Download to read offline



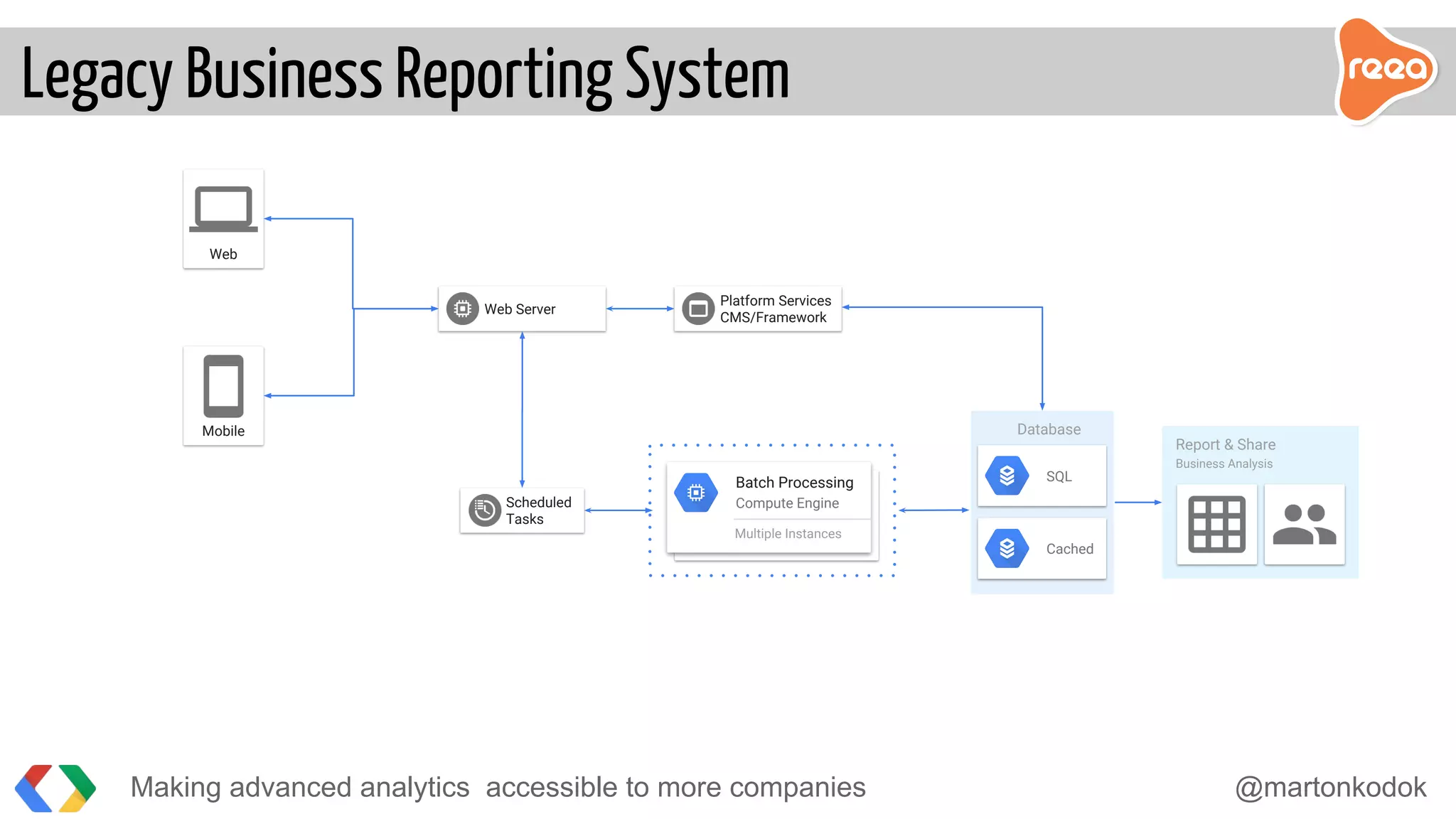

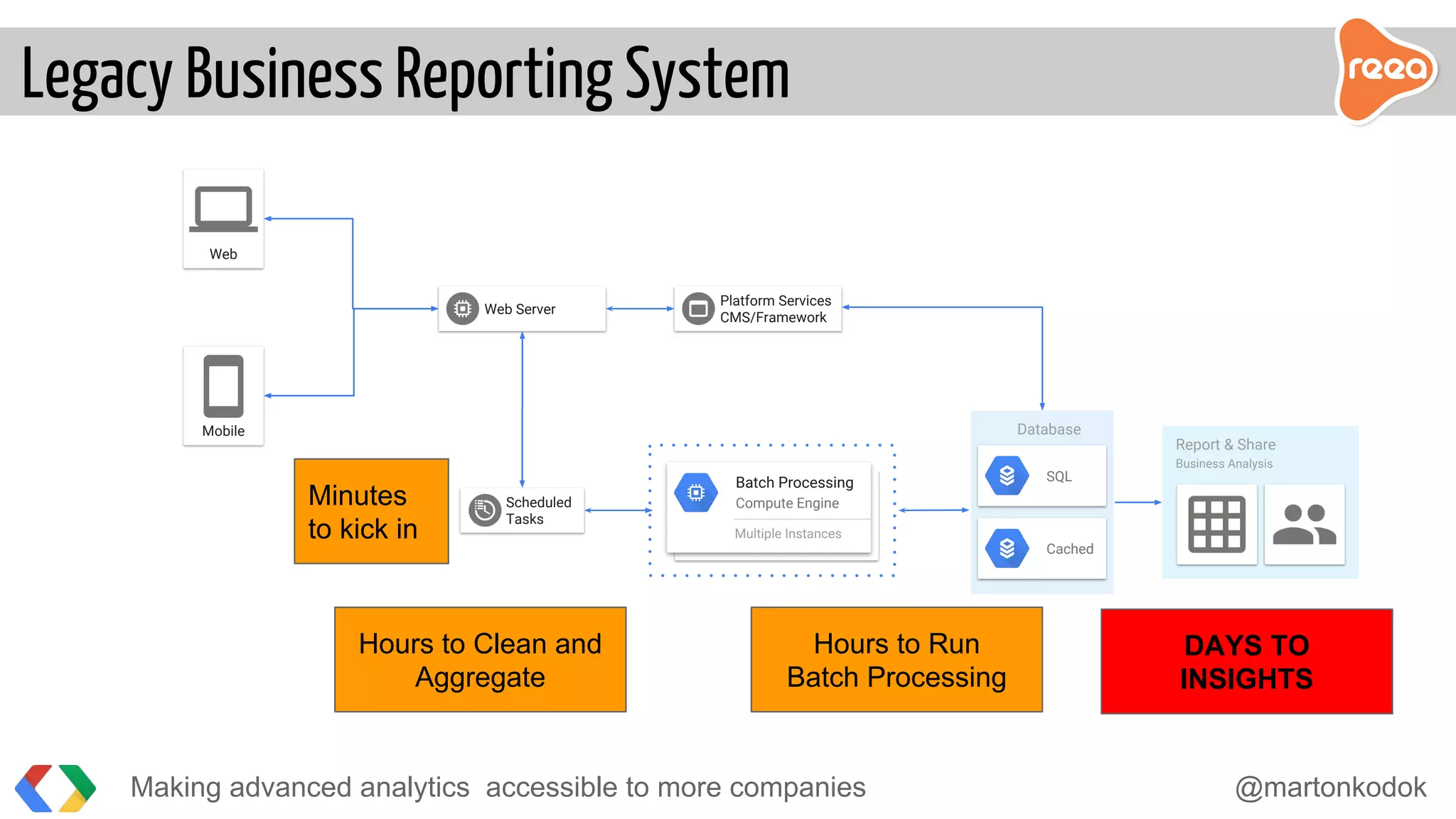



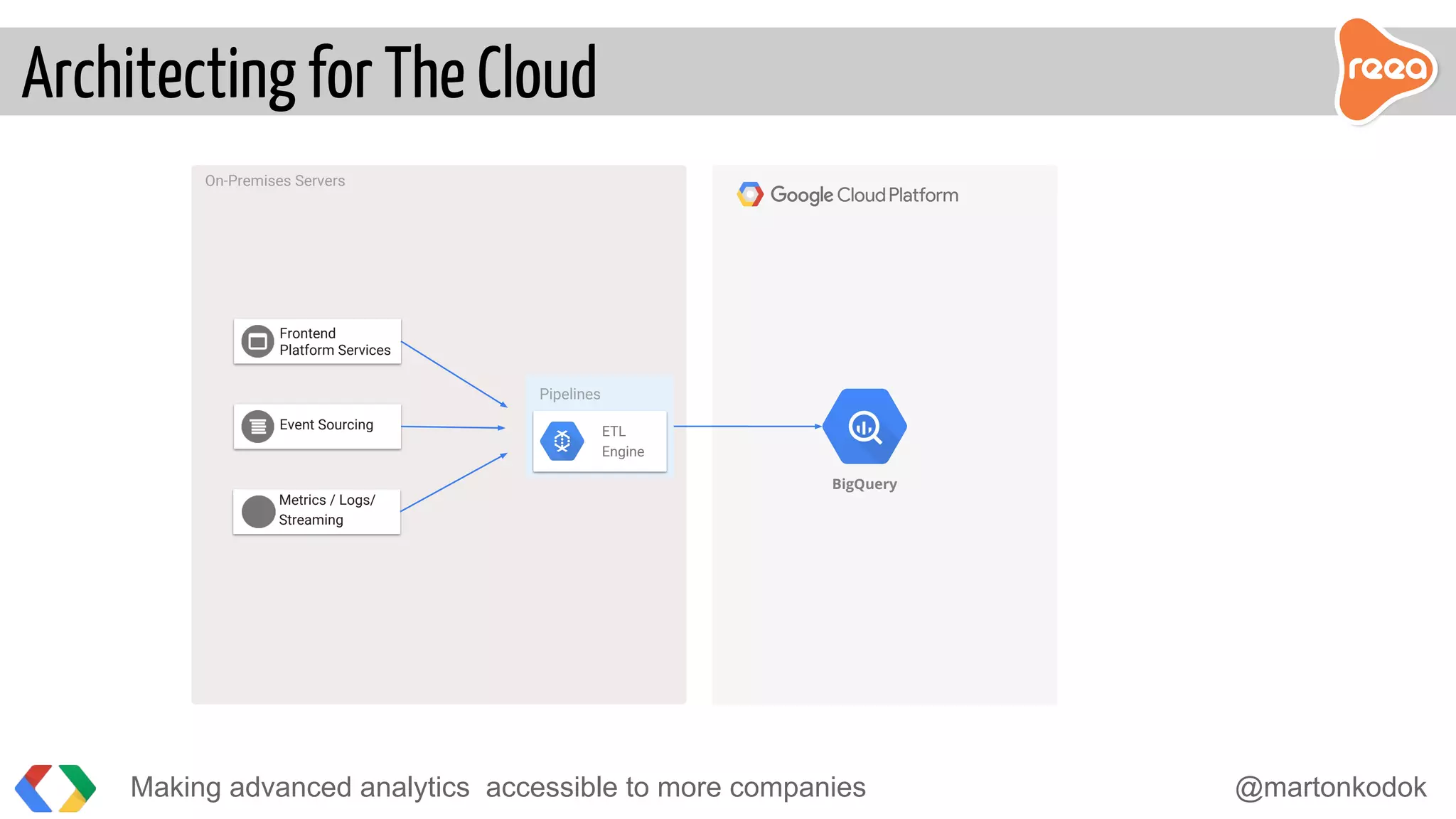
