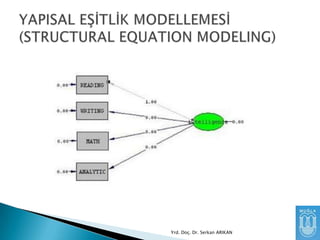
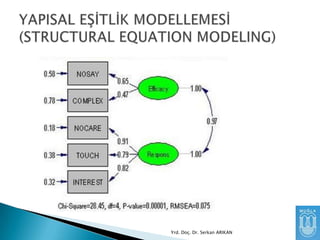
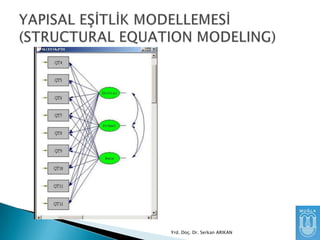
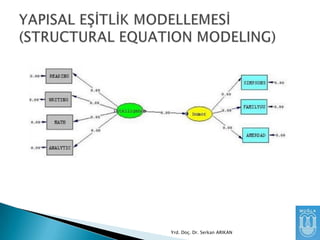
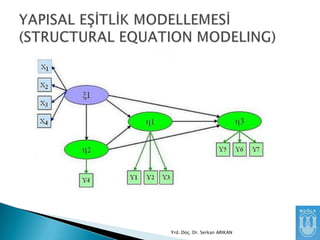
Niye Kullanırız?
Birden çokgözlenen değişkeni kullanarak
aralarındaki ilişkiyi daha iyi anlayabiliriz.
Yrd. Doç. Dr. Serkan ARIKAN
9.
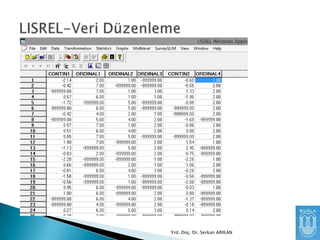
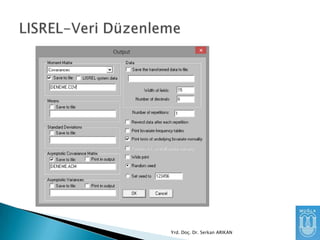
PRELIS: PreLisrel, Lisrelinveri düzenleme
aracıdır.
SIMPLIS: SimpleLisrel, Syntaxlar yardımı ile
analizleri yapmamızı sağlayan kolay
kullanımlı bir yazılımdır.
Yrd. Doç. Dr. Serkan ARIKAN
IMPORT DATA INFREE FORMAT Seçeneği
SPSS dosyaları gibi daha önce hazırlanmış
verileri Lisrelde görmemizi sağlar.
SPSSEX klasöründen Data100.sav dosyasını
açalım.
Yrd. Doç. Dr. Serkan ARIKAN
12.
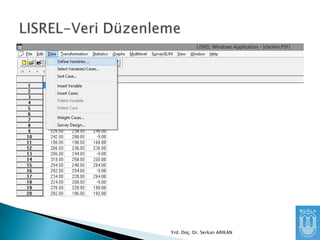
PRELIS’te SPSS datadosyası açtığımızda
sistem otomatik olarak Data100.psf dosyası
oluşturup kaydeder.
Yrd. Doç. Dr. Serkan ARIKAN
Ölçüm Birimi
Kullandığımız ölçümbirimi yapabileceğimiz
matematiksel işlemleri dolayısı ile istatistiksel
analizleri etkilemektedir.
Nominal: Kız-Erkek
Ortalama almanın, standart sapma
hesaplamanın bir anlamı yoktur.
Yrd. Doç. Dr. Serkan ARIKAN
15.
Ölçüm Birimi
Ordinal: Okulakarşı tutum, Tamamen
katılıyorum, …., Tamamen katılmıyorum
Aralarında sıralama olan kategorik verilerde
“Mann-Whitney U Test” gibi sıralamaya göre
hesaplama yapan testler kullanılır.
Yrd. Doç. Dr. Serkan ARIKAN
16.
Ölçüm Birimi
Continuous: Öğrencilereverilen
notlar, Öğrencilerin boy uzunlukları
Bu tip veride ortalama ve standart sapma
hesaplamak artık anlamlıdır.
Yrd. Doç. Dr. Serkan ARIKAN
17.
Ölçüm Birimi
Datamızda yeralan değişkenlerin
nominal,
ordinal veya
continuous
olup olmadığı LISREL’e girilmelidir.
