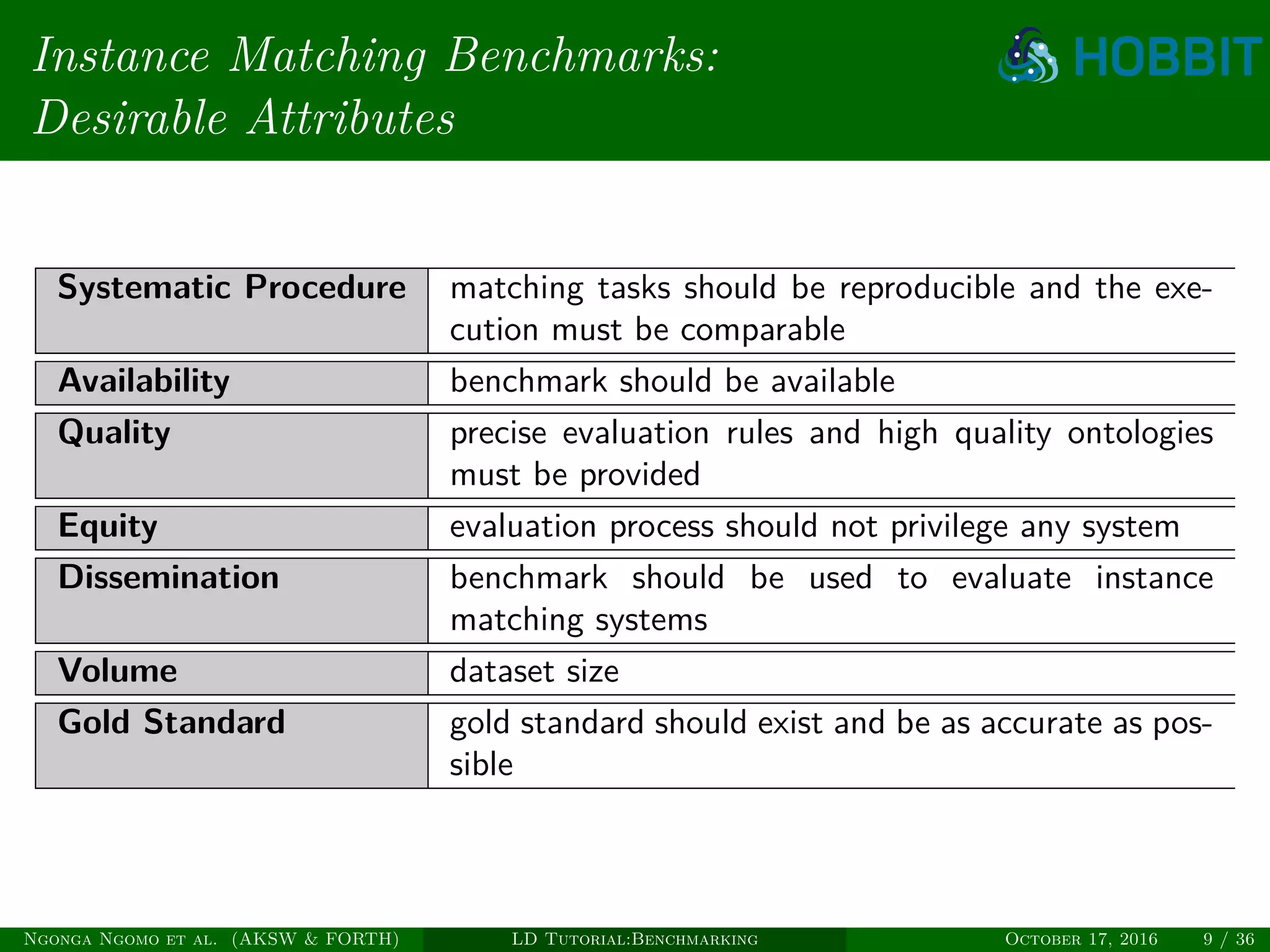
Download to read offline











![Semantic Web Instance Generation
(SWING) [FMN+11]
Semi automatic generator of Instance Matching Benchmarks
Contributed in the generation of IIMB Benchmarks of OAEI in 2010, 2011
and 2012 Instance Matching Tracks
Freely available at (https://code.google.com/p/swing-generator/)
All kind of variations supported into the benchmarks except multilinguality
Automatically produced gold standard
