1. Design and Implementation of LuminonCore Virtual Graphix
1. What is LumincoreCore Virtual Graphix ?
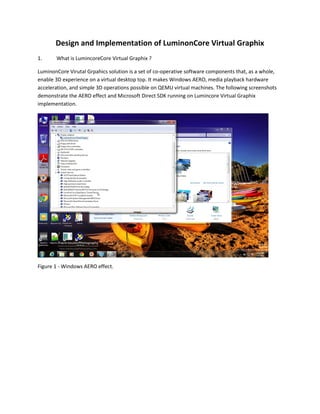
LuminonCore Virutal Grpahics solution is a set of co-operative software components that, as a whole,
enable 3D experience on a virtual desktop top. It makes Windows AERO, media playback hardware
acceleration, and simple 3D operations possible on QEMU virtual machines. The following screenshots
demonstrate the AERO effect and Microsoft Direct SDK running on Lumincore Virtual Graphix
implementation.
Figure 1 - Windows AERO effect.
2. Figure 2 - Microsoft DirectX SDK D3D9 app.
2. How does it work?
It works similar to Microsoft RemoteFX vGPU, except that it requires no Microsoft Hyper-V solution(
http://blogs.msdn.com/b/rds/archive/2014/06/06/understanding-and-evaluating-remotefx-vgpu-on-
windows-server-2012-r2.aspx ).
The following figure illustrates overview of such framework. The client side virtual WDDM driver
receieves requests from user mode app, and pushes the requests to the peer VM through a shared
queue. The GPU_SRV.EXE interpets the requests and sends them down to real graphics card (which is
enabled by VFIO pass-through). Finally, the request completion events propagates to the request
originator though shared queue. POSIX shared memory and POSIX semaphore are used to implement
shared queue buffer and shared queue events.
LCI_SHM kernel driver is a key component which enables high performance memory sharing among
VMs.
3. Figure 3- Overall architecture
2.1 Lumincore Virtual WDDM UserMode driver(LCI_VIRTUMD) accepts D3D9 downcalls from user
app (eg. DWM.EXE , WMPLAYER.EXE, DX SDK Samples) , and translates them into internal VGPU
requests.
2.2 LuminconCore Hyperspace Tunnel Device & Driver is responsible for transferring VGPU requests
in high performance manner (without memory copy) between virtual machines. It is also responsile for
Inter-VM memory shareing.
2.3 The server side GPU_SRV.EXE receives the VGPU requests over the tunnel and passed them to
native WDDM user mode driver (eg. NVIDIA WDDM user mode driver) thru Lumincore Proxy Display
backdoor.
2.4 The request completion events are propagated to the original requestors.
4. 3. What is LumincoreCore HyperSpace Shared Memory framework?
LumincoreCore HyperSpace Shared Memory framework enables high performance memory sharing
among VMs. It works similarly to what InterVM Shared Memory ( http://www.linux-
kvm.org/wiki/images/e/e8/0.11.Nahanni-CamMacdonell.pdf ) does, but does a better job. The Inter-VM
shared memory mechanism works by creating host side shared memory objects (POSIX shared memory
mechanism) , and mapping them to guest PCI device MMIO BAR subregion. A substantial memory copy
is required if the target memory buffers are previously created in guest VM.
LuminonCore HyperSpace Shared memory framework works by direct-mapping guest memory buffers
directly from one VM to another. No bounce-buffer is required. To enable memory mapping among
different VM memory spaces, a series of buffer fragmenataion and reassembly process are done. The
following figure illustrates how a guest user mode buffer is fragmented into multiple guest physical
addresses, and how the fragemnted guest physical addresses are re-assembed into guest user mode
virtual address.
5. Figure 4 - LuminonCore HyperSpace shared memory framework
The framework requires different layers of software drivers co-operations. The guest kernel driver
breaks a user mode buffer into multiple guest pages. The QEMU HyperSapce Tunnel device keeps tracks
of guest PFN lists. LCI_SHM kernel driver does the heavy-lifting job.
3.1 Guest kernel driver locks down the guest user mode buffer, and traverse guest page frame
numbers associated with the guest user mode buffer. A single guest user mode buffer can be
fragmented into many dis-contiguous guest physical pages.
