Download as PDF, PPTX









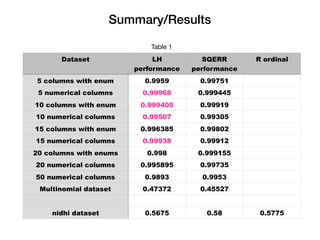


The document discusses logistic ordinal regression, focusing on its application in predicting ordinal variables significant for preference modeling in social sciences. It outlines the methodology for building linear models, updating model parameters, and making predictions, as well as implementing these models using H2O. The results demonstrate the performance of various datasets under different configurations, highlighting the effectiveness of the models.


































































