The document serves as a mathematics primer aimed at refreshing essential topics such as calculus, linear algebra, differential equations, and probability & statistics. It defines fundamental mathematical concepts and functions, emphasizing functions' roles in mapping domains to ranges, along with discussions on various types of functions and their properties. Additionally, the document covers limits, exponential and logarithmic functions, and trigonometric functions, illustrating mathematical behaviors and identities.


![(a; b) = a < x < b open interval
[a; b] = a x b closed interval
(a; b] = a < x b semi-open/closed interval
[a; b) = a x < b semi-open/closed interval
So typically we would write x 2 (a; b) :
Examples
1 < x < 1 ( 1; 1)
1 < x b ( 1; b]
a x < 1 [a; 1)
Page 4
1.2 Functions
This is a term we use very loosely, but what is a function? Clearly it is a type of
black box with some input and a corresponding output. As long as the correct
result comes out we usually are not too concerned with what happens ’
inside’
.
A function denoted f (x) of a single variable x is a rule that assigns each ele-
ment of a set X (written x 2 X) to exactly one element y of a set Y (y 2 Y ) :
A function is denoted by the form y = f (x) or x 7! f (x) :
We can also write f : X ! Y; which is saying that f is a mapping such that
all members of the input set X are mapped to elements of the output set Y:
So clearly there are a number of ways to describe the workings of a function.
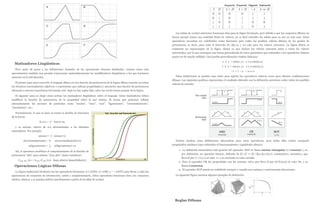
For example, if f (x) = x3; then f ( 2) = 23 = 8:
Page 5
-30
-20
-10
0
10
20
30
-4 -3 -2 -1 0 1 2 3 4
We often write y = f (x) where y is the dependent variable and x is the
independent variable.
Page 6
The set X is called the domain of f and the set Y is called the image (or
range), written Domf and Im f; in turn. For a given value of x there should
be at most one value of y. So the role of a function is to operate on the
domain and map it across uniquely to the range.
So we have seen two notations for the same operation.
The …rst y = f (x) suggests a graphical representation whilst the second
f : X ! Y establishes the idea of a mapping.
Page 7](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-2-320.jpg)





![1.3.2 Trigonometric/Circular Functions
sinx and cosx
-1.5
-1
-0.5
0
0.5
1
1.5
-8 -6 -4 -2 0 2 4 6 8
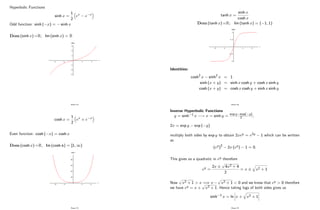
sin x is an odd function, i.e. sin ( x) = sin x:
It is periodic with period 2 : sin (x + 2 ) = sin x. This means that after
every 360 it repeats itself.
sin x = 0 () x = n 8n 2 Z
Page 28
Dom (sin x) =R and Im (sin x) = [ 1; 1]
cos x is an even function, i.e. cos ( x) = cos x:
It is periodic with period 2 : cos (x + 2 ) = cos x.
cos x = 0 () x = (2n + 1) 2 8n 2 Z
Dom (cos x) =R and Im (cos x) = [ 1; 1]
tan x =
sin x
cos x
This is an odd function: tan ( x) = tan x
Periodic: tan (x + ) = tan x
Page 29
Dom = fx : cos x 6= 0g =
n
x : x 6= (2n + 1) 2; n 2 Z
o
= R
n
(2n + 1) 2; n 2 Z
o
Trigonometric Identities:
cos2 x + sin2 x = 1; sin (x y) = sin x cos y cos x sin y
cos (x y) = cos x cos y sin x sin y; tan (x + y) =
tan x + tan y
1 tan x tan y
Exercise: Verify the following sin x + 2 = cos x; cos 2 x = sin x:
The reciprocal trigonometric functions are de…ned by
sec x =
1
cos x
; csc x =
1
sin x
; cot x =
1
tan x
Page 30
More examples on limiting:
lim
x!0
sin x ! 0; lim
x!0
sin x
x
! 1; lim
x!0
jxj ! 0
What about lim
x!0
jxj
x
?
lim
x!0+
jxj
x
= 1
lim
x!0
jxj
x
= 1
therefore
jxj
x
does not tend to a limit as x ! 0:
Page 31](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-8-320.jpg)









![1.6.2 The De…nite Integral
The de…nite integral,
Z b
a
f (x) dx;
is the area under the graph of f (x) ; between x = a and x = b; with
positive values of f (x) giving positive area and negative values of f (x)
contributing negative area. It can be computed if the inde…nite integral is
known. For example
Z 3
1
x3dx =
1
4
x4
3
1
=
1
4
34 14 = 20;
Z 1
1
exdx = [ex]1
1 = e 1=e:
Note that the de…nite integral is also linear in the sense that
Z b
a
(Af (x) + Bg (x)) dx = A
Z b
a
f (x) dx + B
Z b
a
g (x) dx:
Page 80
Note also that a de…nite integral
Z b
a
f (x) dx
does not depend on the variable of integration, x in the above, it only depends
on the function f and the limits of integration (a and b in this case); the
area under a curve does not depend on what we choose to call the horizontal
axis.
So
Z b
a
f (x) dx =
Z b
a
f (y) dy =
Z b
a
f (z) dz:
We should never confuse the variable of integration with the limits of integra-
tion; a de…nite integral of the form
Z x
a
f (x) dx;
use dummy variable.
Page 81
If a < b < c then
Z c
a
f (x) dx =
Z b
a
f (x) dx +
Z c
b
f (x) dx:
Also
Z a
c
f (x) dx =
Z c
a
f (x) dx:
Page 82
1.6.3 Integration by Substitution
This involves the change of variable and used to evaluate integrals of the form
Z
g (f (x)) f0 (x) dx;
and can be evaluated by writing z = f (x) so that dz=dx = f0 (x) or
dz = f0 (x) dx: Then the integral becomes
Z
g (z) dz:
Examples:
Z
x
1 + x2
dx : z = 1 + x2 ! dz = 2xdx
Z
x
1 + x2
dx =
1
2
log (z) + C =
1
2
log 1 + x2 + C
= log
q
1 + x2 + C
Page 83](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-21-320.jpg)
![R
xe x2
dx : z = x2 ! dz = 2xdx
Z
xe x2
dx =
1
2
Z
ezdz
=
1
2
ez + C =
1
2
e x2
+ C
Z
1
x
log (x) dx =
Z
z dz =
1
2
z2 + C
=
1
2
(log (x))2
+ C
with z = log (x) so dz = dx=x and
Z
ex+ex
dx =
Z
exeex
dx =
Z
ezdz
= ez + C = eex
+ C
with z = ex so dz = exdx:
Page 84
The method can be used for de…nite integrals too. In this case it is usually more
convenient to change the limits of integration at the same time as changing
the variable; this is not strictly necessary, but it can save a lot of time.
For example, consider
Z 2
1
ex2
2xdx:
Write z = x2; so dz = 2xdx: Now consider the limits of integration; when
x = 2; z = x2 = 4 and when x = 1; z = x2 = 1: Thus
Z x=2
x=1
ex2
2xdx =
Z z=4
z=1
ezdz
= [ez]z=4
z=1 = e4 e1:
Page 85
Further examples: consider
Z x=2
x=1
2xdx
1 + x2
:
In this case we could write z = 1 + x2; so dz = 2xdx and x = 1
corresponds to z = 2, x = 2 corresponds to z = 5; and
Z x=2
x=1
2x
1 + x2
dx =
Z z=5
z=2
dz
z
= [ln (z)]z=5
z=2 = log (5) ln (2)
= ln (5=2)
We can solve the same problem without change of limit, i.e.
n
ln 1 + x2
ox=2
x=1
! ln 5 ln 2 = ln 5=2:
Page 86
Or consider
Z x=e
x=1
2
log (x)
x
dx
in which case we should choose z = log (x) so dz = dx=x and x = 1
gives z = 0; x = e gives z = 1 and so
Z x=e
x=1
2
log (x)
x
dx =
Z z=1
z=0
2zdz =
h
z2
iz=1
z=0
= 1:
Page 87](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-22-320.jpg)
















![the …rst non-zero entry of each row increases row by row.
A matrix A is said to be row equivalent to a matrix B; written A B
if B can be obtained from A from a …nite sequence of operations called
elementary row operations of the form:
[ER1]: Interchange the i th and j th rows: Ri $ Rj
[ER2]:Replace the i th row by itself multiplied by a non-zero constant k :
Ri ! kRi
[ER3]:Replace the i th row by itself plus k times the j th row: Ri ! Ri+kRj
These have no a¤ect on the solution of the of the linear system which gives
the augmented matrix.
Page 152
Examples:
Solve the following linear systems
1.
2x + y 2z = 10
3x + 2y + 2z = 1
5x + 4y + 3z = 4
9
>
=
>
;
Ax = b with
A =
0
B
@
2 1 2
3 2 2
5 4 3
1
C
A and b =
0
B
@
10
1
4
1
C
A
The augmented matrix for this system is
0
B
@
2 1 2
3 2 2
5 4 3
10
1
4
1
C
A
R2!2R2 3R1
R3!2R3 5R1
0
B
@
2 1 2
0 1 10
0 3 16
10
28
42
1
C
A
Page 153
R3!R3 3R2
R1!R1 R2
0
B
@
2 0 12
0 1 10
0 0 14
38
28
42
1
C
A
14z = 42 ! z = 3
y + 10z = 28 ! y = 28 + 30 = 2
x 6z = 19 ! x = 19 18 = 1
Therefore solution is unique with
x =
0
B
@
1
2
3
1
C
A
Page 154
2.
x + 2y 3z = 6
2x y + 4z = 2
4x + 3y 2z = 14
9
>
=
>
;
0
B
@
1 2 3
2 1 4
4 3 2
6
2
14
1
C
A
R2!R2 2R1
R3!R3 4R1
0
B
@
1 2 3
0 5 10
0 5 10
6
10
10
1
C
A
R3!R3 R2
R2!0:5R2
0
B
@
1 2 3
0 1 2
0 0 0
6
2
0
1
C
A
Number of equations is less than number of unknowns.
y 2z = 2 so z = a is a free variable) y = 2 (1 + a)
x + 2y 3z = 6 ! x = 6 2y + 3z = 2 a
Page 155](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-39-320.jpg)

![( 1)1+1
A11 jM11j + ( 1)1+2
A12 jM12j + ( 1)1+3
A13 jM13j
= 1
2 1
1 3
1
1 1
0 3
+ 0
1 2
0 1
= (2 3 1 1) (1 3 1 0) + 0 = 5 3
= 2
Here we have expanded about the 1st row - we can do this about any row. If
we expand about the 2nd row - we should still get jAj = 2:
We now calculate the adjoint:
( 1)1+1
M11 = +
2 1
1 3
( 1)1+2
M12 =
1 1
0 3
( 1)1+3
M13 = +
1 2
0 1
( 1)2+1
M21 =
1 0
1 3
( 1)2+2
M22 = +
1 0
0 3
( 1)2+3
M23 =
1 1
0 1
( 1)3+1
M31 = +
1 0
2 1
( 1)3+2
M32 =
1 0
1 1
( 1)3+3
M33 = +
1 1
1 2
Page 160
adj A =
0
B
@
5 3 1
3 3 1
1 1 1
1
C
A
T
We can now write the inverse of A (which is symmetric)
A 1 =
1
2
0
B
@
5 3 1
3 3 1
1 1 1
1
C
A
Elementary row operations (as mentioned above) can be used to simplify a
determinant, as increased numbers of zero entries present, requires less calcu-
lation. There are two important points, however. Suppose the value of the
determinant is jAj ; then:
[ER1]: Ri $ Rj ) jAj ! jAj
[ER2]: Ri ! kRi ) jAj ! k jAj
Page 161
2.5 Orthogonal Matrices
A matrix P is orthogonal if
PPT = PTP =I:
This means that the rows and columns of P are orthogonal and have unit
length. It also means that
P 1 = PT:
In two dimensions, orthogonal matrices have the form
cos sin
sin cos
!
or
cos sin
sin cos
!
for some angle and they correspond to rotations or re‡ections.
Page 162
So rows and columns being orthogonal means row i row j = 0; i.e. they are
perpendicular to each other.
(cos ; sin ) ( sin ; cos ) =
cos sin + sin cos = 0
(cos ; sin ) (sin ; cos ) =
cos sin sin cos = 0
v = (cos ; sin )T
! jvj = cos2 + ( sin )2
= 1
Finally, if P =
cos sin
sin cos
!
then
P 1 =
1
cos2 sin2
| {z }
=1
cos sin
sin cos
!
= PT :
Page 163](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-41-320.jpg)














