About me
• Education
•NCU (MIS)、NCCU (CS)
• Work Experience
• Telecom big data Innovation
• AI projects
• Retail marketing technology
• User Group
• TW Spark User Group
• TW Hadoop User Group
• Taiwan Data Engineer Association Director
• Research
• Big Data/ ML/ AIOT/ AI Columnist
2








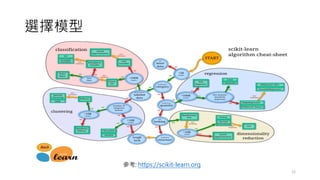



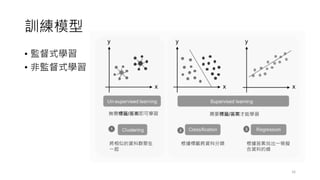



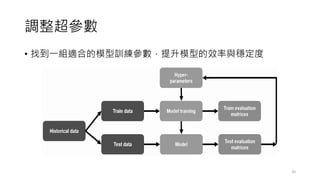
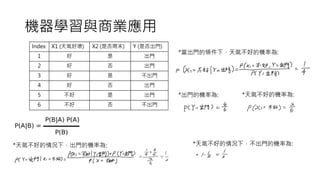
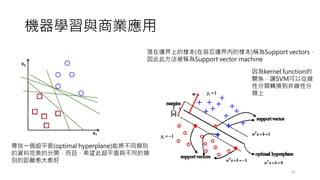
![調整超參數
• 傳統的手工調參
• 利用實務經驗來給定最佳參數,通常會先初步建模並測試,有了正確率
數值再進一步憑感覺調整超參數。
• 缺點是沒辦法保證找到最好的組合、非常耗時。
• 網格搜尋 (Grid-Search)
• 假設有兩個待試超參數P1,P2,其集合為P1=[1,2,3],P2=[a,b,c],由此
兩超參數可以組合出P1×P2個組合。
• 再使用CV(交叉驗證技巧),每個組合可得到一組數值,選最高即為最佳
參數。
• 雖然可以找到最佳解,但是整個過程仍然非常耗時間。
21](https://image.slidesharecdn.com/1classification-211030044556/85/machine-learning-introduction-21-320.jpg)








































![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台灣人工智慧學校] 台北總校第三期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/opening1-180929011045-thumbnail.jpg?width=640&height=640&fit=bounds)



![[台灣人工智慧學校] 台中分校第一期開學典禮](https://cdn.slidesharecdn.com/ss_thumbnails/opening-180820074116-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台灣人工智慧學校] 新竹分校第一期開學典禮](https://cdn.slidesharecdn.com/ss_thumbnails/aiahc-opening-180720120102-thumbnail.jpg?width=640&height=640&fit=bounds)






