Yrd. Doç. Dr. Serkan ARIKAN
Veri Adetinin Sınırlanması
Lisrelotomatik olarak bir değişkendeki veri
sayısı 15ten az ise o veriyi “Ordinal”, 15ten
fazla ise o veriyi “Continuous” olarak
analizlere katmaktadır.
Bunun sebebi ise veri çeşiti 15ten fazla ise
Pearson Korelasyonu -1 ile +1 arasında
değişirken 15ten az ise -0,5 ile +0,5 arasında
değişmesidir.
Yrd. Doç. Dr. Serkan ARIKAN
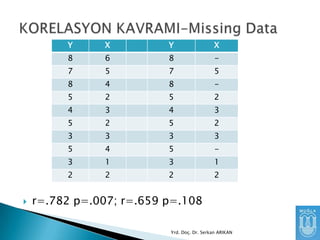
Kayıp Data (MissingData)
Ġstatistiksel veri analizi sonuçları kayıp
datadan etkilenmektedir.
Bu sebeple, kayıp datanın ne yapılacağına
karar verilmelidir.
Yrd. Doç. Dr. Serkan ARIKAN
22.
Kayıp Data (MissingData)
Öncelikle kayıp datanın sebebi incelenmelidir.
◦ Veri girişi sırasında mı hata yapılmıştır?
◦ Kayıp data “random” mıdır?
◦ Kayıp data sistematik midir?
Yrd. Doç. Dr. Serkan ARIKAN
Kayıp Data (MissingData)
Listwise deletion and Pairwise deletion
metodları kullanılırsa veriden çok sayıda
“case” silinebilir ve örneklem sayısı ciddi
olarak azalabilir.
Yrd. Doç. Dr. Serkan ARIKAN
25.
Kayıp Data (MissingData)
Mean Substitution yöntemi eğer çok az sayıda
kayıp değer var ise kullanılmalıdır.
Regression Imputation eğer orta seviyede
kayıp değer var ise kullanılmalıdır.
Yrd. Doç. Dr. Serkan ARIKAN
26.
Kayıp Data (MissingData)
The maximum likelihood (EM algorithm) eğer
çok sayıda eksik varsa kullanılabilinir.
(Ama missingler random olmalı sistematik
olmamalı)
Yrd. Doç. Dr. Serkan ARIKAN
27.
Kayıp Data (MissingData)
En çok tavsiye edilen ise: “Full Information
Maximum Likelihood” (FIML) metodu
kullanılarak LISREL hesaplamalarının
yapılmasıdır.
Yrd. Doç. Dr. Serkan ARIKAN
28.
Kayıp Data (MissingData) –
IMPUTATION ÖRNEĞĠ
TUTORIAL FOLDER
import Data in free format
Chollev.dat
3 Variables
Chollev.psf
Yrd. Doç. Dr. Serkan ARIKAN
29.
Kayıp Data (MissingData) – ÖRNEK
-9’lar missing olarak tanımlanmalı
(Save Edilmeli)
Yrd. Doç. Dr. Serkan ARIKAN
Kayıp Data (MissingData) – ÖRNEK
Data screening kısmını kullanarak kontrol
ediniz.
Yrd. Doç. Dr. Serkan ARIKAN
36.
Outliers
“Outliers” ortalama (mean)ve standart
sapmayı çok fazla etkilerler
◦ Data giriş hatası mı?
◦ Başka grupa ait bir data mı?
◦ “Outliers” ile diğer dataların arasındaki
boşluk, örneklem toplayarak kapatılabilinir mi?
Box and Whisker Plot
(Lisrel de çiziyor ama datayı 5 parçaya
bölüyor)
Yrd. Doç. Dr. Serkan ARIKAN
37.
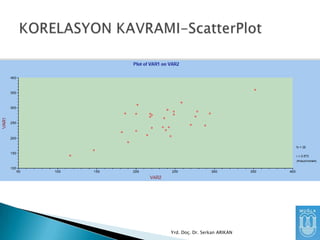
Doğrusallık (Linearity)
Değişkenler arasıilişkilerin lineer olması
beklenmektedir, “curvilinear” ilişkiler
korelasyonun sıfır çıkmasına sebep
olabilecektir.
Bu bakımdan değişkenler arası “scatterplot”
çizdirilebilinir.
Graph & Bivariate & ScatterPlot
Yrd. Doç. Dr. Serkan ARIKAN
38.