![Hence K = 1
30 (1 i) to give
yp =
1
30
Re (1 i) (cos 3x + i sin 3x)
=
1
30
(cos 3x + i sin 3x i cos 3x + sin 3x)
so general solution becomes
y = e x + e6x 1
30
(cos 3x + sin 3x)
Page 220
3.5.1 Failure Case
Consider the DE y00 5y0 + 6y = e2x, which has a CF given by y (x) =
e2x + e3x. To …nd a PI, if we try yp = Ae2x, we have upon substitution
Ae2x [4 10 + 6] = e2x
so when k (= 2) is also a solution of the C.F , then the trial solution yp =
Aekx fails, so we must seek the existence of an alternative solution.
Page 221
Ly = y00 + ay0 + b = ekx - trial function is normally yp = Cekx:
If k is a root of the A.E then L Cekx = 0 so this substitution does not
work. In this case, we try yp = Cxekx - so ’
go one up’
.
This works provided k is not a repeated root of the A.E, if so try yp = Cx2ekx,
and so forth ....
Page 222
3.6 Linear ODE’
s with Variable Coe¢ cients - Euler Equa-
tion
In the previous sections we have looked at various second order DE’
s with
constant coe¢ cients. We now introduce a 2nd order equation in which the
coe¢ cients are variable in x. An equation of the form
L y = ax2d2y
dx2
+ x
dy
dx
+ cy = g (x)
is called a Cauchy-Euler equation. Note the relationship between the coe¢ cient
and corresponding derivative term, ie an (x) = axn and
d ny
dxn
, i.e. both power
and order of derivative are n.
Page 223](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-56-320.jpg)
![The equation is still linear. To solve the homogeneous part, we look for a
solution of the form
y = x
So y0 = x 1 ! y00 = ( 1) x 2 , which upon substitution yields the
quadratic, A.E.
a 2 + b + c = 0
[where b = ( a)] which can be solved in the usual way - there are 3 cases
to consider, depending upon the nature of b2 4ac.
Page 224
Case 1: b2 4ac > 0 ! 1, 2 2 R - 2 real distinct roots
GS y = Ax 1 + Bx 2
Case 2: b2 4ac = 0 ! = 1 = 2 2 R - 1 real (double fold) root
GS y = x (A + B ln x)
Case 3: b2 4ac < 0 ! = i 2 C - pair of complex conjugate
roots
GS y = x (A cos ( ln x) + B sin ( ln x))
Page 225
Example 1 Solve x2y00 2xy0 4y = 0
Put y = x ) y0 = x 1 ) y00 = ( 1) x 2 and substitute
in DE to obtain (upon simpli…cation) the A.E. 2 3 4 = 0 !
( 4) ( + 1) = 0
) = 4 & 1 : 2 distinct R roots. So GS is
y (x) = Ax4 + Bx 1
Example 2 Solve x2y00 7xy0 + 16y = 0
So assume y = x
A.E 2 8 + 16 = 0 ) = 4 , 4 (2 fold root)
’
go up one’
, i.e. instead of y = x , take y = x ln x to give
y (x) = x4 (A + B ln x)
Page 226
Example 3 Solve x2y00 3xy0 + 13y = 0
Assume existence of solution of the form y = x
A.E becomes 2 4 + 13 = 0 ! =
4
p
16 52
2
=
4 6i
2
1 = 2 + 3i, 2 = 2 3i i ( = 2, = 3)
y = x2 (A cos (3 ln x) + B sin (3 ln x))
Page 227](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-57-320.jpg)










![1.7 Probability Distributions 1 PROBABILITY
a) Find k and Sketch the probability distribution
b) Find P(X ≤ 1.5)
a)
Z +∞
∞
f(x)dx = 1
1 =
Z 2
1
kdx +
Z 4
2
k(x − 1)dx
1 = [kx]2
1 +
kx2
2
− kx
4
2
1 = 2k − k + [(8k − 4k) − (2k − 2k)]
1 = 5k
∴ k =
1
5
19
1.8 Cumulative Distribution Function 1 PROBABILITY
b)
P(X ≤ 1.5) =
Z 1.5
1
1
5
dx
=
hx
5
i1.5
1
=
1
10
1.8 Cumulative Distribution Function
The CDF is an alternative function for summarising a
probability distribution. It provides a formula for P(X ≤
x), i.e.
F(x) = P(X ≤ x)
1.8.1 Discrete Random variables
Example
Consider the probability distribution
x 1 2 3 4 5 6
P(X = x) 1
2
1
4
1
8
1
16
1
32
1
32
F(X) = P(X ≤ x)
Find:
a) F(2) and
b) F(4.5)
20](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-70-320.jpg)

![1.9 Expectation and Variance 1 PROBABILITY
For a discrete random variable
V ar(X) = E(X2
) − [E(X)]2
Now, for previous example
E(X2
) = 12
×
1
2
+ 22
×
1
4
+ 32
× 18 + 42
×
1
8
E(X) =
15
18
∴ V ar(X) =
71
64
= 1.10937...
Standard Deviation = 1.05(3s.f)
1.9.2 Continuous Random Variables
For a continuous random variable
E(X) =
Z
allx
xf(x)dx
and
V ar(X) = E(X2
) − [E(X)]2
=
Z
allx
x2
f(x)dx −
Z
allx
xf(x)dx
2
Example
if
f(x) =
3
32(4x − x2
) 0 ≤ x ≤ 4
0 otherwise
27
1.9 Expectation and Variance 1 PROBABILITY
Find E(X) and V ar(X)
E(X) =
Z 4
0
x.
3
32
(4x − x2
)dx
=
3
32
Z 4
0
4x − x2
dx
=
3
32
4x3
3
−
x4
4
4
0
=
3
32
4(4)3
3
−
44
4
− (0)
= 2
V ar(X) = E(X2
) − [E(X)]2
=
Z 4
0
x2
.
3
32
(4x − x2
)dx − 22
=
3
32
4x4
4
−
x5
5
4
0
− 4
=
3
32
44
−
45
5
− 4
=
4
5
28](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-74-320.jpg)
![1.10 Expectation Algebra 1 PROBABILITY
1.10 Expectation Algebra
Suppose X and Y are random variables and a,b and c
are constants. Then:
• E(X + a) = E(X) + a
• E(aX) = aE(X)
• E(X + Y ) = E(X) + E(Y )
• V ar(X + a) = V ar(X)
• V ar(aX) = a2
V ar(X)
• V ar(b) = 0
If X and Y are independent, then
• E(XY ) = E(X)E(Y )
• V ar(X + Y ) = V ar(X) + V ar(Y )
29
1.11 Moments 1 PROBABILITY
1.11 Moments
The first moment is E(X) = µ
The nth
moment is E(Xn
) =
R
allx xn
f(x)dx
We are often interested in the moments about the
mean, i.e. central moments.
The 2nd
central moment about the mean is called the
variance E[(X − µ)2
] = σ2
The 3rd
central moment is E[(X − µ)3
]
So we can compare with other distributions, we scale
with σ3
and define Skewness.
Skewness =
E[(X − µ)3
]
σ3
This is a measure of asymmetry of a distribution. A
distribution which is symmetric has skew of 0. Negative
values of the skewness indicate data that are skewed to
the left, where positive values of skewness indicate data
skewed to the right.
30](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-75-320.jpg)
![1.11 Moments 1 PROBABILITY
The 4th
normalised central moment is called Kurtosis
and is defined as
Kurtosis =
E[(X − µ)4
]
σ4
A normal random variable has Kurtosis of 3 irrespec-
tive of its mean and standard deviation. Often when
comparing a distribution to the normal distribution, the
measure of excess Kurtosis is used, i.e. Kurtosis of
distribution −3.
Intiution to help understand Kurtosis
Consider the following data and the effect on the Kur-
tosis of a continuous distribution.
xi µ ± σ :
The contribution to the Kurtosis from all data points
within 1 standard deviation from the mean is low since
(xi − µ)4
σ4
1
e.g consider
x1 = µ +
1
2
σ
then
(x1 − µ)4
σ4
=
1
2
4
σ4
σ4
=
1
2
4
=
1
16
xi µ ± σ :
31
1.11 Moments 1 PROBABILITY
The contribution to the Kurtosis from data points
greater than 1 standard deviation from the mean will
be greater the further they are from the mean.
(xi − µ)4
σ4
1
e.g consider
x1 = µ + 3σ
then
(x1 − µ)4
σ4
=
(3σ)4
σ4
= 81
This shows that a data point 3 standard deviations
from the mean would have a much greater effect on the
Kurtosis than data close to the mean value. Therefore,
if the distribution has more data in the tails, i.e. fat tails
then it will have a larger Kurtosis.
Thus Kurtosis is often seen as a measure of how ’fat’
the tails of a distribution are.
If a random variable has Kurtosis greater than 3 is
is called Leptokurtic, if is has Kurtosis less than 3 it is
called platykurtic
Leptokurtic is associated with PDF’s that are simul-
taneously peaked and have fat tails.
32](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-76-320.jpg)
![1.11 Moments 1 PROBABILITY
33
1.12 Covariance 1 PROBABILITY
1.12 Covariance
The covariance is useful in studying the statistical de-
pendence between two random variables. If X and Y
are random variables, then theor covariance is defined
as:
Cov(X, Y ) = E [(X − E(X))(Y − E(Y ))]
= E(XY ) − E(X)E(Y )
Intuition
Imagine we have a single sample of X and Y, so that:
X = 1, E(X) = 0
Y = 3, E(Y ) = 4
Now
X − E(X) = 1
and
Y − E(Y ) = −1
i.e.
Cov(X, Y ) = −1
So in this sample when X was above its expected value
and Y was below its expected value we get a negative
number.
Now if we do this for every X and Y and average
this product, we should find the Covariance is negative.
What about if:
34](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-77-320.jpg)


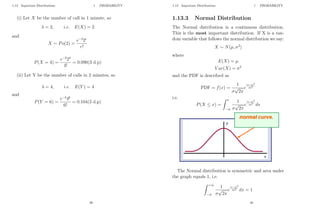
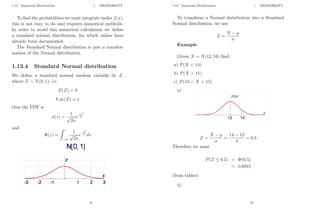
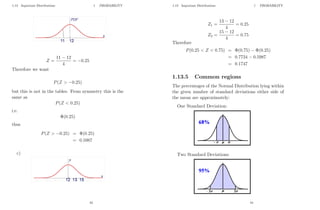


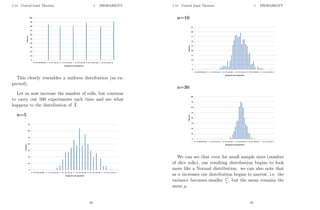
![2 STATISTICS
2 Statistics
2.1 Sampling
So far we have been dealing with populations, however
sometimes the population is too large to be able to anal-
yse and we need to use a sample in order to estimate the
population parameters, i.e. mean and variance.
Consider a population of N data points and a sample
taken from this population of n data points.
We know that the mean and variance of a population
are given by:
population mean, µ =
PN
i=1 xi
N
and
population variance, σ2
=
PN
i=1 (xi − x̄)2
N
51
2.1 Sampling 2 STATISTICS
But how can we use the sample to estimate our pop-
ulation parameters?
First we define an unbiased estimator. An unbiased
estimator is when the expected value of the estimator is
exactly equal to the corresponding population parame-
ter, i.e.
if x̄ is the sample mean then the unbiased estimator is
E(x̄) = µ
where the sample mean is given by:
x̄ =
PN
i=1 xi
n
If S2
is the sample variance, then the unbiased esti-
mator is
E(S2
) = σ2
where the sample variance is given by:
S2
=
Pn
i=1 (xi − x̄)2
n − 1
2.1.1 Proof
From the CLT, we know:
E(X̄) = µ
and
V ar(X̄) =
σ2
n
Also
V ar(X̄) = E(X̄2
) − [E(X̄)]2
52](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-86-320.jpg)



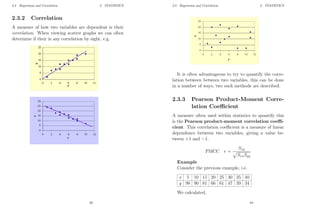
![2.3 Regression and Correlation 2 STATISTICS
2.3 Regression and Correlation
2.3.1 Linear regression
We are often interested in looking at the relationship be-
tween two variables (bivariate data). If we can model
this relationship then we can use our model to make pre-
dictions.
A sensible first step would be to plot the data on a
scatter diagram, i.e. pairs of values (xi, yi)
Now we can try to fit a straight line through the data.
We would like to fit the straight line so as to minimise
the sum of the squared distances of the points from the
line. The different between the data value and the fitted
line is called the residual or error and the technique of
often referred to as the method of least squares.
59
2.3 Regression and Correlation 2 STATISTICS
If the equation of the line is given by
y = bx + a
then the error in y, i..e the residual of the ith
data point
(xi, yi) would be
ri = yi − y
= yi − (bxi + a)
We want to minimise
Pn=∞
n=1 r2
i , i.e.
S.R =
n=∞
X
n=1
r2
i =
n=∞
X
n=1
[yi − (bxi + a)]2
We want to find the b and a that minimise
Pn=∞
n=1 r2
i .
S.R =
X
y2
i − 2yi(bxi + a) + (bxi + a)2
=
X
y2
i − 2byixi − 2ayi + b2
x2
i + 2baxi + a2
or
= n ¯
y2 − 2bn ¯
xy − 2anȳ + b2
n ¯
x2 + 2banx̄ + na2
60](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-90-320.jpg)





