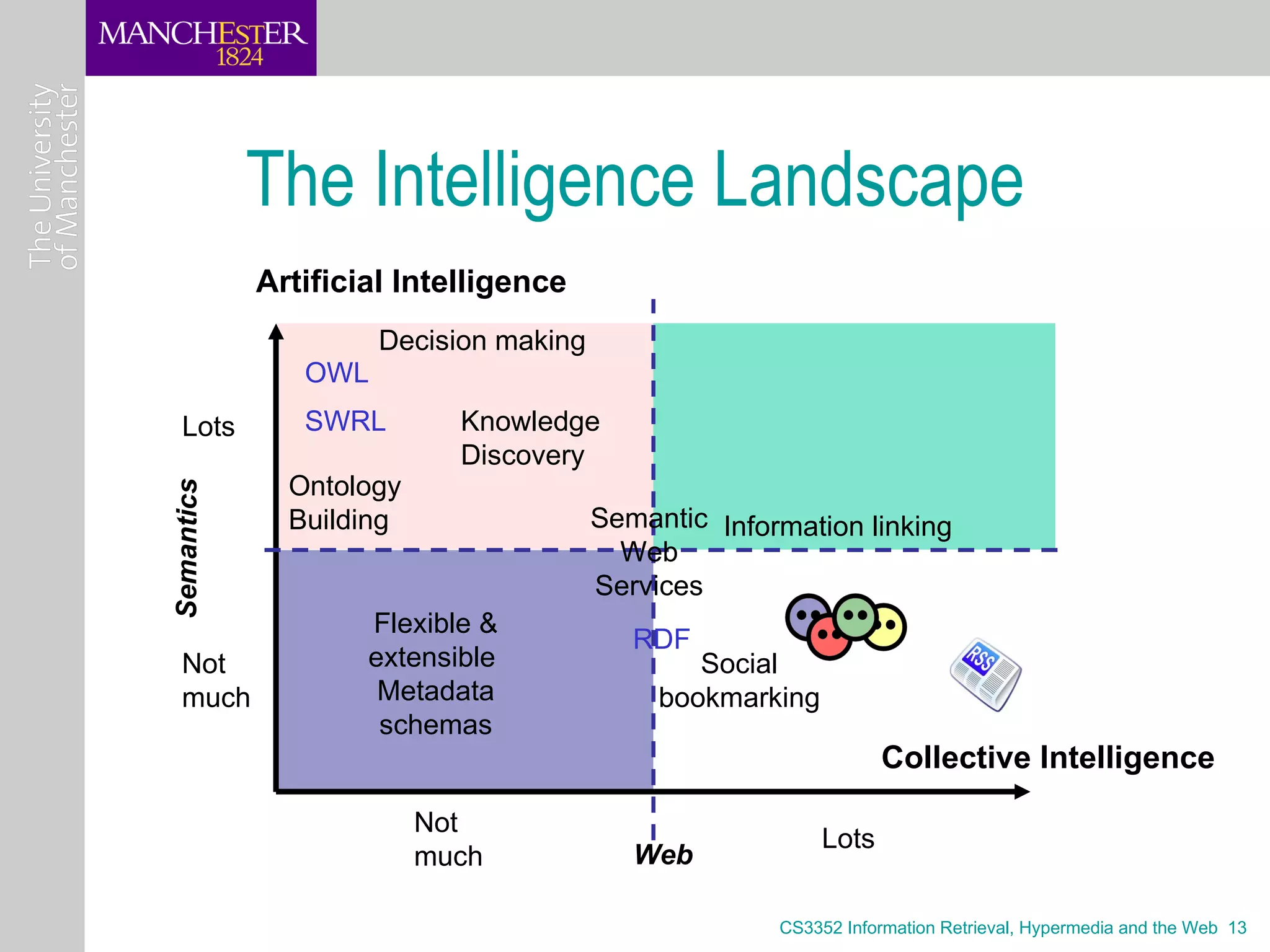
The document discusses the key concepts of Web 2.0, including how it utilizes collective intelligence through social bookmarking, tagging, wikis and collaborative filtering. It also examines how Web 2.0 applications harness the network effect to aggregate user data and benefit from increased participation. Finally, it outlines some of the design principles of Web 2.0 such as treating the web as a platform, harnessing collective intelligence, and providing rich user experiences through technologies like AJAX.






