Downloaded 71 times


























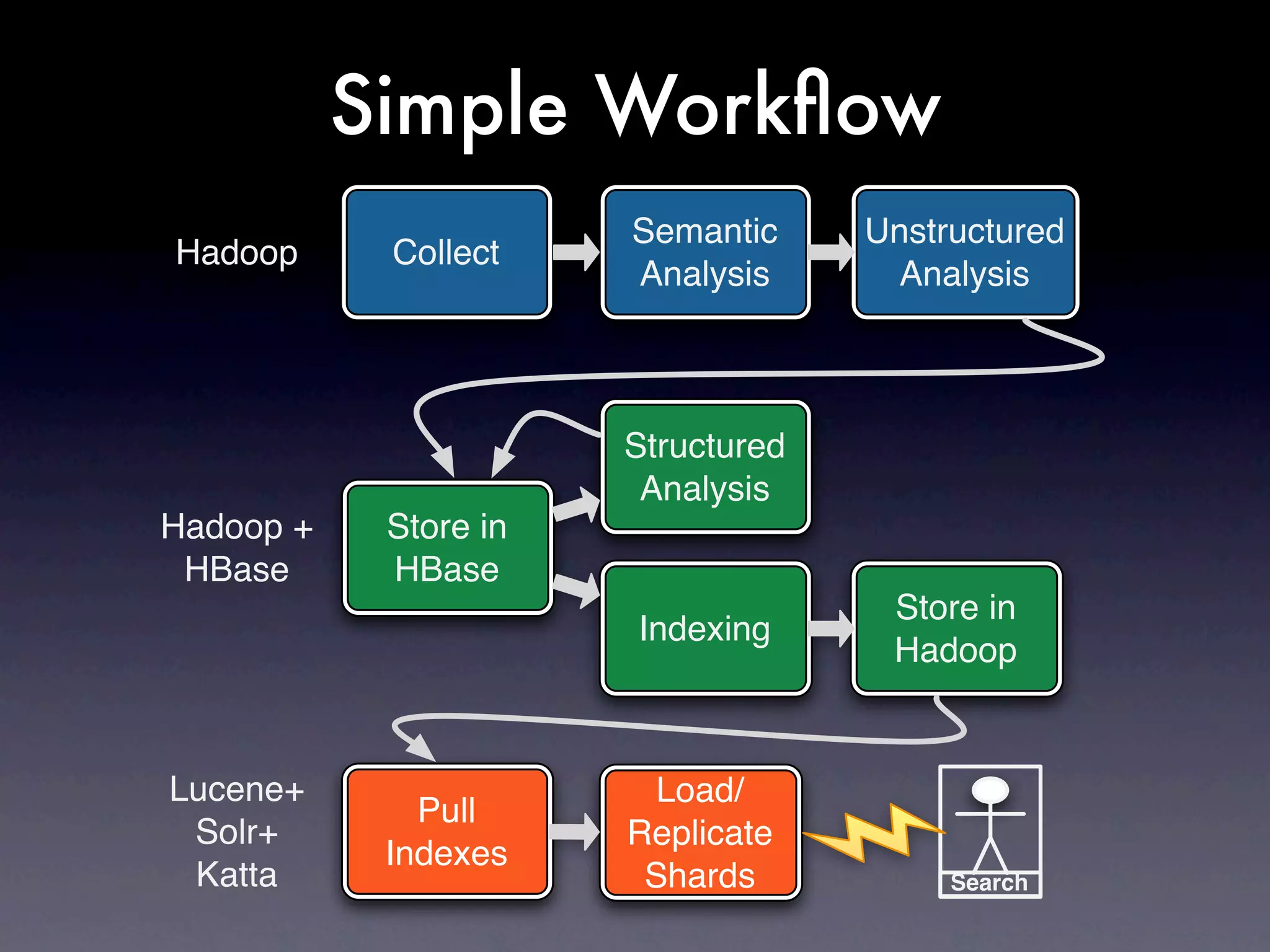





The document discusses strategies for building scalable systems in the era of big data, emphasizing the importance of engineering and operations in managing unstructured and interconnected data. It highlights key concepts such as recovery-oriented computing, gradual deployment, and the necessity for extensive testing in production environments. The author stresses adapting to failures, the unique challenges of engineering at scale, and the need for a strong computer science foundation.














































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