![Mathematical Preliminaries
Introduction to Probability
Preliminaries
Randomness lies at the heart of …nance and whether terms uncertainty or risk are used, they refer to the
random nature of the …nancial markets. Probability theory provides the necessary structure to model the
uncertainty that is central to …nance. We begin by de…ning some basic mathematical tools.
The set of all possible outcomes of some given experiment is called the sample space. A particular
outcome ! 2 is called a sample point.
An event is a set of outcomes, i.e. .
To a set of basic outcomes !i we assign real numbers called probabilities, written P (!i) = pi: Then for
any event E;
P (E) =
X
!i2E
pi
Example 1
Experiment: A dice is rolled and the number appearing on top is observed. The sample space consists
of the 6 possible numbers:
= f1; 2; 3; 4; 5; 6g
If the number 4 appears then ! = 4 is a sample point, clearly 4 2 .
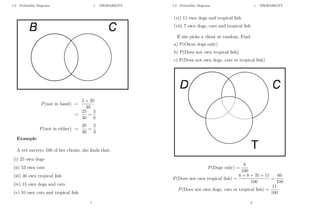
Let 1, 2, 3 = events that an even, odd, prime number occurs respectively.
So
1 = f2; 4; 6g ; 2 = f1; 3; 5g ; 3 = f2; 3; 5g
1 [ 3 = f 2; 3; 4; 5; 6g event that an even or prime number occurs.
2 3 = f3; 5g event that odd and prime number occurs.
c
3 = f1; 4; 6g event that prime number does not occur (complement of event).
Example 2
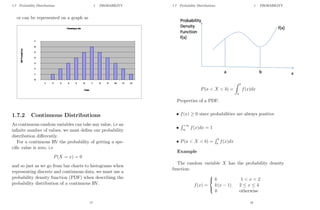
Toss a coin twice and observe the sequence of heads (H) and tails (T) that appears. Sample space
= fHH, TT, HT, THg
Let 1 be event that at least one head appears, and 2 be event that both tosses are the same:
1 = fHH, HT, THg , 2 = fHH, TTg
1 2 = fHHg
Events are subsets of , but not all subsets of are events.
1
The basic properties of probabilities are
1. 0 pi 1
2. P ( ) =
X
i
pi = 1 (the sum of the probabilities is always 1).
Random Variables
Outcomes of experiments are not always numbers, e.g. 2 heads appearing; picking an ace from a deck
of cards. We need some way of assigning real numbers to each random event. Random variables assign
numbers to events.
Thus a random variable (RV) X is a function which maps from the sample space to the set of real
numbers
X : ! 2 ! R;
i.e. it associates a number X (!) with each outcome !:
Consider the example of tossing a coin and suppose we are paid £ 1 for each head and we lose £ 1 each time
a tail appears. We know that P (H) = P (T) =
1
2
: So now we can assign the following outcomes
P (1) =
1
2
P ( 1) =
1
2
Mathematically, if our random variable is X; then
X =
+1 if H
1 if T
or using the notation above X : ! 2 fH,Tg ! f 1; 1g :
The probability that the RV takes on each possible value is called the probability distribution.
If X is a RV then
P (X = a) = P (f! 2 : X (!) = ag)
is the probability that a occurs (or X maps onto a).
P (a X b) = probability that X lies in the interval [a; b] =
P (f! 2 : a X (!) bg)
X :
Domain
! R
Range (…nite)
X ( ) = fx1; ::::; xng = fxig1 i n
P [xi] = P [X = xi] = f (xi) 8 i:
So the earlier coin tossing example gives
P (X = 1) =
1
2
; P (X = 1) =
1
2
2](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-97-320.jpg)
![f (xi) is the probability distribution of X:
This is called a discrete probability distribution.
xi x1 x2 :::::::::::: xn
f (xi) f (x1) f (x2) :::::::::::: f (xn)
There are two properties of the distribution f (xi)
(i) f (xi) 0 8 i 2 [1; n]
(ii)
n
P
i=1
f (xi) = 1; i.e. sum of all probabilities is one.
Mean/Expectation
The mean measures the centre (average) of the distribution
= E [X] =
n
P
i=1
xi f (xi)
= x1f (x1) + x2f (x2) + ::::: + xnf (xn)
which is equal to the weighted average of all possible values of X together with associated probabilities.
This is also called the …rst moment.
Example:
xi 2 3 8
f (xi) 1
4
1
2
1
4
= E [X] =
3
P
i=1
xif (xi) = 2
1
4
+ 3
1
2
+ 8
1
4
= 4
Variance/Standard Deviation
This measures the spread (dispersion) of X about the mean.
Variance V [X] =
E (X )2
= E X2 2
=
n
P
i=1
x2
i f (xi) 2
= 2
E (X )2
is also called the second moment about the mean.
From the previous example we have = 4; therefore
V [X] = 22 1
4
+ 32 1
2
+ 82 1
4
16
= 5:5 = 2
! = 2:34
Rules for Manipulating Expectations
Suppose X; Y are random variables and ; ; 2 R are constant scalar quantities. Then
3
E [ X] = E [X]
E [X + Y ] = E [X] + E [Y ] ; (linearity)
V [ X + ] = 2
V [X]
E [XY ] = E [X] E [Y ] ;
V [X + Y ] = V [X] + V [Y ]
The last two are provided X; Y are independent.
4](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-98-320.jpg)
![Continuous Random Variables
As the number of discrete events becomes very large, individual probabilities f (xi) ! 0: Now look at the
continuous case.
Instead of f (xi) we now have p (x) which is a continuous distribution called as probability density function,
PDF.
P (a X b) =
Z b
a
p (x) dx
The cumulative distribution function F (x) of a RV X is
F (x) = P (X x) =
Z x
1
p (x) dx
F (x) is related to the PDF by
p (x) =
dF
dx
(fundamental theorem of calculus) provided F (x) is di¤erentiable. However unlike F (x) ; p (x) may
have singularities (and may be unbounded).
Special Expectations:
Given any PDF p (x) of X:
Mean = E [X] =
Z
R
xp (x) dx:
Variance 2
= V [X] = E (X )2
=
Z
R
x2
p (x) dx 2
(2nd
moment about the mean).
The nth
moment about zero is de…ned as
n = E [Xn
]
=
Z
R
xn
p (x) dx:
In general, for any function h
E [h (X)] =
Z
R
h (x) p (x) dx:
where X is a RV following the distribution given by p (x) :
Moments about the mean are given by
E [(X )n
] ; n = 2; 3; :::
The special case n = 2 gives the variance 2
:
5
Skewness and Kurtosis
Having looked at the variance as being the second moment about the mean, we now discuss two further
moments centred about ; that provide further important information about the probability distribution.
Skewness is a measure of the asymmetry of a distribution (i.e. lack of symmetry) about its mean. A
distribution that is identical to the left and right about a centre point is symmetric.
The third central moment, i.e. third moment about the mean scaled with 3
. This scaling allows us to
compare with other distributions.
E (X )3
3
is called the skew and is a measure of the skewness (a non-symmetric distribution is called skewed).
Any distribution which is symmetric about the mean has a skew of zero.
Negative values for the skewness indicate data that are skewed left and positive values for the skewness
indicate data that are skewed right.
By skewed left, we mean that the left tail is long relative to the right tail. Similarly, skewed right means
that the right tail is long relative to the left tail.
The fourth centred moment scaled by the square of the variance, called the kurtosis is de…ned
E (X )4
4
:
This is a measure of how much of the distribution is out in the tails at large negative and positive values
of X:
The 4th
central moment is called Kurtosis and is de…ned as
Kurtosis =
E (X )4
4
normal random variable has Kurtosis of 3 irrespective of its mean and standard deviation. Often when
comparing a distribution to the normal distribution, the measure of excess Kurtosis is used, i.e. Kurtosis
of distribution 3.
If a random variable has Kurtosis greater than 3 is called Leptokurtic, if is has Kurtosis less than 3 it
is called platykurtic Leptokurtic is associated with PDF’
s that are simultaneously peaked and have fat tails.
6](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-99-320.jpg)
![Normal Distribution
The normal (or Gaussian) distribution N ( ; 2
) with mean and standard deviation and 2
in turn
is de…ned in terms of its density function
p (x) =
1
p
2
exp
(x )2
2 2
!
:
For the special case = 0 and = 1 it is called the standard normal distribution N (0; 1) :
This is also veri…ed by making the substitution
=
x
in p (x) which gives
( ) =
1
p
2
exp
1
2
2
and clearly has zero mean and unit variance:
E
X
=
1
E [X ] = 0;
V
X
= V
X
Now V [ X + ] = 2
V [X] (standard result), hence
1
2
V [X] =
1
2
: 2
= 1
Its cumulative distribution function is
F (x) =
1
p
2
Z x
1
e
1
2
2
d = P ( 1 X x) :
The skewness of N (0; 1) is zero and its kurtosis is 3:
7
Correlation
The covariance is useful in studying the statistical dependence between two random variables. If X; Y are
RV’
s, then their covariance is de…ned as:
Cov (X; Y ) = E
2
6
4
0
@X E (X)
| {z }
= x
1
A
0
B
@Y E (Y )
| {z }
= y
1
C
A
3
7
5
= E [XY ] x y
which we denote as XY : Note:
Cov (X; X) = E (X x)2
= 2
:
X; Y are correlated if
E (X x) Y y 6= 0:
We can then de…ne an important dimensionless quantity (used in …nance) called the correlation coe¢ cient
and denoted as XY (X; Y ) where
XY =
Cov (X; Y )
x y
:
The correlation can be thought of as a normalised covariance, as j XY j 1; for which the following
conditions are properties:
i. (X; Y ) = (Y; X)
ii. (X; X) = 1
iii. 1 1
XY = 1 ) perfect negative correlation
XY = 1 )perfect correlation
XY = 0 ) X; Y uncorrelated
Why is the correlation coe¢ cient bounded by 1? Justi…cation of this requires a result called the Cauchy-
Schwartz inequality. This is a theorem which most students encounter for the …rst time in linear algebra
(although we have not discussed this). Let’
s start o¤ with the version for random variables (RVs) X and
Y , then the Cauchy-Schwartz inequality is
[E [XY ]]2
E X2
E Y 2
:
We know that the covariance of X; Y is
XY = E [(X X) (Y Y )]
If we put
V [X] = 2
X = E (X X)2
V [Y ] = 2
Y = E (Y Y )2
:
8](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-100-320.jpg)
![From Cauchy-Schwartz we have
(E [(X X) (Y Y )])2
E (X X)2
E (Y Y )2
or we can write
2
XY
2
X
2
Y
Divide through by 2
X
2
Y
2
XY
2
X
2
Y
1
and we know that the left hand side above is 2
XY , hence
2
XY =
2
XY
2
X
2
Y
1
and since XY is a real number, this implies j XY j 1 which is the same as
1 XY +1:
Central Limit Theorem
This concept is fundamental to the whole subject of …nance.
Let Xi be any independent identically distributed (i.i.d) random variable with mean and variance 2
;
i.e. X D ( ; 2
) ; where D is some distribution: If we put
Sn =
n
P
i=1
Xi
Then
(Sn n )
p
n
has a distribution that approaches the standard normal distribution as n ! 1:
The distribution of the sum of a large number of independent identically distributed variables will be
approximately normal, regardless of the underlying distribution. That is the beauty of this result.
Conditions:
The Normal distribution is the limiting behaviour if you add many random numbers from any basic-building
block distribution provided the following is satis…ed:
1. Mean of distribution must be …nite and constant
2. Standard deviation of distribution must be …nite and constant
This is a measure of how much of the distribution is out in the tails at large negative and positive values
of X:
9
Moment Generating Function
The moment generating function of X; denoted MX ( ) is given by
MX ( ) = E e X
=
Z
R
e x
p (x) dx
provided the expectation exists. We can expand as a power series to obtain
MX ( ) =
1
X
n=0
n
E (Xn
)
n!
so the nth
moment is the coe¢ cient of n
=n!; or the nth
derivative evaluated at zero.
How do we arrive at this result?
We use the Taylor series expansion for the exponential function:
Z
R
e x
p (x) dx =
Z
R
1 + x +
( x)2
2!
+
( x)3
3!
+ ::::::
!
p (x) dx
=
Z
R
p (x) dx
| {z }
1
+
Z
R
xp (x) dx
| {z }
E(X)
+
2
2!
Z
R
x2
p (x) dx
| {z }
E(X2)
+
3
3!
Z
R
x3
p (x) dx
| {z }
E(X3)
+ ::::
= 1 + E (X) +
2
2!
E X2
+
3
3!
E X3
+ ::::
=
1
X
n=0
n
E (Xn
)
n!
:
10](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-101-320.jpg)
![Calculating Moments
The kth
moment mk of the random variable X can now be obtained by di¤erentiating, i.e.
mk = M
(k)
X ( ) ; k = 0; 1; 2; :::
M
(k)
X ( ) =
dk
d k
MX ( )
=0
So what is this result saying? Consider MX ( ) =
1
X
n=0
n
E(Xn)
n!
MX ( ) = 1 + E [X] +
2
2!
E X2
+
3
3!
E X3
+ :::: +
n
n!
E [Xn
]
As an example suppose we wish to obtain the second moment; di¤erentiate twice with respect to
d
d
MX ( ) = E [X] + E X2
+
2
2
E X3
+ :::: +
n 1
(n 1)!
E [Xn
]
and for the second time
d2
d 2 MX ( ) = E X2
+ E X3
+ :::: +
n 2
(n 2)!
E [Xn
] :
Setting = 0; gives
d2
d 2 MX (0) = E X2
which captures the second moment E [X2
]. Remember we will already have an expression for MX ( ) :
A useful result in …nance is the MGF for the normal distribution. If X N ( ; 2
), then we can construct
a standard normal N (0; 1) by setting =
X
=) X = + :
The MGF is
MX ( ) = E e x
= E e ( + )
= e E e
So the MGF of X is therefore equal to the MGF of but with replaced by :This is much nicer than
trying to calculate the MGF of X N ( ; 2
) :
E e =
1
p
2
Z 1
1
e x
e x2=2
dx =
1
p
2
Z 1
1
e x x2=2
dx
=
1
p
2
Z 1
1
e
1
2 (x2 2 x+ 2 2
)dx =
1
p
2
Z 1
1
e
1
2
(x )2
+ 1
2
2
dx
= e
1
2
2 1
p
2
Z 1
1
e
1
2
(x )2
dx
Now do a change of variable - put u = x
E e = e
1
2
2 1
p
2
Z 1
1
e
1
2
u2
du
= e
1
2
2
11
Thus
MX ( ) = e E e
= e + 1
2
2 2
To get the simpler formula for a standard normal distribution put = 0; = 1 to get MX ( ) = e
1
2
2
:
We can now obtain the …rst four moments for a standard normal
m1 =
d
d
e
1
2
2
=0
= e
1
2
2
=0
= 0
m2 =
d2
d 2 e
1
2
2
=0
= 2
+ 1 e
1
2
2
=0
= 1
m3 =
d3
d 3 e
1
2
2
=0
= 3
+ 3 e
1
2
2
=0
= 0
m4 =
d4
d 4 e
1
2
2
=0
= 4
+ 6 2
+ 3 e
1
2
2
=0
= 3
The latter two are particularly useful in calculating the skew and kurtosis.
If X and Y are independent random variables then
MX+Y ( ) = E e (x+y)
= E e x
e y
= E e x
E e y
= MX ( ) MY ( ) :
12](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-102-320.jpg)