Ngonga Ngomo et al. (AKSW & FORTH) LD Tutorial:Benchmarking October 17, 2016 13 / 36](https://image.slidesharecdn.com/ldtutorialbenchmarking-161108153343/75/Link-Discovery-Tutorial-Part-III-Benchmarking-for-Instance-Matching-Systems-13-2048.jpg)
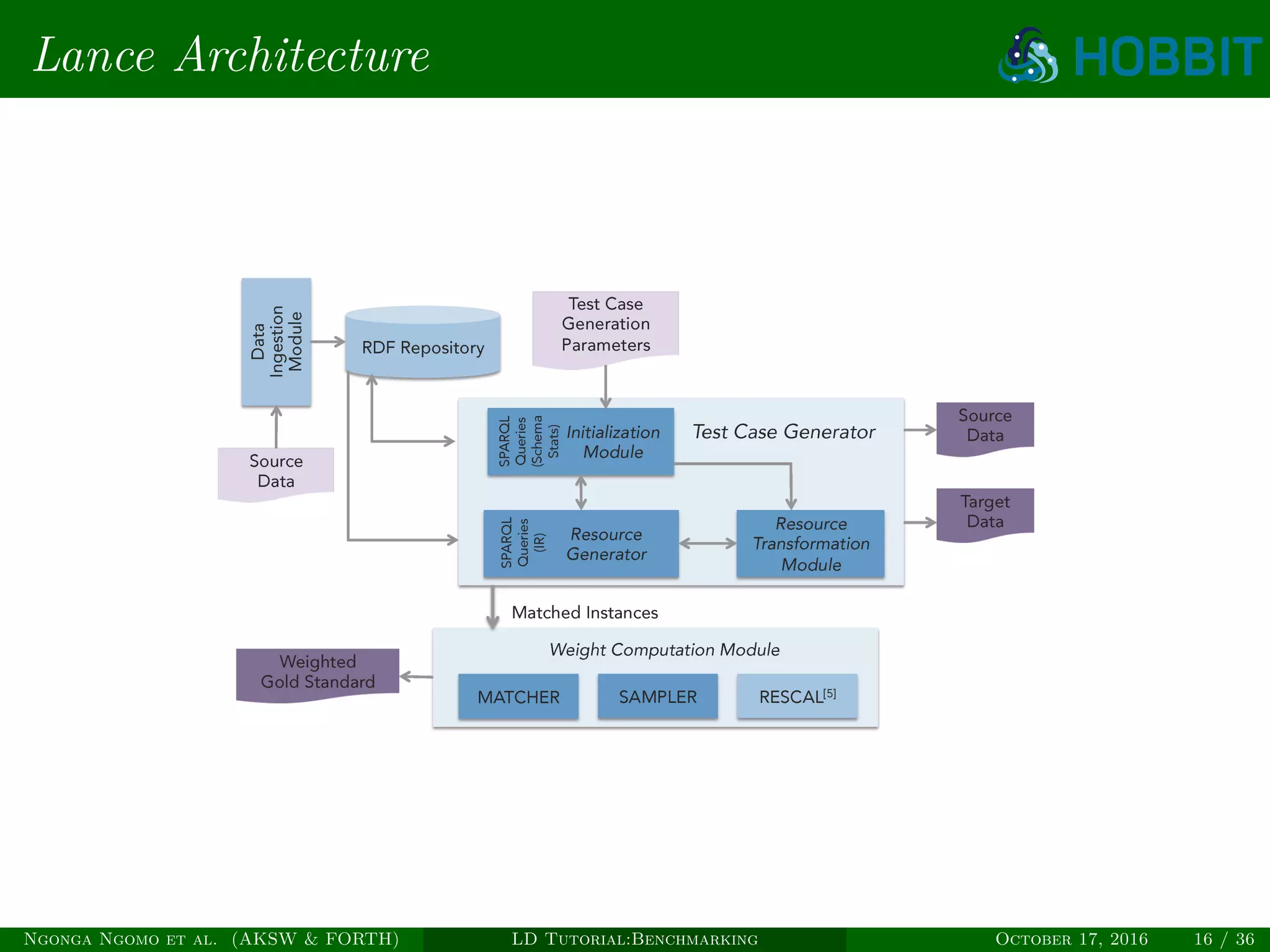
![Lance [SDF+15b]
Flexible, generic and domain-independent benchmark generator which takes
into consideration RDFS and OWL constructs in order to evaluate instance
matching systems.
