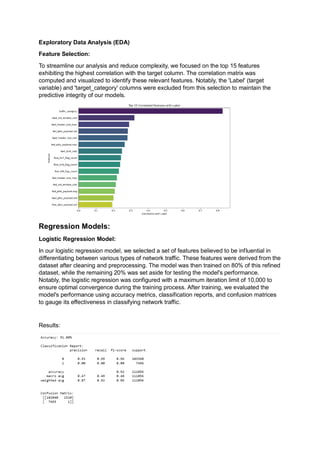
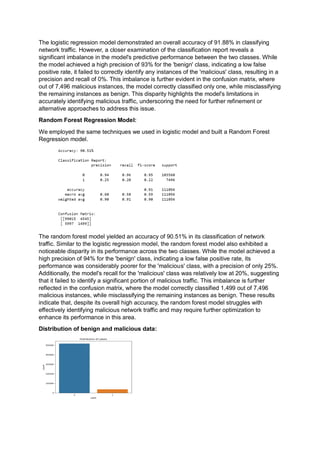
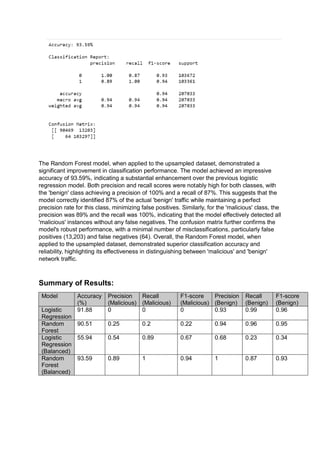
The document analyzes the effectiveness of machine learning algorithms, specifically logistic regression and random forest, in detecting malicious network traffic using the Hikari-2021 dataset. Initial models displayed high accuracy in classifying benign traffic but struggled significantly with malicious traffic, leading to the implementation of upsampling techniques to address class imbalances, resulting in improved performance. The enhanced random forest model achieved an impressive accuracy of 93.59% with high precision and recall for both classes, emphasizing the importance of machine learning in cybersecurity applications.







































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