![Review of Di¤erential Equations
Cauchy Euler Equation
An equation of the form
Ly = ax2 d2
y
dx2
+ x
dy
dx
+ cy = g (x)
is called a Cauchy-Euler equation.
To solve the homogeneous part, we look for a solution of the form
y = x
So y0
= x 1
! y00
= ( 1) x 2
, which upon substitution yields the quadratic, A.E.
a 2
+ b + c = 0;
where b = ( a) which can be solved in the usual way - there are 3 cases to consider, depending upon
the nature of b2
4ac.
Case 1: b2
4ac 0 ! 1, 2 2 R - 2 real distinct roots
GS y = Ax 1
+ Bx 2
Case 2: b2
4ac = 0 ! = 1 = 2 2 R - 1 real (double fold) root
GS y = x (A + B ln x)
Case 3: b2
4ac 0 ! = i 2 C - pair of complex conjugate roots
GS y = x (A cos ( ln x) + B sin ( ln x))
Example
Consider the following Euler type problem
1
2
2
S2 d2
V
dS2
+ rS
dV
dS
rV = 0;
V (0) = 0; V (S ) = S E
where the constants E; S ; ; r 0. We are given that the roots of A.E m are real with m 0 m+:
Look for a solution of the form General Solution is
V (S) = ASm+
+ BSm
:
V (0) = 0 =) B = 0 else we have division by zero
V (S) = ASm+
15
To …nd A use the second condition V (S ) = S E
V (S ) = A (S )m+
= S E ! A =
S E
(S )m+
hence
V (S) =
S E
(S )m+
(S)m+
= (S E)
S
S
m+
:
Similarity Methods
f (x; y) is homogeneous of degree t 0 if f ( x; y) = t
f (x; y) :
1. f (x; y) =
p
(x2 + y2)
f ( x; y) =
q
( x)2
+ ( y)2
=
p
[(x2 + y2)] = f (x; y)
g (x; y) = x+y
x y
then
g ( x; y) = x+ y
x y
= 0 x+y
x y
= 0
g (x; y)
2. h (x; y) = x2
+ y3
h ( x; y) = ( x)2
+ ( y)3
= 2
x2
+ 3
y3
6= t
x2
+ y3
for any t. So h is not homogeneous.
Consider the function
F (x; y) = x2
x2+y2
If for any 0 we write
x0
= x; y0
= y
then
dy0
dx0
=
dy
dx
; x2
x2+y2 = x02
x02
+y02 :
We see that the equation is invariant under the change of variables. It also makes sense to look for a
solution which is also invariant under the transformation. One choice is to write
v =
y
x
=
y0
x0
so write
y = vx:
De…nition The di¤erential equation
dy
dx
= f (x; y) is said to be homogeneous when f (x; y) is homogeneous
of degree t for some t:
Method of Solution
Put y = vx where v is some (as yet) unknown function. Hence we have
dy
dx
=
d
dx
(vx) = x
dv
dx
+ v
dx
dx
= v0
x + v
16](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-104-320.jpg)






![Using a Binomial random walk
The earlier results can also be obtained using a symmetric random walk. Consider the following (two step)
binomial random walk. So the random variable can either rise or fall with equal probability.
y is the random variable and t is a time step. y is the size of the move in y:
P [ y] = P [ y] = 1=2:
Suppose we are at (y0
; t0
) ; how did we get there? At the previous step time step we must have been at one
of (y0
+ y; t0
t) or (y0
y; t0
t) :
So
p (y0
; t0
) = 1
2
p (y0
+ y; t0
t) + 1
2
p (y0
y; t0
t)
Taylor series expansion gives
p (y0
+ y; t0
t) = p (y0
; t0
)
@p
@t0
t +
@p
@y0
y + 1
2
@2
p
@y02 y2
+ :::
p (y0
y; t0
t) = p (y0
; t0
)
@p
@t0
t
@p
@y0
y + 1
2
@2
p
@y02 y2
+ :::
Substituting into the above
p (y0
; t0
) = 1
2
p (y0
; t0
)
@p
@t0
t +
@p
@y0
y + 1
2
@2
p
@y02 y2
+1
2
p (y0
; t0
)
@p
@t0
t
@p
@y0
y + 1
2
@2
p
@y02 y2
33
0 =
@p
@t0
t + 1
2
@2
p
@y02 y2
@p
@t0
= 1
2
y2
t
@2
p
@y02
Now take limits. This only makes sense if y2
t
is O (1) ; i.e. y2
O ( t) and letting y; t ! 0 gives the
equation
@p
@t0
= 1
2
@2
p
@y02
This is called the forward Kolmogorov equation. Also called Fokker Planck equation.
It shows how the probability density of future states evolves, starting from (y; t) :
A particular solution of this is
p (y; t; y0
; t0
) =
1
p
2 (t0 t)
exp
(y0
y)2
2 (t0 t)
!
At t0
= t this is equal to (y0
y). The particle is known to start from (y; t) and its density is normal
with mean y and variance t0
t:
34](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-113-320.jpg)


![Mathematical Preliminaries
Introduction to Probability - Moment Generating Function
The moment generating function of X; denoted MX ( ) is given by
MX ( ) = E e x
=
Z
R
e x
p (x) dx
provided the expectation exists. We can expand as a power series to obtain
MX ( ) =
1
X
n=0
n
E (Xn
)
n!
so the nth
moment is the coe¢ cient of n
=n!; or the nth
derivative evaluated at zero.
How do we arrive at this result?
We use the Taylor series expansion for the exponential function:
Z
R
e x
p (x) dx =
Z
R
1 + x +
( x)2
2!
+
( x)3
3!
+ ::::::
!
p (x) dx
=
Z
R
p (x) dx
| {z }
1
+
Z
R
xp (x) dx
| {z }
E(X)
+
2
2!
Z
R
x2
p (x) dx
| {z }
E(X2)
+
3
3!
Z
R
x3
p (x) dx
| {z }
E(X3)
+ ::::
= 1 + E (X) +
2
2!
E X2
+
3
3!
E X3
+ ::::
=
1
X
n=0
n
E (Xn
)
n!
:
1
Calculating Moments
The kth
moment mk of the random variable X can now be obtained by di¤erentiating, i.e.
mk = M
(k)
X ( ) ; k = 0; 1; 2; :::
M
(k)
X ( ) =
dk
d k
MX ( )
=0
So what is this result saying? Consider MX ( ) =
1
X
n=0
n
E(Xn)
n!
MX ( ) = 1 + E [X] +
2
2!
E X2
+
3
3!
E X3
+ :::: +
n
n!
E [Xn
]
As an example suppose we wish to obtain the second moment; di¤erentiate twice with respect to
d
d
MX ( ) = E [X] + E X2
+
2
2
E X3
+ :::: +
n 1
(n 1)!
E [Xn
]
and for the second time
d2
d 2 MX ( ) = E X2
+ E X3
+ :::: +
n 2
(n 2)!
E [Xn
] :
Setting = 0; gives
d2
d 2 MX (0) = E X2
which captures the second moment E [X2
]. Remember we will already have an expression for MX ( ) :
A useful result in …nance is the MGF for the normal distribution. If X N ( ; 2
), then we can construct
a standard normal N (0; 1) by setting =
X
=) X = + :
The MGF is
MX ( ) = E e x
= E e ( + )
= e E e
So the MGF of X is therefore equal to the MGF of but with replaced by :This is much nicer than
trying to calculate the MGF of X N ( ; 2
) :
E e =
1
p
2
Z 1
1
e x
e x2=2
dx =
1
p
2
Z 1
1
e x x2=2
dx
=
1
p
2
Z 1
1
e
1
2 (x2 2 x+ 2 2
)dx =
1
p
2
Z 1
1
e
1
2
(x )2
+ 1
2
2
dx
= e
1
2
2 1
p
2
Z 1
1
e
1
2
(x )2
dx
Now do a change of variable - put u = x
E e = e
1
2
2 1
p
2
Z 1
1
e
1
2
u2
du
= e
1
2
2
2](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-116-320.jpg)

