Downloaded 11 times































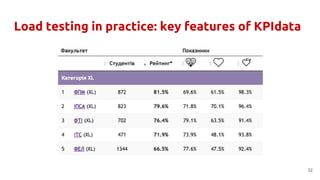






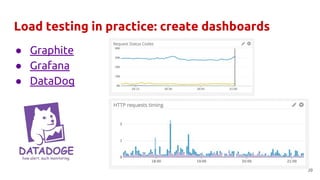





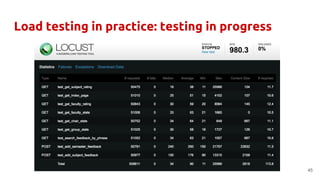

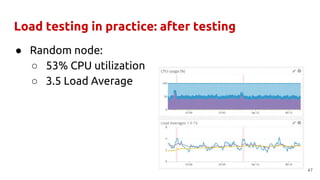







The document discusses best practices and common mistakes in managing high load Python projects, including identification of performance bottlenecks and the importance of load testing. Key topics include the use of efficient libraries, asynchronous frameworks, and the necessity of preparing for increased demand through effective load testing techniques. It emphasizes the need for fine-tuning Python applications with C extensions and exploring multitasking approaches to improve scalability and responsiveness.