![[O’Reilly 05]
CS3352 Information Retrieval, Hypermedia and the Web 7](https://image.slidesharecdn.com/skb-web2-0-120609090246-phpapp01/75/Skb-web2-0-7-2048.jpg)









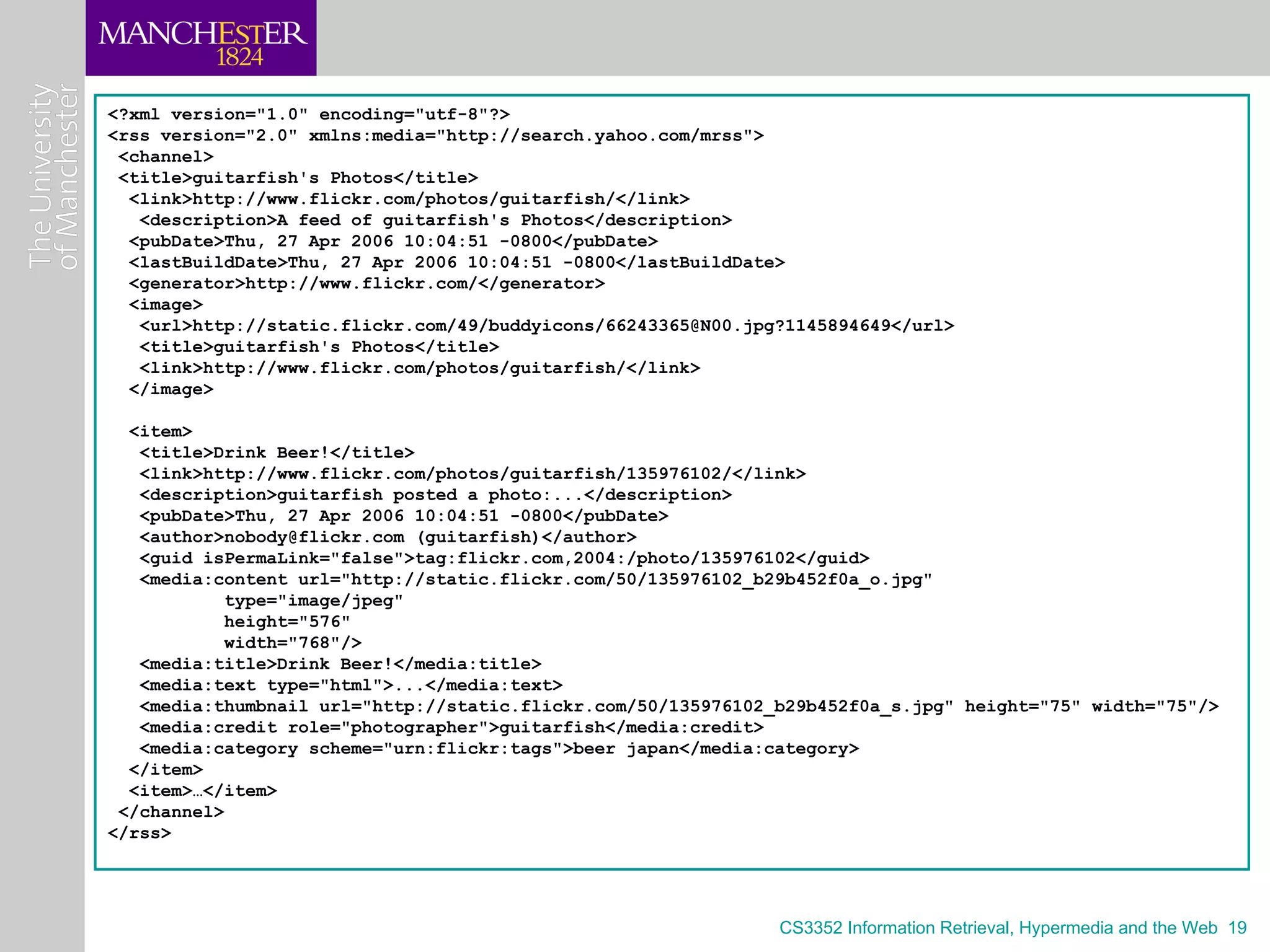
![RSS
“The most significant advance in the fundamental
architecture of the web since […] CGI.”
O’Reilly
• Really Simple Syndication
• Lightweight standard
• Allows publication of content feeds
– Linking to resources, with notifications of page changes.
– Dynamic linking
– Pub/Sub
CS3352 Information Retrieval, Hypermedia and the Web 18](https://image.slidesharecdn.com/skb-web2-0-120609090246-phpapp01/75/Skb-web2-0-18-2048.jpg)









![AJAX
[Garrett 05]
CS3352 Information Retrieval, Hypermedia and the Web 29](https://image.slidesharecdn.com/skb-web2-0-120609090246-phpapp01/75/Skb-web2-0-29-2048.jpg)


































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)