![Di¤usion Process
G is called a di¤usion process if
dG (t) = A (G; t) dt + B (G; t) dW (t) (1)
This is also an example of a Stochastic Di¤erential Equation (SDE) for the process G and consists of two
components:
1. A (G;t) dt is deterministic –coe¢ cient of dt is known as the drift of the process.
2. B (G; t) dW is random – coe¢ cient of dW is known as the di¤usion or volatility of the process.
We say G evolves according to (or follows) this process.
For example
dG (t) = (G (t) + G (t 1)) dt + dW (t)
is not a di¤usion (although it is a SDE)
A 0 and B 1 reverts the process back to Brownian motion
Called time-homogeneous if A and B are not dependent on t:
dG 2
= B2
dt:
We say (1) is a SDE for the process G or a Random Walk for dG:
The di¤usion (1) can be written in integral form as
G (t) = G (0) +
Z t
0
A (G; ) d +
Z t
0
B (G; ) dW ( )
Remark: A di¤usion G is a Markov process if - once the present state G (t) = g is given, the past
fG ( ) ; tg is irrelevant to the future dynamics.
We have seen that Brownian motion can take on negative values so its direct use for modelling stock prices
is unsuitable. Instead a non-negative variation of Brownian motion called geometric Brownian motion
(GBM) is used
If for example we have a di¤usion G (t)
dG = Gdt + GdW (2)
then the drift is A (G; t) = G and di¤usion is B (G; t) = G:
The process (2) is also called Geometric Brownian Motion (GBM).
Brownian motion W (t) is used as a basis for a wide variety of models. Consider a pricing process
fS (t) : t 2 R+g: we can model its instantaneous change dS by a SDE
dS = a (S; t) dt + b (S; t) dW (3)
By choosing di¤erent coe¢ cients a and b we can have various properties for the di¤usion process.
A very popular …nance model for generating asset prices is the GBM model given by (2). The instantaneous
return on a stock S (t) is a constant coe¢ cient SDE
dS
S
= dt + dW (4)
where and are the return’
s drift and volatility, respectively.
5
An Extension of Itô’
s Lemma (2D)
Now suppose we have a function V = V (S; t) where S is a process which evolves according to (4) : If
S ! S + dS; t ! t + dt then a natural question to ask is what is the jump in V ? To answer this we
return to Taylor, which gives
V (S + dS; t + dt)
= V (S; t) +
@V
@t
dt +
@V
@S
dS +
1
2
@2
V
@S2
dS2
+ O dS3
; dt2
So S follows
dS = Sdt + SdW
Remember that
E (dW) = 0; dW2
= dt
we only work to O (dt) - anything smaller we ignore and we also know that
dS2
= 2
S2
dt
So the change dV when V (S; t) ! V (S + dS; t + dt) is given by
dV =
@V
@t
dt +
@V
@S
[S dt + S dW] +
1
2
2
S2 @2
V
@S2
dt
Re-arranging to have the standard form of a SDE dG = a (G; t) dt + b (G; t) dW gives
dV =
@V
@t
+ S
@V
@S
+
1
2
2
S2 @2
V
@S2
dt + S
@V
@S
dW. (5)
This is Itô’
s Formula in two dimensions.
Naturally if V = V (S) then (5) simpli…es to the shorter version
dV = S
dV
dS
+
1
2
2
S2 d2
V
dS2
dt + S
dV
dS
dW. (6)
Examples: In the following cases S evolves according to GBM.
Given V = t2
S3
obtain the SDE for V; i.e. dV: So we calculate the following terms
@V
@t
= 2tS3
;
@V
@S
= 3t2
S2
!
@2
V
@S2
= 6t2
S:
We now substitute these into (5) to obtain
dV = 2tS3
+ 3 t2
S3
+ 3 2
S3
t2
dt + 3 t2
S3
dW.
Now consider the example V = exp (tS)
Again, function of 2 variables. So
@V
@t
= S exp (tS) = SV
@V
@S
= t exp (tS) = tV
@2
V
@S2
= t2
V
6](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-118-320.jpg)
![Substitute into (5) to get
dV = V S + tS +
1
2
2
S2
t2
dt + ( StV ) dW:
Not usually possible to write the SDE in terms of V but if you can do so - do not struggle to …nd a
relation if it does not exist. Always works for exponentials.
One more example: That is S (t) evolves according to GBM and V = V (S) = Sn
: So use
dV = S
dV
dS
+
1
2
2
S2 d2
V
dS2
dt + S
dV
dS
dW.
V 0
(S) = nSn 1
! V 00
(S) = n (n 1) Sn 2
Therefore Itô gives us dV =
SnSn 1
+
1
2
2
S2
n (n 1) Sn 2
dt + SnSn 1
dW
dV = nSn
+
1
2
2
n (n 1) Sn
dt + [ nSn
] dW
Now we know V (S) = Sn
; which allows us to write
dV = V n +
1
2
2
n (n 1) dt + [ n] V dW
with drift = V n + 1
2
2
n (n 1) and di¤usion = nV:
7
Important Cases - Equities and Interest Rates
If we now consider S which follows a lognormal random walk, i.e. V = log(S) then substituting into (6)
gives
d ((log S)) =
1
2
2
dt + dW
Integrating both sides over a given time horizon ( between t0 and T )
Z T
t0
d ((log S)) =
Z T
t0
1
2
2
dt +
Z T
t0
dW (T t0)
we obtain
log
S (T)
S (t0)
=
1
2
2
(T t0) + (W (T) W (t0))
Assuming at t0 = 0, W (0) = 0 and S (0) = S0 the exact solution becomes
ST = S0 exp
1
2
2
T +
p
T . (7)
(7) is of particular interest when considering the pricing of a simple European option due to its non path
dependence. Stock prices cannot become negative, so we allow S, a non-dividend paying stock to evolve
according to the lognormal process given above - and acts as the starting point for the Black-Scholes
framework.
However is replaced by the risk-free interest rate r in (7) and the introduction of the risk-neutral measure
- in particular the Monte Carlo method for option pricing.
8](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-119-320.jpg)
![Interest rates exhibit a variety of dynamics that are distinct from stock prices, requiring the development
of speci…c models to include behaviour such as return to equilibrium, boundedness and positivity. Here we
consider another important example of a SDE, put forward by Vasicek in 1977. This model has a mean
reverting Ornstein-Uhlenbeck process for the short rate and is used for generating interest rates, given by
drt = ( rt) dt + dWt. (8)
So drift = ( rt) and volatility = .
refers to the reversion rate and (= r) denotes the mean rate, and we can rewrite this random walk (7)
for dr as
drt = (rt r) dt + dWt.
By setting t = rt r, t is a solution of
d t = tdt + dWt; 0 = ; (9)
hence it follows that t is an Ornstein-Uhlenbeck process and an analytic solution for this equation exists.
(9) can be written as d t + tdt = dWt:
Multiply both sides by an integrating factor e t
e t
(d t + t) dt = e t
dWt
d e t
t = e t
dWt
Integrating over [0; t] gives
Z t
0
d (e s
s) =
Z t
0
e s
dWs
e s
sjt
0 =
Z t
0
e s
dWs ! e t
t 0 =
Z t
0
e s
dWs
t = e t
+
Z t
0
e (s t)
dWs: (10)
By using integration by parts, i.e.
Z
v du = uv
Z
u dv we can simplify (10).
u = Ws
v = e (s t)
! dv = e (s t)
ds
Therefore Z t
0
e (s t)
dWs = Wt
Z t
0
e (s t)
Ws ds
and we can write (10) as
t = e t
+ Wt
Z t
0
e (s t)
Ws ds
allowing numerical treatment for the integral term.
9
Higher Dimensional Itô
Consider the case where N shares follow the usual Geometric Brownian Motions, i.e.
dSi = iSidt + iSidWi;
for 1 i N: The share price changes are correlated with correlation coe¢ cient ij: By starting with a
Taylor series expansion
V (t + t; S1 + S1; S2 + S2; :::::; SN + SN ) =
V (t; S1; S2; :::::; SN ) + @V
@t
+
N
P
i=1
@V
@Si
dSi +
1
2
N
P
i=1
N
P
j=i
@2V
@Si@Sj
+ ::::
which becomes, using dWidWj = ijdt
dV =
@V
@t
+
N
P
i=1
iSi
@V
@Si
+
1
2
N
P
i=1
N
P
j=i
i j ijSiSj
@2
V
@Si@Sj
!
dt +
N
P
i=1
iSi
@V
@Si
dWi:
We can integrate both sides over 0 and t to give
V (t; S1; S2; :::::; SN ) = V (0; S1; S2; :::::; SN ) +
Z t
0
@V
@
+
N
P
i=1
iSi
@V
@Si
+ 1
2
N
P
i=1
N
P
j=i
i j ijSiSj
@2V
@Si@Sj
!
d
+
Z t
0
N
P
i=1
iSi
@V
@Si
dWi:
Discrete Time Random Walks
When simulating a random walk we write the SDE given by (6) in discrete form
S = Si+1 Si = rSi t + Si
p
t
which becomes
Si+1 = Si 1 + r t +
p
t : (11)
This gives us a time-stepping scheme for generating an asset price realization if we know S0, i.e. S (t) at
t = 0: N (0; 1) is a random variable with a standard Normal distribution.
Alternatively we can use discrete form of the analytical expression (7)
Si+1 = Si exp r
1
2
2
t +
p
t :
10](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-120-320.jpg)
![So we now start generating random numbers. In C++ we produce uniformly distributed random variables
and then use the Box Muller transformation (Polar Marsaglia method) to convert them to Gaussians.
This can also be generated on an Excel spreadsheet using the in-built random generator function RAND().
A crude (but useful) approximation for can be obtained from
12
X
i=1
RAND () 6
where RAND() U [0; 1] :
A more accurate (but slower) can be computed using NORMSINV(RAND ()) :
11
Dynamics of Vasicek Model
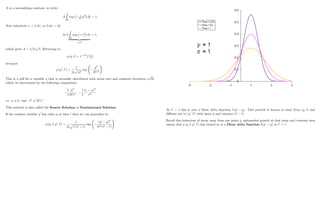
The Vasicek model
drt = (r rt) dt + dWt
is an example of a Mean Reverting Process - an important property of interest rates. refers to the
reversion rate (also called the speed of reversion) and r denotes the mean rate.
acts like a spring. Mean reversion means that a process which increases has a negative trend ( pulls
it down to a mean level r), and when rt decreases on average pulls it back up to r:
In discrete time we can approximate this by writing (as earlier)
ri+1 = ri + (r ri) t +
p
t
0
0.2
0.4
0.6
0.8
1
1.2
0 0.5 1 1.5 2 2.5 3 3.5
To gain an understanding of the properties of this model, look at dr in the absence of randomness
dr = (r r) dt
Z
dr
(r r)
=
Z
dt
r (t) = r + k exp ( kt)
So controls the rate of exponential decay.
One of the disadvantages of the Vasicek model is that interest rates can become negative. The Cox Ingersoll
Ross (CIR) model is similar to the above SDE but is scaled with the interest rate:
drt = (r rt) dt +
p
rtdWt:
If rt ever gets close to zero, the amount of randomness decreases, i.e. di¤usion ! 0; therefore the drift
dominates, in particular the mean rate.
12](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-121-320.jpg)
![Producing Standardized Normal Random Variables
Consider the RAND() function in Excel that produces a uniformly distributed random number over 0 and
1; written Unif[0;1]: We can show that for a large number N,
lim
N!1
r
12
N
N
P
1
Unif[0;1]
N
2
N (0; 1) :
Introduce Ui to denote a uniformly distributed random variable over [0; 1] and sum up. Recall that
E [Ui] = 1
2
V [Ui] = 1
12
The mean is then
E
N
P
i=1
Ui = N=2
so subtract o¤ N=2; so we examine the variance of
N
P
1
Ui
N
2
V
N
P
1
Ui
N
2
=
N
P
1
V [Ui]
= N=12
As the variance is not 1, write
V
N
P
1
Ui
N
2
for some 2 R: Hence 2 N
12
= 1 which gives =
p
12=N which normalises the variance. Then we achieve
the result r
12
N
N
P
1
Ui
N
2
:
Rewrite as
N
P
1
Ui N 1
2
q
1
12
p
N
:
and for N ! 1 by the Central Limit Theorem we get N (0; 1)
13
Generating Correlated Normal Variables
Consider two uncorrelated standard Normal variables 1 and 2 from which we wish to form a correlated
pair 1; 2 ( N (0; 1)), such that E [ 1 2] = : The following scheme can be used
1. E [1] = E [2] = 0 ; E [2
1] = E [2
2] = 1 and E [12] = 0 (* 1; 2 are uncorrelated) :
2. Set 1 = 1 and 2 = 1 + 2 (i.e. a linear combination).
3. Now
E [ 1 2] = = E [1 ( 1 + 2)]
E [1 ( 1 + 2)] =
E 2
1 + E [12] = ! =
E 2
2 = 1 = E ( 1 + 2)2
= E 2
2
1 + 2
2
2 + 2 12
= 2
E 2
1 + 2
E 2
2 + 2 E [12] = 1
2
+ 2
= 1 ! =
p
1 2
4. This gives 1 = 1 and 2 = 1+
p
1 2 2 which are correlated standardized Normal variables.
14](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-122-320.jpg)
![Transition Probability Density Functions for Stochastic Di¤erential Equa-
tions
To match the mean and standard deviation of the trinomial model with the continuous-time random walk
we choose the following de…nitions for the probabilities
+
(y; t) =
1
2
t
y2
B2
(y; t) + A (y; t) y ;
(y; t) =
1
2
t
y2
B2
(y; t) A (y; t) y
We …rst note that the expected value is
+
( y) + ( y) + 1 +
(0)
= +
y
We already know that the mean and variance of the continuous time random walk given by
dy = A (y; t) dt + b (y; t) dW
is, in turn,
E [dy] = Adt
V [dy] = B2
dt:
So to match the mean requires
+
y = A t
The variance of the trinomial model is E [u2
] E2
[u] and hence becomes
( y)2 +
+ + 2
( y)2
= ( y)2 +
+ + 2
:
We now match the variances to get
( y)2 +
+ + 2
= B2
t
First equation gives
+
= + A t
y
which upon substituting into the second equation gives
( y)2
+ + +
2
= B2
t
where = A t
y
: This simpli…es to
2 + 2
= B2 t
( y)2
which rearranges to give
=
1
2
B2 t
( y)2 + 2
=
1
2
B2 t
( y)2 + A t
y
2
A t
y
=
1
2
t
( y)2 B2
+ A2
t A y
15
t is small compared with y and so
=
1
2
t
( y)2 B2
A y :
Then
+
= + A t
y
=
1
2
t
( y)2 B2
+ A y :
Note
+
+ ( y)2
= B2
t
16](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-123-320.jpg)







![about the eventual outcome ! of the three coin tosses. All one can say is that ! =
2 ; and ! 2 and so
F0 = f ; ;g.
Now de…ne the following two subsets of :
AU = fUUU; UUD; UDU; UDDg ; AD = fDUU; DUD; DDU; DDDg :
We see AU is the subset of outcomes where a Head appears on the …rst throw, AD is the subset of outcomes
where a Tail lands on the …rst throw. After the …rst trading period t = 1,(11am) we know whether the
initial move was an up move or down move. Hence
F1 = f ; ;; AU ; ADg
De…ne also
AUU = fUUU; UUDg ; AUD = fUDU; UDDg ;
ADU = fDUU; DUDg ; ADD = fDDU; DDDg
corresponding to the events that the …rst two coin tosses result in HH; HT; TH; TT respectively. This
is the information we have at the end of the 2nd trading period t = 2,(1 pm). This means at the end of
the second trading period we have accumulated increasing information. Hence
F2 = f ; ;; AU ; AD; AUU ; AUD; ADU ; ADD + all unions of theseg ;
which can be written as follows
F2 = f ; ;; AU ; AD; AUU ; AUD; ADU ; ADD
AUU [ ADU ; AUU [ ADD; AUD [ ADU ; AUD [ ADD
Ac
UU ; Ac
UD; Ac
DU ; Ac
DDg
We see
F0 F1 F2
Then F2 is a algebra which contains the information of the …rst two tosses of the information up to
time 2. This is because, if you know the outcome of the …rst two tosses, you can say whether the outcome
! 2 of all three tosses satis…es ! 2 A or ! =
2 A for each A 2 F2:
Similarly, F3 F; the set of all subsets of ; contains full information about the outcome of all three
tosses. The sequence of increasing algebras F = fF0; F1; F2; F3g is a …ltration.
Adapted Process A stochastic process St is said to be adapted to the …ltration Ft (or Ft measurable or
Ft adapted) if the value of S at time t is known given the information set Ft:
We place a probability measure P on f ; Fg : P is a special type of function, called a measure which
assigns probabilities to subsets (i.e. the outcomes); the theory also comes from Measure Theory. Whereas
cumulative density functions (CDF) are de…ned on intervals such as R; probability measures are de…ned
on general sets, giving greater power, generalisation and ‡
exibility. A probability measure P is a function
mapping P : F ! [0; 1] with the properties
(i) P ( ) = 1;
(ii) if A1; A2; :::: is a sequence of disjoint sets in F; then P (
S1
k=1 Ak) =
1
X
k=1
P (Ak) :
11
Example Recall the usual coin toss game with the earlier de…ned results. As the outcomes are equiprobable
the probability measure de…ned as P (!1) = 1
2
= P (!2) :
The interpretation is that for a set A 2F there is a probability in [0; 1] that the outcome of a random
experiment will lie in the set A: We think of P (A) as this probability. The A 2F is called an event. For
A 2F we can de…ne
P (A) :=
X
!2A
P (!) ; (*)
as A has …nitely many elements. Letting the probability of H on each coin toss be p 2 (0; 1) ; so that the
probability of T is q = 1 p. For each ! = (!1; !2; : : : !n) 2 we de…ne
P (!) := pNumber of H in !
qNumber of T in !
:
Then for each A 2F we de…ne P (A) according to ( ) :
In the …nite coin toss space, for each t 2 T let Ft be the algebra generated by the …rst t coin tosses.
This is a algebra which encapsulates the information one has if one observes the outcome of the …rst
t coin tosses (but not the full outcome ! of all n coin tosses). Then Ft is composed of all the sets A such
that Ft is indeed a algebra, and such that if the outcome of the …rst t coin tosses is known, then we
can say whether ! 2 A or ! =
2 A; for each A 2 Ft: The increasing sequence of algebras (Ft)t2T is an
example of a …ltration. We use this notation when working in continuous time.
When moving to continuous time we will write (Ft)t2[0;T] :
If we are concerned with developing a more measure theory based rigorous approach then working structures
such as algebras becomes more important - so we do not need to worry too much about this in our
…nancial mathematics setting.
We can compute the probability of any event. For instance,
P (AU ) = P (H on …rst toss) = P fUUU; UUD; UDU; UDDg
= p3
+ 2p2
q + pq2
= p;
and similarly P (AT ) = q: This agrees with the mathematics and our intuition.
Explanation of probability measure: If the number of basic events is very large we may prefer to
think of a continuous probability distribution. As the number of discrete events tends to in…nity, the
probability of any individual event usually tends to zero. In terms of random variables, the probability
that the random variable X takes a given value tends to zero.
So, the individual probabilities pi are no longer useful. Instead we have a probability density function p (x)
with the property that
Pr (x X x + dx) = p (x) dx
for any in…nitesimal interval of length dx (think of this as a limiting process starting with a small interval whos
It is also called a density because it is the probability of …nding X on an interval of length dx divided by
the length of the interval. Recall that the following are analogous
Z 1
1
p (x) dx = 1
X
i
pi = 1:
12](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-131-320.jpg)
![The (cumulative) distribution function of a random variable is de…ned by
P (x) = Pr (X x) :
It is an increasing function of x with P ( 1) = 0 and P (1) = 1; note that 0 P (x) 1: It is related
to the density function by
p (x) =
dP (x)
dx
provided that P (x) is di¤erentiable. Unlike P (x) ; p (x) may be unbounded or have singularities such as
delta functions.
P is the probability measure, a special type of function, called a measure, assigning probabilities to
subsets (i.e. the outcomes); the mathematics emanates from Measure Theory. Probability measures are
similar to cumulative density functions (CDF); the chief di¤erence is that where PDFs are de…ned on
intervals (e.g. R), probability measures are de…ned on general sets. We are now concerned with mapping
subsets on to [0; 1] : The following de…nition of the expectation has been used
E [h (X)] =
Z
R
h (x) p (x) dx
=
Z
R
h (x) dP (x)
We now write as a Lebesgue integral with respect to the measure P
EP
[h (X (!))] =
Z
h (!) P (d!) :
So integration is now done over the sample space (and not intervals).
If fWt : t 2 [0; T]g is a Brownian motion or any general stochastic process fSn : n = 0; :::; Ng. The proba-
bility space ( ; F; P) is the set of all paths (continuous functions) and P is the probability of each path.
Example Recall the usual coin toss game with the earlier de…ned results. As the outcomes are equiprobable
the probability measure de…ned as P (!1) = 1
2
= P (!2) :
There is a very powerful relation between expectations and probabilities. In our formula for the expectation,
choose f (X) to be the indicator function 1x2A for a subset A de…ned
1x2A =
1
0
if x 2 A
if x =
2 A
i.e. when we are in A; the indicator function returns 1.
The expectation of the indicator function of an event is the probability associated with this event:
E [1X2A] =
Z
1x2AdP
=
Z
A
dP+
Z
nA
dP
=
Z
A
dP
= P (A)
which is simply the probability that the outcome X 2 A:
13
Conditional Expectations
What makes a conditional expectation di¤erent (from an unconditional one) is information (just as in
the case of conditional probability). In our probability space, ( ; F; P) information is represented by the
…ltration F; hence a conditional expectation with respect to the (usual information) …ltration seems a
natural choice.
Y = E [Xj F]
is the expected value of the random variable conditional upon the …ltration set F: In general
In general Y will be a random variable
Y will be adapted to the …ltration F:
Conditional expectations have the following useful properties: If X; Y are integrable random variables and
a; b are constants then
1. Linearity:
E [aX + bY j F] = aE [Xj F] + bE [Y j F]
2. Tower Property (i.e. Iterated Expectations): if G F
E [E [Xj F]j G] = E [Xj G] :
This property states that if taking iterated expectations with respect to several levels of information,
we may as well take a single expectation subject to the smallest set of available information. The
special case is
E [E [Xj F]] = E [X] :
3. Taking out what is known: X is F adapted, then the value of X is know once we know F.
Therefore
E [Xj F] = X:
and hence by extension if X is F measurable, but not Y then
E [XY j F] = XE [Y j F] :
4. Independence: X is independent of F; then knowing F is of no use in predicting X
E [Xj F] = E [X] :
5. Positivity: If X 0 then E [Xj F] 0:
6. Jensen’
s inequality: Let f be a convex function, then
f (E [Xj F]) fE [f (X)j F]
14](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-132-320.jpg)