Normallik
Genel olarak pekçok analiz yöntemi verilerin
normal dağılmasını varsaymaktadır
(Assumption)
Normal dağılmayan data durumlarında
“asymptotic covariance matrix” ile “covariance
matrix” birlikte kullanılması önerilmektedir.
Yrd. Doç. Dr. Serkan ARIKAN
Ġki değişken arasındakiilişki, korelasyon veya
kovaryans istatistiksel hesaplamalarda önemli
bir yer tutmaktadır.
Korelasyon veya kovaryans hesaplaması
yapılırken değişkenlerin ölçüm birimi
(continuous, ordinal) dikkate alınmalıdır.
Continuous ve ordinal bir arada kullanılacak
ise “asymptotic covariance matrix”
kullanılmalıdır.
Yrd. Doç. Dr. Serkan ARIKAN
Ġlk kural olarak,ne kadar çok örneklem o
kadar iyi analiz sonuçları diyebiliriz.
Lisrel analiz yapıldıktan sonra sağlıklı
sonuçlar elde edilmesi için tavsiye edilen
“Critical N” (Hoelter, 1983) değerini
raporlamaktadır.
Yrd. Doç. Dr. Serkan ARIKAN
Lisrel hesaplamaları yaparken
◦Ġmplied Model (Tasarlanan Model)
◦ Saturated Model (Tam Model)
◦ Independence Model (Hiçbir parametre
hesaplanmayan model)
Kullanarak karşılaştırmalar yapmaktadır.
Eğer örneklem sayısı az ise “Saturated Model”
hesabı yapamayacağı için analizleri
gerçekleştiremez.
Yrd. Doç. Dr. Serkan ARIKAN
49.
Çalışmalarımızı planlamadan örneklemsayısı
ile ilgili bazı hesaplamalar yaparak en az
sayıda örneklem ihtiyacını dikkate almalıyız.
Yrd. Doç. Dr. Serkan ARIKAN
50.
En az 100-150kişi olmalı
400 kişinin bile bazı durumlarda yeterli
olamayabileceğini söyleyenler de var.
En az değişken başına 10-20 kişi
Normal dağılan bir veri ise değişken başına 5
kişi yeterli olabilir (Bentler & Chou, 1987)
Yrd. Doç. Dr. Serkan ARIKAN
Analizde input olarakkullanılabilecek
seçenekler
◦ Ham datayı Lisrele tanıtabilir (psf dosyası olarak)
(Program bu datadan kendisi kovaryans matrisi
üreterek analizlere devam eder)
◦ Korelasyon matrixi oluşturup syntaxta kullanabilir
(Prelis ile)
◦ Kovaryans matrixi oluşturup syntaxta kullanabilir
(Prelis ile)
Yrd. Doç. Dr. Serkan ARIKAN
53.
Korelasyon matrisi kullanılırsaSEM
programları bu matrisi standart sapmaları
kullanarak kovaryans matrisine çevirirler.
Çünkü, korelasyon matrisinden elde edilen
parametre kestirimleri hatalı olabilir.
Yrd. Doç. Dr. Serkan ARIKAN
Veriler toplanmadan önceteorik bazda
modelin oluşturulmasıdır. (literatür taraması,
önceki yapılan çalışmalar, araştırma problemi
ışığında)
“Acaba bu oluşturulan model varyanskovaryans matrisi tarafından destekleniyor
mu?” sorusuna cevap analizler kısmında
aranacaktır.
Yrd. Doç. Dr. Serkan ARIKAN
57.
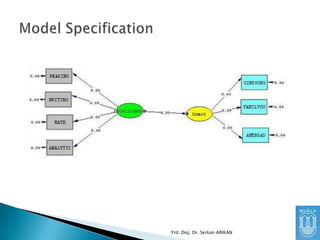
Hangi değişkenleri modelealacaksınız?
Hangi değişkenleri modele almayacaksınız?
Hangi değişkenler bağımlı değişken?
Hangi değişkenler bağımsız değişken?
Değişkenler arasında nasıl ilişkiler olduğunu
öngörüyorsunuz?
Yrd. Doç. Dr. Serkan ARIKAN
58.
Örneğin, X veY yüksek korelasyona sahip.
X mi Y’yi etkiliyor?
Y mi X’i etkiliyor?
Z mi X ve Y’yi etkiliyor?
Yrd. Doç. Dr. Serkan ARIKAN
59.
