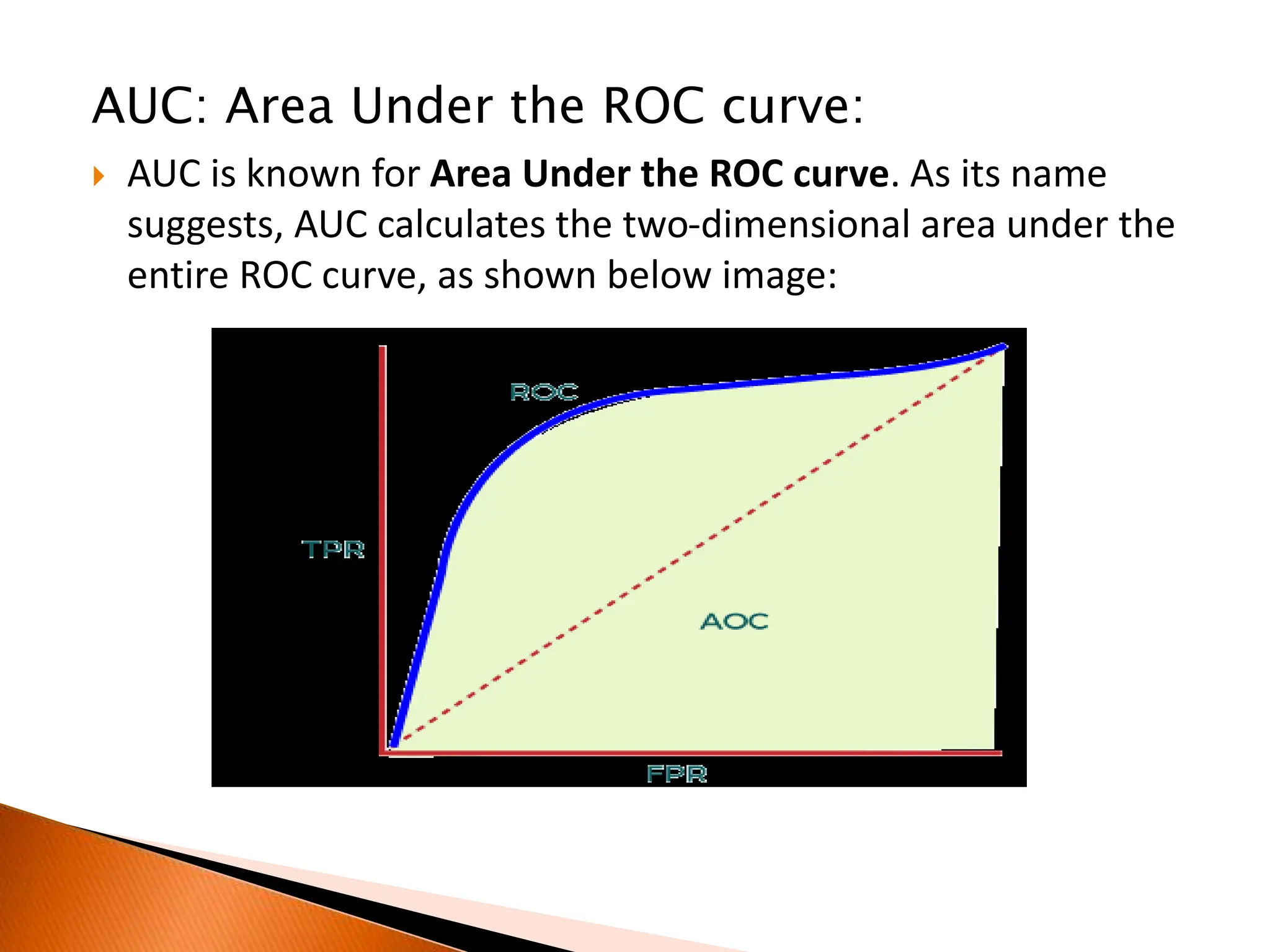
This document discusses performance metrics for evaluating machine learning models. It explains that metrics are used to understand how well a model performs on both the training data and new, unseen data. For classification models, common metrics include accuracy, confusion matrix, precision, recall, F1 score, and AUC. For regression models, common metrics are mean absolute error, mean squared error, R2 score, and adjusted R2. The document provides formulas and explanations for calculating and interpreting each of these important performance metrics.























































![IMAGE_ENHANCEMENT_TECHNIQUES[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/imageenhancementtechniques1-240130165317-505fe013-thumbnail.jpg?width=640&height=640&fit=bounds)



