![Applied Stochastic Calculus
Stochastic Process
The evolution of …nancial assets is random and depends on time. They are examples of stochastic processes
which are random variables indexed (parameterized) with time.
If the movement of an asset is discrete it is called a random walk. A continuous movement is called a
di¤usion process. We will consider the asset price dynamics to exhibit continuous behaviour and each
random path traced out is called a realization.
We need a de…nition and set of properties for the randomness observed in an asset price realization, which
will be Brownian Motion.
This is named after the Scottish Botanist who in 1827, while examining grains of pollen of the plant Clarkia
pulchella suspended in water under a microscope, observed minute particles, ejected from the pollen grains,
executing a continuous …dgety motion. In 1900 Louis Bachelier was the …rst person to model the share price
movement using Brownian motion as part of his PhD. Five years later Einstein used Brownian motion to
study di¤usions. In 1920 Norbert Wiener, a mathematician at MIT provided a mathematical construction
of Brownian motion together with numerous results about the properties of Brownian motion - in fact he
was the …rst to show that Brownian motion exists and is a well de…ned entity! Hence Wiener process is
also used as a name for this.
Construction of Brownian Motion and properties
We construct Brownian motion using a simple symmetric random walk. De…ne a random variable
Zi =
1
1
if H
if T
Let
Xn =
n
X
i=1
Zi
which de…nes the marker’
s position after the nth
toss of the game. This is conditional upon the marker
starting at position X = 0; so at each time-step moves one unit either to the left or right with equal
probability. Hence the distribution is binomial with
mean =
1
2
(+1) +
1
2
( 1) = 0
variance =
1
2
(+1)2
+
1
2
( 1)2
= 1
This can be approximated to a Normal distribution due to the Central Limit Theorem.
Is there a continuous time limit to this discrete random walk? Let’
s introduce time dependency. Take a
time period for our walk, say [0; t] and perform N steps. So we partition [0; t] into N time intervals, so
each step takes
t = t=N:
Speed up this random walk so let N ! 1: The problem with the original step sizes of 1 gives the variance
that is in…nite. We rescale the space step, keeping in mind the central limit theorem. Let
Y = N Z
17
for some N to be found, and let XN
n ; n = 0; :::; N such that XN
0 = 0; be the path/trajectory of the
random walk with steps of size N :
Thus we now have
E XN
n = 0; 8n
and
V XN
n = E
h
XN
n
2
i
= NE Y 2
= N 2
N E Z2
= N 2
N
1
2
+
1
2
=
t
t
2
N :
Obviously we must have 2
N = t = O (1) : Choosing 2
N = t = 1 gives
E X2
= V [X] = t:
As N ! 1; the symmetric random walk
n
XN
[tN]; t 2 [0; 1)
o
converges to a standard Brownian motion
fWt; t 2 [0; 1)g : So Wt N (0; dt) :
With t = n t we have
dWt
dt
= lim
t!0
Wt+ t Wt
t
! 1:
Quadratic Variation
Consider a function f (t) on the interval [0; T] : Discretising by writing t = idt and dt = T=N we can de…ne
the variation Vn
of f for n = 1; 2; :: as
Vn
[f] = lim
N!1
N 1
X
i=0
jfti+1 fti
jn
:
Of interest is the quadratic variation
Q [f] = lim
N!1
N 1
X
i=0
(fti+1 fti
)2
:
If f (t) has more than a …nite number of jumps or a singularity then Q [f] = 1:
For a Brownian motion on [0; T] we have
Q [Wt] = lim
N!1
N 1
X
i=0
(Wti+1 Wti
)2
= lim
N!1
N 1
X
i=0
(W ((i + 1) dt) W (idt))2
= lim
N!1
N 1
X
i=0
dt = lim
N!1
N 1
X
i=0
T
N
= T:
18](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-134-320.jpg)
![Suppose that f (t) is a di¤erentiable function on [0; T] : Then to leading order, we have
fti+1 fti
= f ((i + 1) dt) f (idt) f0
(ti) dt
so,
Q [f] lim
N!1
N 1
X
i=0
(f0
(ti) dt)
2
lim
N!1
dt
N 1
X
i=0
(f0
(ti))
2
dt
lim
N!1
T
N
Z T
0
(f0
(ti))
2
dt
= 0:
The quadratic variation of f (t) is zero. This argument remains valid even if f0
(t) has a …nite number of
jump discontinuities. Thus a Brownian motion, Wt; has at worst a …nite number of discontinuities, but
an in…nite number of discontinuities in its derivative, W0
t : It is continuous but not di¤erentiable, almost
everywhere. For us the important result is
dW2
t = dt
or more importantly we can write (up to mean square limit)
E dW2
t = dt:
Properties of a Wiener Process/Brownian motion
A stochastic process fWt : t 2 R+g is de…ned to be Brownian motion (or a Wiener process ) if
Brownian motion starts at zero, i.e. W0 = 0 (with probability one), i.e. P (W0 = 0) = 1:
Continuity - paths of Wt are continuous (no jumps) with probability 1. Di¤erentiable nowhere.
Brownian motion has independent Gaussian increments, with zero mean and variance equal to the
temporal extension of the increment. That is for each t 0 and s 0, Wt Ws is normal with mean
0 and variance jt sj ;
i.e.
Wt Ws N (0; jt sj) :
Coin tosses are Binomial, but due to a large number and the Central Limit Theorem we have a
distribution that is normal. Wt Ws has a pdf given by
p (x) =
1
p
2 jt sj
exp
x2
2 jt sj
More speci…cally Wt+s Wt is independent of Wt: This means if
0 t0 t1 t2 :::::
dW1 = W1 W0 is independent of dW2 = W2 W1
dW3 = W3 W2 is independent of dW4 = W4 W3
and so on
19
Also called standard Brownian motion if the above properties hold. More importantly is the result
(in stochastic di¤erential equations)
dW = Wt+dt Wt N (0; dt)
Brownian motion has stationary increments. A stochastic process (Xt)t 0 is said to be stationary if
Xt has the same distribution as Xt+h for any h 0. This can be checked by de…ning the increment
process I = (It)t 0 by
It := Wt+h Wt:
Then It N (0; h) ; and It+h = Wt+2h Wt+h N (0; h) have the same distribution. This is
equivalent to saying that the process (Wt+h Wt)h 0 has the same distribution 8t:
If we want to be a little more pedantic then we can write some of the properties above as
Wt NP
(0; t)
i.e. Wt is normally distributed under the probability measure P:
The covariance function for a Brownian motion at di¤erent times. Let can be calculated as follows.
If t s;
E [WtWs] = E (Wt Ws) Ws + W2
s
= E [Wt Ws]
| {z }
N(0;jt sj)
E [Ws] + E W2
s
= (0) 0 + E W2
s
= s
The …rst term on the second line follows from independence of increments. Similarly, if s t; then
E [WtWs] = t and it follows that
E [WtWs] = min ft; sg :
Brownian motion is a Martingale. Martingales are very important in …nance.
Think back to the way the betting game has been constructed. Martingales are essentially stochastic
processes that are meant to capture the concept of a fair game in the setting of a gambling environment
and thus there exists a rich history in the modelling of gambling games. Although this is a key example
area for us, they nevertheless are present in numerous application areas of stochastic processes.
Before discussing the Martingale property of Brownian motion formally, some general background infor-
mation.
A stochastic process fXn : 0 n 1g is called a P martingale with respect to the information …ltra-
tion Fn; and probability distribution P; if the following two properties are satis…ed
P1 EP
n [jXnj] 1 8 n 0
P2 EP
n [Xn+mj Fn] = Xn; 8 n; m 0
20](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-135-320.jpg)
![The …rst property is simply a technical integrability condition (…ne print), i.e. the expected value of the
absolute value of Xn must be …nite for all n: Such a …niteness condition appears whenever integrals de…ned
over R are used (think back to the properties of the Fourier Transform for example).
The second property is the one of key importance. This is another expectation result and states that the
expected value of Xn+m given Fn is equal to Xn for all non-negative n and m:
The symbol Fn denotes the information set called a …ltration and is the ‡
ow of information associated
with a stochastic process. This is simply the information we have in our model at time n: It is recognising
that at time n we have already observed all the information Fn = (X0; X1; ::::; Xn) :
So the expected value at any time in the future is equal to its current value - the information held at this
point it is the best forecast. Hence the importance of Martingales in modelling fair games. This property
is modelling a fair game, our future payo¤ is equal to the current wealth.
It is also common to use t to depict time
EP
t [MT j Ft] = Mt; t T
Taking expectations of both sides gives
Et [MT ] = Et [Mt] ; t T
so martingales have constant mean.
Now replacing the equality in P2 with an inequality, two further important results are obtained. A process
Mt which has
EP
t [MT j Ft] Mt
is called a submartingale and if it has
EP
t [MT j Ft] Mt
is called a supermartingale.
Using the earlier betting game as an example (where probability of a win or a loss was 1
2
)
submartingale - gambler wins money on average P (H) 1
2
supermartingale- gambler loses money on average P (H) 1
2
The above de…nitions tell us that every martingale is also a submartingale and a supermartingale. The
converse is also true.
For a Brownian motion, again where t T
EP
t [WT ] = EP
t [WT Wt + Wt]
= EP
t [WT Wt]
| {z }
N(0;jT tj)
+ EP
t [Wt]
The next step is important - and requires a little subtlety
The …rst term is zero. We are taking expectations at time t hence Wt is known, i.e. EP
t [Wt] = Wt: So
EP
t [WT ] = Wt:
21
Another important property of Brownian motion is that of a Markov process. That is if you observe the
path of the B.M from 0 to t and want to estimate WT where T t then the only relevant information
for predicting future dynamics is the value of Wt: That is, the past history is fully re‡
ected in the present
value. So the conditional distribution of Wt given up to t T depends only on what we know at t (latest
information).
Markov is also called memoryless as it is a stochastic process in which the distribution of future states
depends only on the present state and not on how it arrived there. It doesn’
t matter how you arrived at
your destination.
Let us look at an example. Consider the earlier random walk Sn given by
Sn =
n
X
i=1
Xi
which de…ned the winnings after n ‡
ips of the coin. The Xi’
s are IID with mean : now de…ne
Mn = Sn n :
We will demonstrate that Mn is a Martingale.
Start by writing
En [Mn+mj Fn] = En [Sn+m (n + m) ] :
So this is an expectation conditional on information at time n: Now work on the right hand side.
= En
n+m
X
i=1
Xi (n + m)
#
= En
n
X
i=1
Xi +
n+m
X
i=n+1
Xi
#
(n + m)
=
n
X
i=1
Xi + En
n+m
X
i=n+1
Xi
#
(n + m)
=
n
X
i=1
Xi + mEn [Xi] (n + m) =
n
X
i=1
Xi + m (n + m)
=
n
X
i=1
Xi n = Sn n
En [Mn+m] = Mn:
22](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-136-320.jpg)