Eğer, ilişkiler doğrutahmin edilerek kurulmaz
ise, model “hatalı” olacak ve toplanan veri ile
model “uyum” (fit) göstermeyecektir.
Yrd. Doç. Dr. Serkan ARIKAN
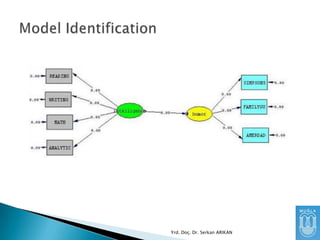
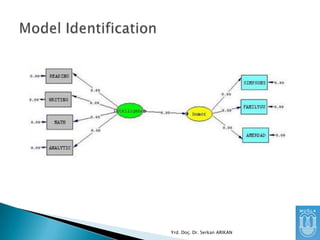
SEM analizlerinde parametrekestirimleri
yapılmadan önce “identification” problemi
çözülmelidir.
Toplanan veriler (kovaryans matrisi) ve
tanımlanan model kullanılarak belirlenmek
istenen parametreler tek bir şekilde (unique)
kestirilebilinir mi?
Yrd. Doç. Dr. Serkan ARIKAN
62.
Örneğin, teorik modelX+Y=bir sayı olsun.
Veriler de X+Y=10 olduğuna işaret etsin.
Çözüm X=5 ve Y= 5 olabilir, X=1 ve Y=9
olabilir.
Buradaki sorun, tek bir çözüm bulunmasına
yetecek kadar “sınırlama” (constraint)
olmamasıdır
X=1 olarak sabitlenerek, bu sorun
çözülebilinir.
Yrd. Doç. Dr. Serkan ARIKAN
63.
SEM’de de benzerdurumlar gözlenebilinir.
Model iyi tanımlanmamış ise “unique”
parametre kestirimi yapılamayabilinir, ve bu
durum bize hata mesajı olarak iletilir.
Yrd. Doç. Dr. Serkan ARIKAN
64.
Modeldeki kestirilecek herparametre
◦ “free” (serbest) parametre
(değeri bilinmeyen ve bu değer kestirilecek
parametredir)
◦ “fixed” (sabitlenmiş) parametre
(değeri sabit bir değere sabitlenmiş, 0 veya 1
parametredir)
◦ “constrained” (sınırlandırılmış) parametre
(değeri bilinmeyen ve başka bir veya birden çok
parametrenin değerine eşitlenen parametredir)
olarak tanımlanır.
Yrd. Doç. Dr. Serkan ARIKAN
Model de butanımlamalar yapıldıktan sonra 3
durumla karşılaşılabilinir
◦ Model “underidentified”
Kovaryans matrisinden elde edilen bilgi sayısı,
kestirilecek parametre sayısından az ise
Bir veya daha fazla parametre “unique” olarak
kestirilemez
Degrees of freedom negatif.
SORUN VAR- “Constraint” eklenebilinir, bazı
değişkenler “fixed” edilebilinir.
Yrd. Doç. Dr. Serkan ARIKAN
67.
Model de butanımlamalar yapıldıktan sonra 3
durumla karşılaşılabilinir
◦ Model “justidentified”
Kovaryans matrisinden elde edilen bilgi sayısı,
kestirilecek parametre sayısına eşit ise
Degrees of freedom 0.
SORUN VAR- “Constraint” eklenebilinir, bazı
değişkenler “fixed” edilebilinir.
Yrd. Doç. Dr. Serkan ARIKAN
68.
Model de butanımlamalar yapıldıktan sonra 3
durumla karşılaşılabilinir
◦ Model “overidentified”
Kovaryans matrisinden elde edilen bilgi sayısı,
kestirilecek parametre sayısından fazla
Degrees of freedom pozitif.
SORUN YOK
Yrd. Doç. Dr. Serkan ARIKAN
69.
Bir veri grubundan tane değişken var ise,
toplam n.(n+1)/2 tane bilgi (varyans ve
covaryans) vardır.
Özetle, bu sayı hesaplanacak parametre
sayısından fazla olmalıdır.
Yrd. Doç. Dr. Serkan ARIKAN
Modeldeki parametreleri kestirmekiçin
birden fazla metot bulunmaktadır.
Parametre kestirim işlemindeki amaç,
Kurgulanan Modelin oluşturduğu kovaryans
matrisi ile Toplanan verinin oluşturduğu
kovaryans matrisi arasında en az fark bulacak
“fonksiyonun” kullanılmasıdır.
