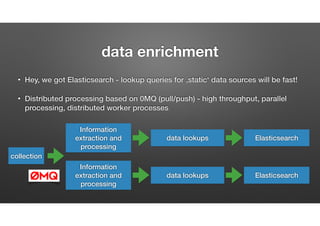
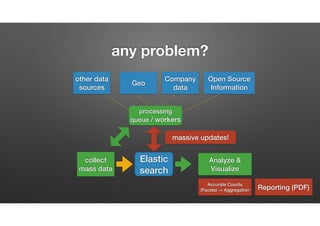




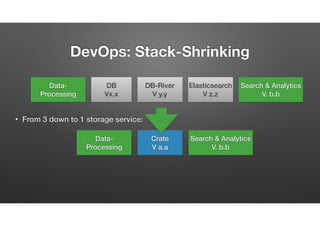

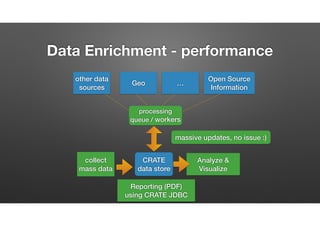


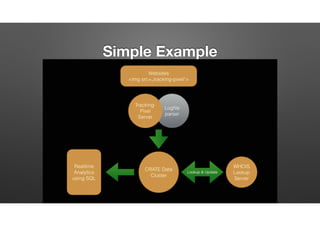
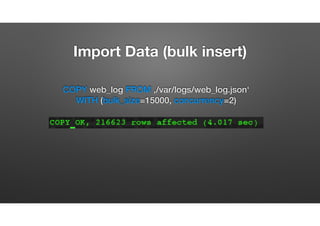
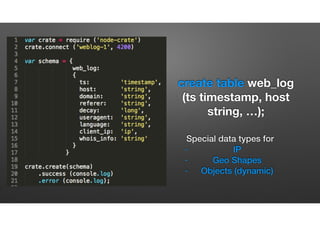
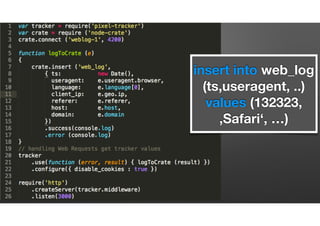
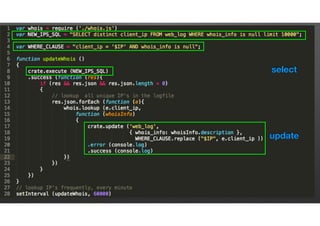
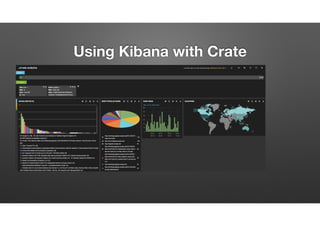

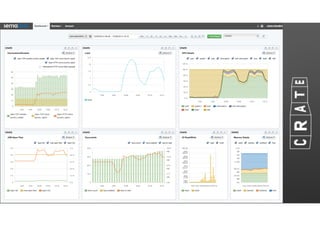







The document discusses the evolution of node-crate, a tool integrating node.js with big data systems, focusing on performance, architecture, and data management. It outlines challenges in using Elasticsearch and proposes crate as a solution for better data processing and blob storage management. It also touches on monitoring, performance issues, and tools available for effective data handling and analysis.









































