On Microsoft Windows OS, the following steps are done to grab the guest PFN (Page Frame number) :
pMdl = IoAllocateMdl(UserBuffer, UserBufferSize, FALSE, FALSE, NULL);
try { MmProbeAndLockPages(pMdl, UserMode,IoReadAccess); }
except (EXCEPTION_EXECUTE_HANDLER) { IoFreeMdl(pMdl); return; }
6. PfnList = MmGetMdlPfnArray(pMdl);
NumOfPfn = ADDRESS_AND_SIZE_TO_SPAN_PAGES( MmGetMdlVirtualAddress(pMdl),
MmGetMdlByteCount(pMdl) );
3.2 The guest PFN list assoiciated with a guest user buffer is tracked down by QEMU host side
software. Guest Physical Address (GPA) to Host Virtual Address (HVA) translation is done at QEMU side.
The guest PFN list is translated into a list of host virtual buffers. This list of host virtual buffers is further
locked down by Linux lci_shm kernel driver.
3.3 The lci_shm Linux kernel driver locks down the guest virtual buffer list by get_user_pages().
Upon IOCTL Completion, the lci_shm driver returns a unique shared memory object ID.
3.4 The peer VM learns the shared memory ID (shm_id) embedded in VGPU request, and tries to
map the shm_id into host virtual buffers. lci_shm IOCTL along with mmap() does the mapping job.
3.5 Once the mappings are done, peer VM QEMU exposes them into PCI device MMIO BAR
subregions.
3.6 Peer VM kernel driver maps the PFN lists into 1 single user buffer.
4. Direct GPU rendering
With the shared memory technique, client VM side frame buffer can be rendered by remote VM
hardware GPU. LCI_VIRTUMD module instructs GPU in the remote VM to do the job.
7. 5. Tricks used in perforamnce improvement.
5.1 A typical D3D9 command roundtrip
The following figure shows how a typical D3D request get propagated to the GPU_SRV.EXE.
8. Figure 5 - typical request flow chart.
A SharedQueue is pe-allocated from POSIX shared memory, and mapped both to server VM and client
VM. So both VM sees the same SharedQueue. A typical request round trip involved 15 steps. On a
typical PC (CPU I5 4330, 16 GB RAM), average round-trip time is about 120 micro-seconds. This means
that we could do 8333 requests /second throughtput.
5.2 ShadowMap.EXE analysis.
ShadowMap.EXE is a Direct SDK D3D9 sample app. It issues 841 D3D9 request before rendering a
image. With 8333 reqeusts/second throughtput rate, the FPS observed from ShadowMap.EXE is about 9
~ 10 FPS, which is quite slow! A round-trip time reduction approach is used such that we could do 60
FPS in ShadowMap.EXE.
5.3 QEMU phys_page_set_level() problem
9. During development, we've observed CPU hog caused by phys_page_set_level() when we tried to map a
host virtual address into guest address space. The following GDB experiment shows that for each
memory_region_add_subregion(), phys_page_set_level() is triggered 1196 times on QEMU version 1.7.0
and 2.1.0. It causes great performance penalty.
5.4 HUGE_PAGE shared memory mechanism.
To work-around the phys_page_set_level() problem, we came up with HUGE_PAGE shared memory
mechanism. The idea behind the HUGE_PAGE mechanism is to map a larger block for a given guest PFN.
Instead of mapping a 4KB page, a 4MB block is mapped to guest address space. When a given 4MB block
is not needed by guest user mode app, it is not unmapped immediately. Instead it remains mapped .
Later subsequent shared memory operations get cache hit when the requested PFN fell into the 4MB
block range, and the call to memory_region_add_subregion() can be reduced.
With the HUGE_PAGE shared memory implementation, we observe significant performance gain, and
lower CPU usage.
The HUGE_PAGE size is configurable at compile time.
10. 6. Known bugs/To-Do list.
- Occaional Linux kernel crash caused shm reference leakage. This happens when a guest VM is shutting
down while the another VM is still taking referenc to the shared memory exposed by the VM shutting
down.
- Internet Explorer and Google Chrome wouldn't work.
- Lots of app wouldn't work if AERO is enabled.
- GPU_SRV.EXE crashed if Internet Explorer is invoked.
- GPU direct rendering implemntation is not yet complete. Frame buffer is not correctly updated if a
window is overlapping on DirectX SDK window.
- Convert PCI Line interrupt to MSI for LuminCore HyperSpace tunnel device to reduce interrupt
processing overhead.