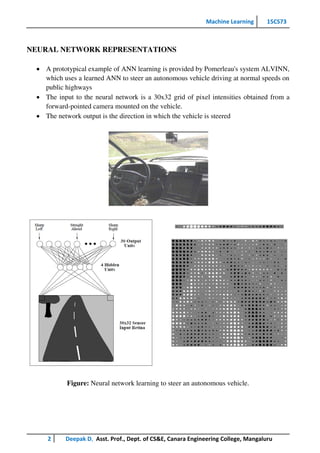
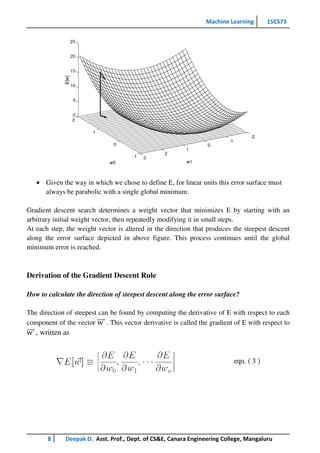
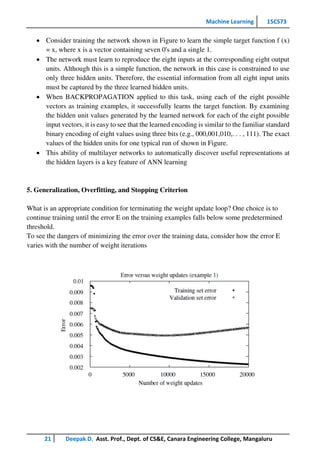
This document provides an overview of artificial neural networks and the backpropagation algorithm. It discusses how ANNs were inspired by biological neural systems and some key facts about human neurobiology. It then describes properties of neural networks like many weighted interconnections and parallel processing. The document explains neural network representations using an example of a network that learns to steer a vehicle. It also covers perceptrons, gradient descent, the delta rule, and stochastic gradient descent for training neural networks. Finally, it discusses multilayer networks and the backpropagation algorithm for training these types of networks.