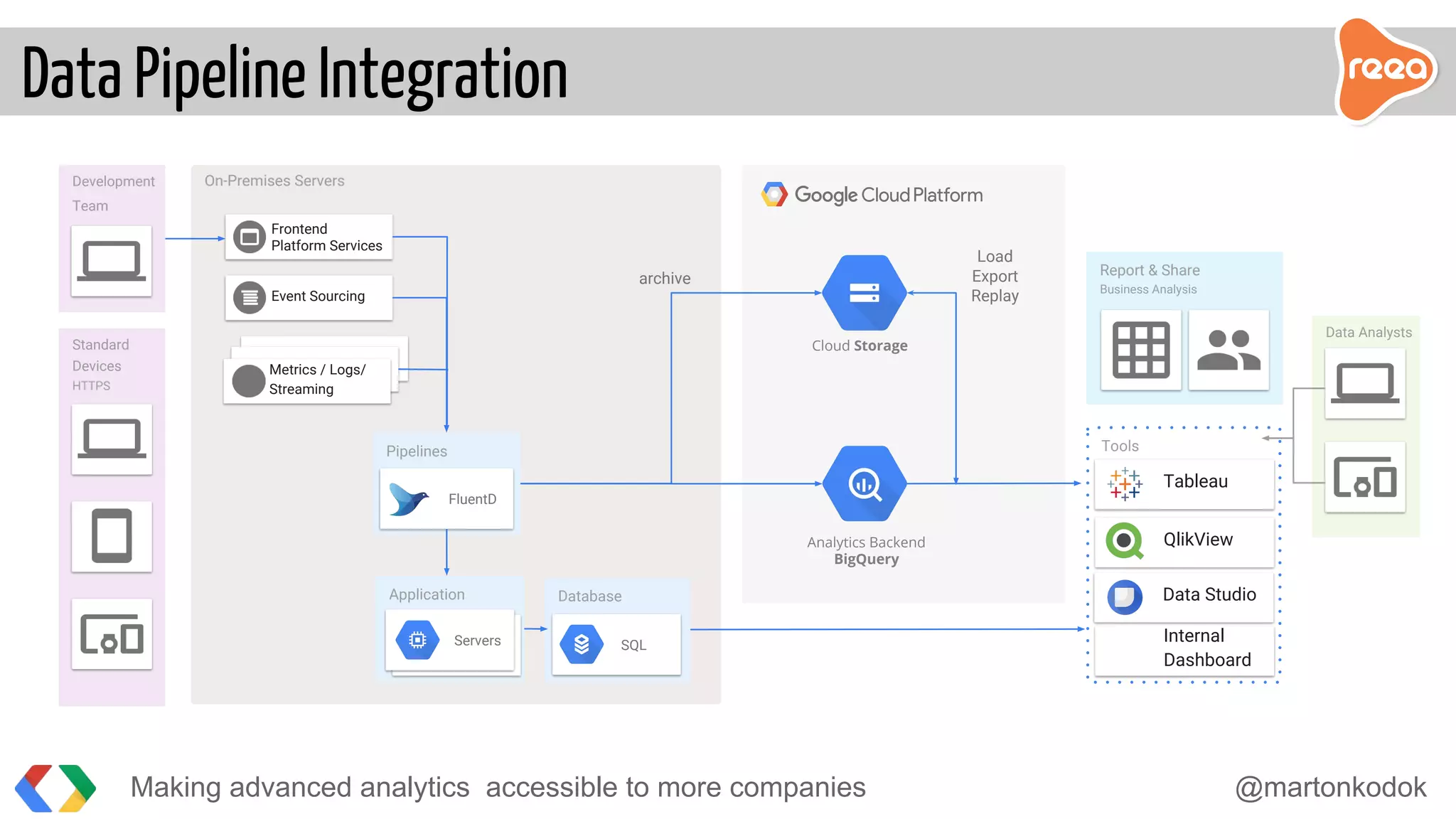



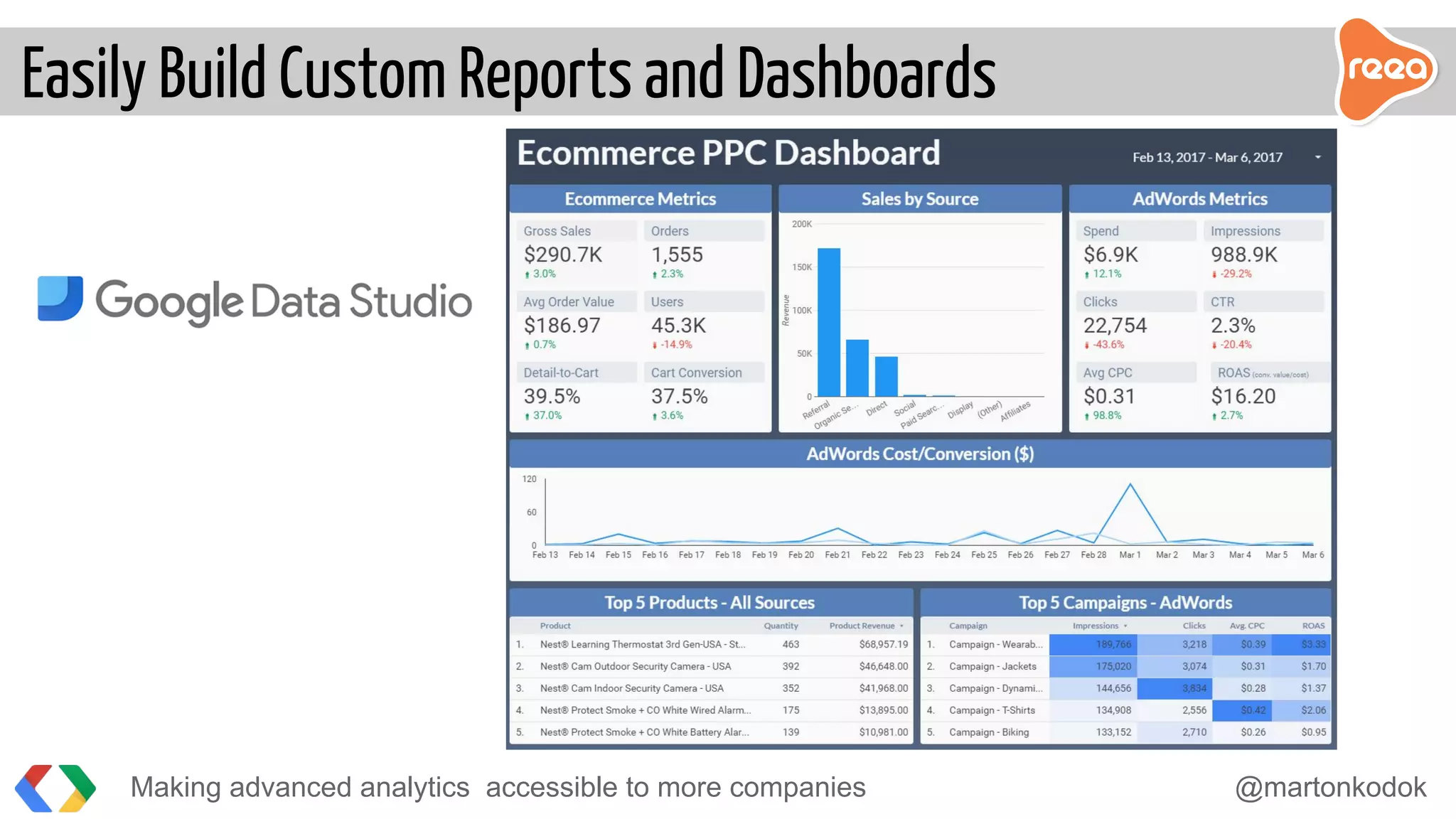


The document discusses making advanced analytics more accessible to companies. It proposes using BigQuery, Google's serverless data warehouse, which allows storing and querying large datasets cost effectively without needing to manage infrastructure. Data is ingested via pipelines into BigQuery from various sources and then business analysts can easily build custom reports and dashboards in tools like Tableau without requiring developers. BigQuery reduces the time to insights from days to minutes by handling all the challenges of large-scale analytics.

















































