![or more conveniently
dS = Sdt + SdW
then as dW2
= dt;
dS2
= ( Sdt + SdW)2
= 2
S2
dW2
+ 2 S2
dtdW + 2
S2
dt2
dS2
= 2
S2
dt + :::
In the limit dt ! 0;
dS2
= 2
S2
dt
This leads to Itô lemma for Geometric Brownian motion (GBM).
If V = V (t; S) ; is a function of S and t, then Taylor’
s theorem states
dV =
@V
@t
dt +
@V
@S
dS +
1
2
@2
V
@S2
dS2
so if S follows GBM,
dS
S
= dt + dW
then dS2
= 2
S2
dt and we obtain
Itô lemma for Geometric Brownian motion;
dV =
@V
@t
+ S
@V
@S
+
1
2
2
S2 @2
V
@S2
dt + S
@V
@S
dW
where the partial derivatives are evaluated at S and t:
If V = V (S) then we obtain the shortened version of Itô;
dV = S
dV
dS
+
1
2
2
S2 d2
V
dS2
dt + S
dV
dS
dW
Following on from the earlier example, S (t) = eW(t)
; for which
dS =
1
2
Sdt + SdW
we …nd that we can solve the SDE
dS
S
= dt + dW:
If we put S (t) = Aeat+bW(t)
then from the earlier form of Itô’
s lemma we have
dS = aS +
1
2
b2
S dt + bSdW
or
dS
S
= a +
1
2
b2
dt + bdW
comparing with
dS
S
= dt + dW
gives
b = ; a =
1
2
2
25
Another way to arrive at the same result is to use Itô for GBM. Using f (S) = log S (t) with
df = S
@f
@S
+
1
2
2
S2 @2
f
@S2
dt + S
@f
@S
dW
gives
d (log S) = S
@
@S
(log S) +
1
2
2
S2 @2
@S2
(log S) dt + S
@
@S
(log S) dW
=
1
2
2
dt + dW
and hence
Z t
0
d (log S ( )) =
Z t
0
1
2
2
d +
Z t
0
dW
log
S (t)
S (0)
=
1
2
2
t + W (t)
Taking exponentials and rearranging gives the earlier result. We have also used W (0) = 0:
Itô multiplication table:
dt dW
dt dt2
= 0 dtdW = 0
dW dWdt = 0 dW2
= dt
Exercise: Consider the Itô integral of the form
Z T
0
f (t; W (t)) dW (t) = lim
N!1
N 1
X
i=0
f (ti; Wi) (Wi+1 Wi) :
The interval [0; T] is divided into N partitions with end points
t0 = 0 t1 t2 :::::: tN 1 tN = T;
where the length of an interval ti+1 ti tends to zero as N ! 1:
We know from Itô’
s lemma that
4
Z T
0
W3
(t) dW (t) = W4
(T) W4
(0) 6
Z T
0
W2
(t) dt
Show from the de…nition of the Itô integral that the result can also be found by initially writing the integral
4
Z T
0
W3
dX = lim
N!1
4
N 1
X
i=0
W3
i (Wi+1 Wi)
Hint: use 4b3
(a b) = a4
b4
4b (a b)3
6b2
(a b)2
(a b)4
.
26](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-138-320.jpg)
![Di¤usion Process
G is called a di¤usion process if
dG (t) = A (G; t) dt + B (G; t) dW (t) (1)
This is also an example of a Stochastic Di¤erential Equation (SDE) for the process G and consists of two
components:
1. A (G;t) dt is deterministic –coe¢ cient of dt is known as the drift of the process.
2. B (G; t) dW is random – coe¢ cient of dW is known as the di¤usion or volatility of the process.
We say G evolves according to (or follows) this process.
For example
dG (t) = (G (t) + G (t 1)) dt + dW (t)
is not a di¤usion (although it is a SDE)
A 0 and B 1 reverts the process back to Brownian motion
Called time-homogeneous if A and B are not dependent on t:
dG 2
= B2
dt:
We say (1) is a SDE for the process G or a Random Walk for dG:
The di¤usion (1) can be written in integral form as
G (t) = G (0) +
Z t
0
A (G; ) d +
Z t
0
B (G; ) dW ( )
Remark: A di¤usion G is a Markov process if - once the present state G (t) = g is given, the past
fG ( ) ; tg is irrelevant to the future dynamics.
We have seen that Brownian motion can take on negative values so its direct use for modelling stock prices
is unsuitable. Instead a non-negative variation of Brownian motion called geometric Brownian motion
(GBM) is used
If for example we have a di¤usion G (t)
dG = Gdt + GdW (2)
then the drift is A (G; t) = G and di¤usion is B (G; t) = G:
The process (2) is also called Geometric Brownian Motion (GBM).
Brownian motion W (t) is used as a basis for a wide variety of models. Consider a pricing process
fS (t) : t 2 R+g: we can model its instantaneous change dS by a SDE
dS = a (S; t) dt + b (S; t) dW (3)
By choosing di¤erent coe¢ cients a and b we can have various properties for the di¤usion process.
A very popular …nance model for generating asset prices is the GBM model given by (2). The instantaneous
return on a stock S (t) is a constant coe¢ cient SDE
dS
S
= dt + dW (4)
where and are the return’
s drift and volatility, respectively.
27
An Extension of Itô’
s Lemma (2D)
Now suppose we have a function V = V (S; t) where S is a process which evolves according to (4) : If
S ! S + dS; t ! t + dt then a natural question to ask is what is the jump in V ? To answer this we
return to Taylor, which gives
V (S + dS; t + dt)
= V (S; t) +
@V
@t
dt +
@V
@S
dS +
1
2
@2
V
@S2
dS2
+ O dS3
; dt2
So S follows
dS = Sdt + SdW
Remember that
E (dW) = 0; dW2
= dt
we only work to O (dt) - anything smaller we ignore and we also know that
dS2
= 2
S2
dt
So the change dV when V (S; t) ! V (S + dS; t + dt) is given by
dV =
@V
@t
dt +
@V
@S
[S dt + S dW] +
1
2
2
S2 @2
V
@S2
dt
Re-arranging to have the standard form of a SDE dG = a (G; t) dt + b (G; t) dW gives
dV =
@V
@t
+ S
@V
@S
+
1
2
2
S2 @2
V
@S2
dt + S
@V
@S
dW. (5)
This is Itô’
s Formula in two dimensions.
Naturally if V = V (S) then (5) simpli…es to the shorter version
dV = S
dV
dS
+
1
2
2
S2 d2
V
dS2
dt + S
dV
dS
dW. (6)
Further Examples
In the following cases S evolves according to GBM.
Given V = t2
S3
obtain the SDE for V; i.e. dV: So we calculate the following terms
@V
@t
= 2tS3
;
@V
@S
= 3t2
S2
!
@2
V
@S2
= 6t2
S:
We now substitute these into (5) to obtain
dV = 2tS3
+ 3 t2
S3
+ 3 2
S3
t2
dt + 3 t2
S3
dW.
Now consider the example V = exp (tS)
28](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-139-320.jpg)
![Again, function of 2 variables. So
@V
@t
= S exp (tS) = SV
@V
@S
= t exp (tS) = tV
@2
V
@S2
= t2
V
Substitute into (5) to get
dV = V S + tS +
1
2
2
S2
t2
dt + ( StV ) dW:
Not usually possible to write the SDE in terms of V but if you can do so - do not struggle to …nd a
relation if it does not exist. Always works for exponentials.
One more example: That is S (t) evolves according to GBM and V = V (S) = Sn
: So use
dV = S
dV
dS
+
1
2
2
S2 d2
V
dS2
dt + S
dV
dS
dW.
V 0
(S) = nSn 1
! V 00
(S) = n (n 1) Sn 2
Therefore Itô gives us dV =
SnSn 1
+
1
2
2
S2
n (n 1) Sn 2
dt + SnSn 1
dW
dV = nSn
+
1
2
2
n (n 1) Sn
dt + [ nSn
] dW
Now we know V (S) = Sn
; which allows us to write
dV = V n +
1
2
2
n (n 1) dt + [ n] V dW
with drift = V n + 1
2
2
n (n 1) and di¤usion = nV:
29
Important Cases - Equities and Interest Rates
If we now consider S which follows a lognormal random walk, i.e. V = log(S) then substituting into (6)
gives
d ((log S)) =
1
2
2
dt + dW
Integrating both sides over a given time horizon ( between t0 and T )
Z T
t0
d ((log S)) =
Z T
t0
1
2
2
dt +
Z T
t0
dW (T t0)
we obtain
log
S (T)
S (t0)
=
1
2
2
(T t0) + (W (T) W (t0))
Assuming at t0 = 0, W (0) = 0 and S (0) = S0 the exact solution becomes
ST = S0 exp
1
2
2
T +
p
T . (7)
(7) is of particular interest when considering the pricing of a simple European option due to its non path
dependence. Stock prices cannot become negative, so we allow S, a non-dividend paying stock to evolve
according to the lognormal process given above - and acts as the starting point for the Black-Scholes
framework.
However is replaced by the risk-free interest rate r in (7) and the introduction of the risk-neutral measure
- in particular the Monte Carlo method for option pricing.
Interest rates exhibit a variety of dynamics that are distinct from stock prices, requiring the development
of speci…c models to include behaviour such as return to equilibrium, boundedness and positivity. Here we
consider another important example of a SDE, put forward by Vasicek in 1977. This model has a mean
reverting Ornstein-Uhlenbeck process for the short rate and is used for generating interest rates, given by
drt = ( rt) dt + dWt. (8)
So drift is ( rt) and volatility given by .
refers to the speed of reversion or simply the speed. (= r) denotes the mean rate, and we can rewrite
this random walk (7) for drt as
drt = (rt r) dt + dWt.
The dimensions of are 1=time, hence 1= has the dimensions of time (years). For example a rate that has
speed = 3 takes one third of a year to revert back to the mean, i.e. 4 months. = 52 means 1= = 1=52
years i.e. 1 week to mean revert (hence very rapid).
By setting Xt = rt r, Xt is a solution of
dXt = Xtdt + dWt; X0 = ; (9)
hence it follows that Xt is an Ornstein-Uhlenbeck process and an analytic solution for this equation exists.
(9) can be written as dXt + Xtdt = dWt:
30](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-140-320.jpg)
![Multiply both sides by an integrating factor e t
e t
(dXt + Xt) dt = e t
dWt
d e t
Xt = e t
dWt
Integrating over [0; t] gives
Z t
0
d (e s
Xs) =
Z t
0
e s
dWs
e s
Xsjt
0 =
Z t
0
e s
dWs ! e t
Xt X0 =
Z t
0
e s
dWs
Xt = e t
+
Z t
0
e (s t)
dWs: (10)
By using integration by parts, i.e.
Z
v du = uv
Z
u dv we can simplify (10).
u = Ws
v = e (s t)
! dv = e (s t)
ds
Therefore Z t
0
e (s t)
dWs = Wt
Z t
0
e (s t)
Ws ds
and we can write (10) as
Xt = e t
+ Wt
Z t
0
e (s t)
Ws ds
allowing numerical treatment for the integral term.
Leaving the result in the form of (10) allows the calculation of the mean, variance and other moments.
Start with the expected value E [Xt] =
E [Xt] = E e t
+
Z t
0
e (s t)
dWs
= E e t
+ E
Z t
0
e (s t)
dWs
= e t
+
Z t
0
e (s t)
E [dWs]
Recall that Brownian motion is a Martingale; the Itô integral is a Martingale, hence
E [Xt] = e t
To calculate the variance we have V [Xt] = E [X2
t ] E2
[Xt]
= E
e t
+
Z t
0
e (s t)
dWs
2
#
2
e 2 t
= E 2
e 2 t
+ 2
E
Z t
0
e (s t)
dWs
2
#
+ 2 e t
E
Z t
0
e (s t)
dWs
| {z }
Itô integral
2
e 2 t
= 2
E
Z t
0
e (s t)
dWs
2
#
31
Now use Itô’
s Isometry
E
Z t
0
YsdWs
2
#
=E
Z t
0
Y 2
s ds ;
So
V [Xt] = 2
E
Z t
0
e2 (s t)
ds
=
2
2
e2 (s t) t
0
=
2
2
1 e 2 t
Returning to the integral in (10) Z t
0
e (s t)
dWs
let’
s use the stochatsic integral formula to verify the result. Recall
Z t
0
@f
@W
dW = f (t; Wt) f (0; W0)
Z t
0
@f
@s
+ 1
2
@2f
@W2 ds
so @f
@W
e (s t)
=) f = e (s t)
Ws; @f
@s
= e (s t)
Ws; @2f
@W2 = 0
Z t
0
e (s t)
dWs = Wt 0
Z t
0
e (s t)
Ws + 1
2
0 ds
= Wt
Z t
0
e (s t)
Wsds:
We have used an integrating factor to obtain a solution of the Ornstein Uhlenbeck process. Let’
s look at
d (e t
Ut) by using Itô. Consider a function V (t; Ut) where dUt = Utdt + dWt; then
dV =
@V
@t
U
@V
@U
+
1
2
2 @2
V
@U2
dt +
@V
@U
dW
d e t
U =
@
@t
e t
U U
@
@U
e t
U +
1
2
2 @2
@U2
e t
U dt +
@
@U
e t
U dW
= e t
U Ue t
dt + e t
dW
= e t
dW
32](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-141-320.jpg)
![Example: The Ornstein-Uhlenbeck process satis…es the spot rate SDE given by
dXt = ( Xt) dt + dWt; X0 = x;
where ; and are constants. Solve this SDE by setting Yt = e t
Xt and using Itô’
s lemma to show that
Xt = + (x ) e t
+
Z t
0
e (t s)
dWs:
First write Itô for Yt given dXt = A (Xt; t) dt + B (Xt; t) dWt
dYt =
@Yt
@t
+ A (Xt; t)
@Yt
@Xt
+ 1
2
B2
(Xt; t)
@2
Yt
@X2
t
dt + B (Xt; t)
@Yt
@Xt
dWt
=
@Yt
@t
+ ( Xt)
@Yt
@Xt
+ 1
2
2 @2
Yt
@X2
t
dt +
@Yt
@Xt
dWt
@Yt
@t
= e t
Xt;
@Yt
@Xt
= e t
;
@2
Yt
@X2
t
= 0:
d e t
Xt = e t
Xt + ( Xt) e t
dt + e t
dWt
= e t
dt + e t
dWt
Z t
0
d (e s
Xs) =
Z t
0
e s
ds +
Z t
0
e s
dWs
e t
Xt x = e t
+
Z t
0
e s
dWs
Xt = xe t
+ e t
+ e t
Z t
0
e s
dWs
Xt = + (x ) e t
+
Z t
0
e (t s)
dWs:
Consider
drt = ( rt) dt + dWt;
and show by suitable integration for s t
rt = rse (t s)
+ 1 e (t s)
+
Z t
s
e (t u)
dWu:
The lower limit gives us an initial condition at time s t: Expand d (e t
rt)
d e t
rt = e t
rtdt + e t
drt
= e t
( dt + dWt)
Now integrate both sides over [s; t] to give for each s t
Z t
s
d (e u
ru) =
Z t
s
e u
du +
Z t
s
e u
dWu
e t
rt e s
rs = e t
e s
+
Z t
s
e u
dWu
33
rearranging and dividing through by e t
rt = e (t s)
rs + e (t s)
+ e t
Z t
s
e s
dWu
rt = e (t s)
rs + 1 e (t s)
+
Z t
s
e (t u)
dWu
so that rt conditional upon rs is normally distributed with mean and variance given by
E [rtj rs] = e (t s)
rs + 1 e (t s)
V [rtj rs] =
2
2
1 e 2 (t s)
We note that as t ! 1; the mean and variance become in turn
E [rtj rs] =
V [rtj rs] =
2
2
Example: Given U = log Y; where Y satis…es the di¤usion process
dY =
1
2Y
dt + dW
Y (0) = Y0
use Itô’
s lemma to …nd the SDE satis…ed by U:
Since U = U (Y ) with dY = a (Y; t) dt + b (Y; t) dW; we can write
dU = a (Y; t)
dU
dY
+
1
2
b2
(Y; t)
d2
U
dY 2
dt + b (Y; t)
dU
dY
dW
Now U = log(Y ) so dU
dY
= 1;
Y
d2U
dY 2 = 1
Y 2 and substituting in
dU =
1
2Y
1
Y
+
1
2
(1)2 1
Y 2
dt +
1
Y
dW
dU = e U
dW
Example: Consider the stochastic volatility model
d
p
v =
p
v dt + dW
where v is the variance. Show that
dv = 2
+ 2
p
v 2 v dt + 2
p
vdW
Setting the variable X =
p
v giving dX = ( X)
| {z }
A
dt + |{z}
B
dW: We now require a SDE for dY; where
Y = X2
: So dv =
dY = A
dY
dX
+
1
2
B2 d2
Y
dX2
dt + B
dY
dX
dW
= ( X) (2X) +
1
2
2
2 dt + 2XdW
= 2 X 2 X2
+ 2
dt + 2
p
vdW
= 2
+ 2
p
v 2 v dt + 2
p
vdW
34](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-142-320.jpg)
![(Harder) Example: Consider the dynamics of a non-traded asset St given by
dSt
St
= ( log St) dt + dWt
where the constants ; 0: If T t; show that
log ST = e (T t)
log St +
1
2
2
1 e (T t)
+
Z T
t
e (T s)
dWs:
Hence show that
log ST N e (T t)
log St +
1
2
2
1 e (T t)
; 2 1 e 2 (T t)
2
Writing Itô for the SDE where f = f (St) gives
df = ( log St) St
df
dS
+ 1
2
2
S2
t
d2
f
dS2
dt + St
df
dS
dWt:
Hence if f (St) = log St then
d (log St) = ( log St) 1
2
2
dt + dWt
=
1
2
2
log St dt + dWt
= (log St ) dt + dWt
where = 1
2
2
: Going back to
df = (f ) dt + dWt
and now write xt = f which gives dxt = df and we are left with an Ornstein-Uhlenbeck process
dxt = xtdt + dWt:
Following the earlier integrating factor method gives
d e t
xt = e t
dWt
Z T
t
d (e s
xs) =
Z T
t
e s
dWs
xT = e (T t)
xt +
Z T
t
e (T s)
dWs:
Now replace these terms with the original variables and parameters
log ST
1
2
2
= e (T t)
log ST
1
2
2
+
Z T
t
e (T s)
dWs;
which upon rearranging and factorising gives
log ST = e (T t)
log ST +
1
2
2
1 e (T t)
+
Z T
t
e (T s)
dWs:
35
Now consider E [log ST ] =
e (T t)
log ST +
1
2
2
1 e (T t)
+ E
Z T
t
e (T s)
dWs
= e (T t)
log ST +
1
2
2
1 e (T t)
Recall V [aX + b] = a2
V [X]. So write V [log ST ] =
V e (T t)
log ST +
1
2
2
1 e (T t)
+
Z T
t
e (T s)
dWs
= V e (T t)
log ST +
1
2
2
1 e (T t)
| {z }
=0
+ V
Z T
t
e (T s)
dWs
= 2
V
Z T
t
e (T s)
dWs = 2
E
Z T
t
e (T s)
dWs
2
#
because we have already obtained from the expectation that E
Z T
t
e (T s)
dWs = 0:
Now use Itô’
s Isometry, i.e.
E
Z t
0
YsdXs
2
#
=E
Z t
0
Y 2
s ds ;
V [log ST ] = 2
E
Z T
t
e (T s)
dWs
2
#
= 2
E
Z T
t
e 2 (T s)
ds
= 2
E
1
2
e 2 (T s)
T
t
#
=
2
2
1 e 2 (T t)
Hence veri…ed.
Example: Consider the SDE for the variance process v
dv = (m ) dt + dWt;
where v = 2
: ; ; m are constants. Using Itô’
s lemma, show that the volatility satis…es the SDE
d = a ( ; t) dt + b ( ; t) dWt;
where the precise form of a ( ; t) and b ( ; t) should be given.
Consider the stochastic volatility model
dv = m
p
v dt +
p
vdWt
36](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-143-320.jpg)