Yrd. Doç. Dr. Serkan ARIKAN
72.
Yaygın olarak kullanılankestirim metotları:
ML (Maximum Likelihood)
GLS (Generalized Least Square)
ULS (Ordinary Least Square)
WLS (Weighted Least Square)
Yrd. Doç. Dr. Serkan ARIKAN
73.
ML (Maximum Likelihood)
Eğergözlenen değişkenler sürekli ve çoklu
normal dağılım gösteriyorlar ise ML
kullanmak uygundur.
Lisrel aksi belirtilmedikçe ML kullanır.
Yrd. Doç. Dr. Serkan ARIKAN
74.
WLS (Weighted LeastSquare)
Ordinal datalar var ise WLS kullanılabilinir.
Daha fazla örneklem gerekir.
Normal dağılım koşulu yoktur.
Asymptotic covariance matrix ile covariance
matrix birlikte kullanılmalıdır.
Yrd. Doç. Dr. Serkan ARIKAN
75.
Parametre kestirimleri yapıldıktansonra, elde
edilen verilerin oluşturulan modele ne
seviyede uyum gösterdiği
değerlendirilecektir.
“Teorik model veri ile ne ölçüde
desteklenmektedir?”
Yrd. Doç. Dr. Serkan ARIKAN
76.
Burada 2 önemlideğerlendirme yapılır.
Genel olarak modelin dataya uyumu nasıldır?
Elde edilen parametrelerin modele uyumu
nasıldır?
Yrd. Doç. Dr. Serkan ARIKAN
77.
Genel olarak modelindataya uyumu
değerlendirilirken, pek çok “uyum iyiliği” “fit”
indeksine bakılır.
Yrd. Doç. Dr. Serkan ARIKAN
Parametrelerin uyumu incelenirken
◦Tahmin edilen parametre değerleri sıfırdan anlamlı
olarak farklı mı?
◦ Parametrenin işareti beklenen yönde mi?
◦ (Başarıyı artırması beklenen bir değişken + değere
mi sahip?)
◦ Parametre değerleri mantıklı mı?
◦ (varyanslar pozitif, korelasyonlar 1’den küçük mü)
Yrd. Doç. Dr. Serkan ARIKAN
81.
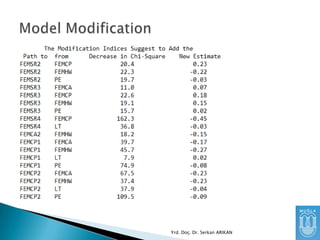
Eğer modelin testedilmesinde elde edilen
değerler istenilen seviyede değil ise, modelin
modifiye edilmesi düşünülebilinir.
Kuramsal alt yapısı olan yeni ilişkiler
tanımlanabilir veya bazı ilişkiler
kaldırılabilinir.
Ardından elde edilen yeni model test edilir.
Yrd. Doç. Dr. Serkan ARIKAN
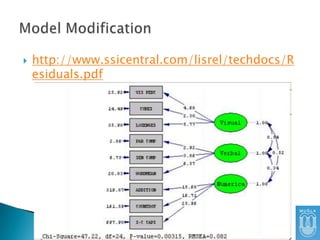
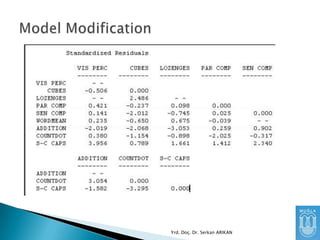
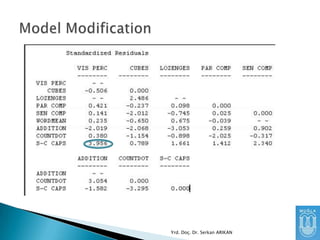
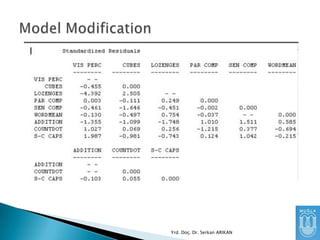
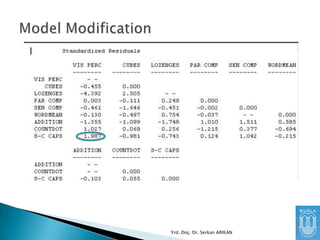
Diğer bir yöntemise “residual” matrix
incelemektir.
