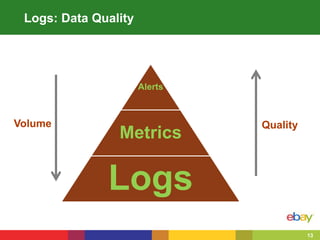
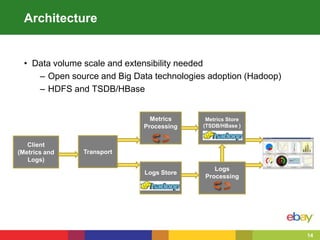
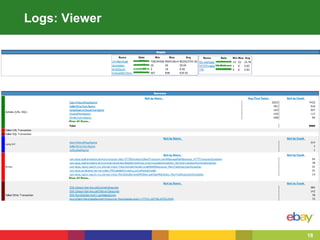
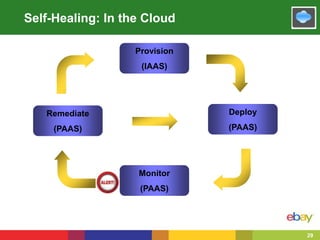
This document summarizes eBay's approach to monitoring Java applications at scale in the cloud. eBay manages over 100 million active users, 2 billion photos, and processes over 80 petabytes of data daily across more than 1000 applications running on over 50,000 servers. To handle this scale, eBay uses open source and big data technologies like Hadoop to process over 150 terabytes of log data daily and collect 60,000 metrics per second. eBay's monitoring includes logs, metrics, alerts, and self-healing capabilities to maintain service quality in such a large, dynamic environment.


























![[WSO2Con EU 2017] Open Interoperability of WSO2 Analytics Platform](https://cdn.slidesharecdn.com/ss_thumbnails/9mrq2xytr5oqokhb1dgt-signature-6abac760590306a9c092f3ba66249d9a805ee6b52c9eb804a80eabb33b95c5ef-poli-171106133401-thumbnail.jpg?width=640&height=640&fit=bounds)