![Another common form is
d
X
Y
=
X
Y
dX
X
dY
Y
dXdY
XY
+
dY
Y
2
!
As an example suppose we have
dS1 = 0:1dt + 0:2dW
(1)
t ;
dS2 = 0:05dt + 0:1dW
(2)
t ;
= 0:4
d
S1
S2
= X
1
Y Y
X
Y 2
+ 2
Y
X
Y 3 X Y
1
Y 2
dt + X
1
Y
dW
(1)
t Y
X
Y 2
dW
(2)
t
where
X = 0:1; Y = 0:05
X = 0:2; Y = 0:1
d
S1
S2
=
0:1
S2
0:05
S1
S2
2
+ 0:01
S1
S3
2
0:008
1
S2
2
dt + 0:2
1
S2
dW
(1)
t 0:1
S1
S2
2
dW
(2)
t
Producing Standardized Normal Random Variables
Consider the RAND() function in Excel that produces a uniformly distributed random number over 0 and
1; written Unif[0;1]: We can show that for a large number N,
lim
N!1
r
12
N
N
P
1
U (0; 1) N
2
N (0; 1) :
Introduce Ui to denote a uniformly distributed random variable over [0; 1] and sum up. Recall that
E [Ui] = 1
2
V [Ui] = 1
12
The mean is then
E
N
P
i=1
Ui = N=2
so subtract o¤ N=2; so we examine the variance of
N
P
1
Ui
N
2
V
N
P
1
Ui
N
2
=
N
P
1
V [Ui]
= N=12
As the variance is not 1, write
V
N
P
1
Ui
N
2
for some 2 R: Hence 2 N
12
= 1 which gives =
p
12=N which normalises the variance. Then we achieve
the result r
12
N
N
P
1
Ui
N
2
:
39
Rewrite as
N
P
1
Ui N 1
2
q
1
12
p
N
:
and for N ! 1 by the Central Limit Theorem we get N (0; 1).
Generating Correlated Normal Variables
Consider two uncorrelated standard Normal variables 1 and 2 from which we wish to form a correlated
pair 1; 2 ( N (0; 1)), such that E [ 1 2] = : The following scheme can be used
1. E [1] = E [2] = 0 ; E [2
1] = E [2
2] = 1 and E [12] = 0 (* 1; 2 are uncorrelated) :
2. Set 1 = 1 and 2 = 1 + 2 (i.e. a linear combination).
3. Now
E [ 1 2] = = E [1 ( 1 + 2)]
E [1 ( 1 + 2)] =
E 2
1 + E [12] = ! =
E 2
2 = 1 = E ( 1 + 2)2
= E 2
2
1 + 2
2
2 + 2 12
= 2
E 2
1 + 2
E 2
2 + 2 E [12] = 1
2
+ 2
= 1 ! =
p
1 2
4. This gives 1 = 1 and 2 = 1+
p
1 2 2 which are correlated standardized Normal variables.
40](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-145-320.jpg)

![3
b) p (q r) (p q) r
4) Ley de distributividad a) p (q r) (p q) (p r)
c) p (q r) (p q) (p r)
5) Ley de idempotencia a) p p p
b) p p p
6) Ley del elemento neutro a) p F0 p
b) p T0 p
7) Leyes de De Morgan a) (p q) p q
b) (p q) p q
8) Ley del inverso a) p p T0
b) p p F0
9) Ley de dominancia a) p T0 T0
b) p F0 F0
10)Ley de absorción a) p (p q) p
b) p (p q) p
Dual de S: Sea S una proposición. Si S no contiene conectivas lógicas distintas de y entonces el dual de
S (S
d
), se obtiene de reemplazar en S todos los () por () y todas las T0 (F0) por F0 (T0).
Sean s y t dos proposiciones tales que s t, entonces s
d
t
d
.
Recíproca: (q p) es la recíproca de (p q)
Contra-recíproca: (q p) es la contra-recíproca de (p q)
Inversa: (p q) es la inversa de (p q)
3. Reglas de inferencia
Modus ponens o Modus ponendo ponens
p q
p
q
Modus tollens o Modus tollendo tollens
p q
q
p
4. Lógica de predicados
Función proposicional: expresión que contiene una o más variables que al ser sustituidas por elementos del
universo dan origen a una proposición.
Universo: Son las ciertas opciones “permisibles” que podré reemplazar por la variable.
Cuantificador universal: proposición que es verdadera para todos los valores de en el universo.
Cuantificador existencial: proposición en que existe un elemento del universo tal que la función
proposicional es verdadera.
5. Teoría de conjuntos
Conjunto de partes: dado un conjunto A, p(A) es el conjunto formado por todos los subconjuntos de A,
incluídos A y . Si A tiene elementos, p(A) tendrá elementos. Ejemplo:
Negación de proposiciones cuantificadas:
[x p(x)] x p(x)
[x p(x)] x p(x)
x [p(x) q(x)] x p(x) x q(x)
x [p(x) q(x)] x p(x) x q(x)
x [p(x) q(x)] x p(x) x q(x)
x p(x) x q(x) x [p(x) q(x)]
x [p(x) q(x)] ≠ x p(x) q(x)
4
Pertenencia: un elemento “pertenece” a un conjunto.
Inclusión: un conjunto está “incluido” en un conjunto.
Operaciones entre conjuntos:
Unión:
Intersección:
Diferencia:
Diferencia simétrica:
Complemento:
Leyes del álgebra de conjuntos: Para cualquier A, B U:
Leyes conmutativas
Leyes asociativas
Leyes distributivas
Leyes de idempotencia
Leyes de identidad
Complementación doble
Leyes del complemento
Leyes de De Morgan
Unidad 2: Inducción matemática
1. Métodos para demostrar la verdad de una implicación
1) Método directo: V V
2) Método indirecto:
a) Por el contrarrecíproco: F F
b) Por el absurdo: supongo el antecedente verdadero y el consecuente falso y busco llegar a una
contradicción de proposiciones.
2. Inducción matemática
I)
II)
Unidad 3: Relaciones de recurrencia
Orden de una relación: mayor subíndice – menor subíndice.
](https://image.slidesharecdn.com/matematicasciffdob-240629235208-7f2b1627/85/Matematicas-FINANCIERAS-CIFF-dob-pdf-147-320.jpg)