Gözlenen Kovaryans Matrisi ile Kurgulanan
Modelin Kovaryans Matrisi arasındaki
farklardan oluşan matristir.
Bu farkların küçük olmasını bekleriz
Yrd. Doç. Dr. Serkan ARIKAN
84.
Farkların büyük olmasımodel ile veri arasında
ciddi bir uyumsuzluk olduğunu gösterir.
Ancak, sadece bir değişken için bu değerler
büyük ise o değişken ile ilgili sorunlar
olduğunu gösterir. O değişken incelenmeli,
kurgulanan ilişkiler gözden geçirilmelidir.
Yrd. Doç. Dr. Serkan ARIKAN
85.
“Standardized Residual” Matrixkullanılırsa,
değerleri yorumlamak daha kolay olur.
Genel olarak 1.96’dan büyük standardized
residual değerleri olan değişkenler arası
uyumsuzluk vardır diye algılanır.
Yrd. Doç. Dr. Serkan ARIKAN
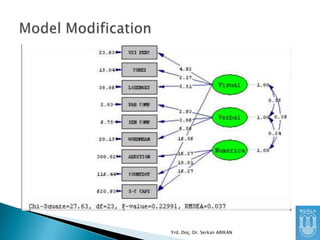
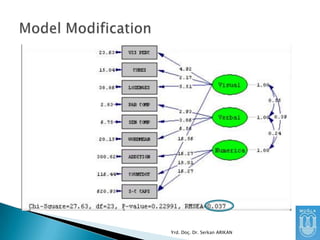
Teorik bir modelile ilgili bir hipotez kurarız.
Data toplarız.
Bu model ile datanın uyumunu test ederiz.
Elde ettiğimiz fit (uyum) değerlerine göre
teorik modeli ya kabul ederiz, ya reddederiz.
Yrd. Doç. Dr. Serkan ARIKAN
94.
A) Ġlk olaraksignificant (anlamlı) olmayan bir
ki-kare değeri bekleriz. Ki-kare değerinin
anlamlı olmaması matrixler arası farkın az
olması, yani modelin dataya uyumlu olduğu
demektir.
Ayrıca, RMSEA değeri gibi daha tutarlı bir
parametrenin 0.05’ten az olması iyi bir
uyumu göstermektedir.
Pekçok uyum iyiliği indisi bulunmaktadır.
Yrd. Doç. Dr. Serkan ARIKAN
B) Model uyumluise modeldeki her “path”in
(yol) ayrı ayrı t değerlerine bakarak anlamlı
olan ilişkileri (yol) belirleriz.
C) Anlamlı olan parametre değerlerinin
“büyüklüklerine” ve “yönlerine” bakarak
yorumlarız.
Anlamlı olmayan ilişkileri de yorumlayabiliriz.
Örneğin, televizyon izlenen saat ile başarı
arasında negatif bir ilişki bulmak garip olmaz.
Yrd. Doç. Dr. Serkan ARIKAN
98.
Pek çok modelfit indisi vardır.
Diğer istatistiksel analizlerde olduğu gibi bu
değerlerin bir dağılımı ve bu sebeple bir
anlamlılık değeri yoktur.
Her indis için kabul gören en az veya en çok
değerler vardır.
Yrd. Doç. Dr. Serkan ARIKAN
99.
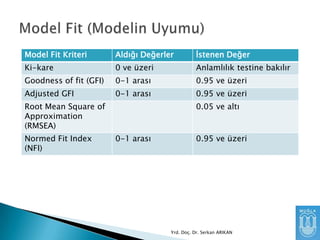
Model Fit Kriteri
AldığıDeğerler
Ġstenen Değer
Ki-kare
0 ve üzeri
Anlamlılık testine bakılır
Goodness of fit (GFI)
0-1 arası
0.95 ve üzeri
Adjusted GFI
0-1 arası
0.95 ve üzeri
Root Mean Square of
Approximation
(RMSEA)
Normed Fit Index
(NFI)
0.05 ve altı
0-1 arası
0.95 ve üzeri
Yrd. Doç. Dr. Serkan ARIKAN
100.
Ki-kare değerini raporlayabilirsinizama kikare değeri örneklemden aşırı etkilenir.
Örneklem çok ise uyumu reddeder.
Örneklem az ise uyumu kabul eder.
Bu sebeple sadece ki-kare raporlamayınız,
diğer indislerle birlikte raporlayınız veya hiç
raporlamayınız.
Yrd. Doç. Dr. Serkan ARIKAN