Ngonga Ngomo et al. (AKSW & FORTH) LD Tutorial:Benchmarking October 17, 2016 14 / 36](https://image.slidesharecdn.com/ldtutorialbenchmarking-161108153343/75/Link-Discovery-Tutorial-Part-III-Benchmarking-for-Instance-Matching-Systems-14-2048.jpg)
![Lance [SDF+15b]
Lance provides support for:
Semantics-aware transformations
Complex class definitions (union, intersection)
Complex property definitions (functional properties, inverse functional
properties)
Disjointness (properties)
Standard value and structure based transformations
Weighted gold standard based on tensor factorization
Varying degrees of difficulty and fine-grained evaluation metrics
Available at http://github.com/jsaveta/Lance
Ngonga Ngomo et al. (AKSW & FORTH) LD Tutorial:Benchmarking October 17, 2016 15 / 36](https://image.slidesharecdn.com/ldtutorialbenchmarking-161108153343/75/Link-Discovery-Tutorial-Part-III-Benchmarking-for-Instance-Matching-Systems-15-2048.jpg)
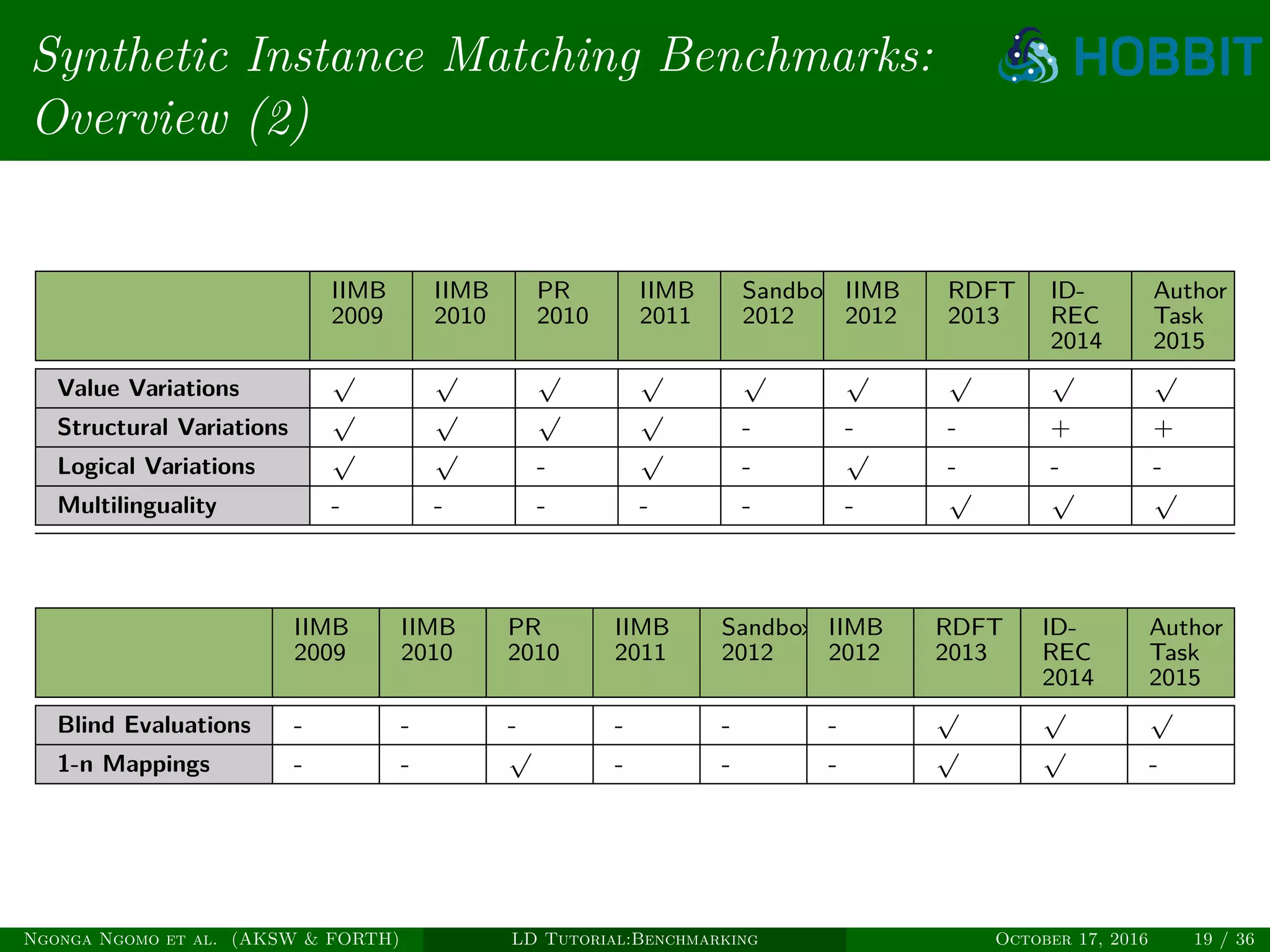
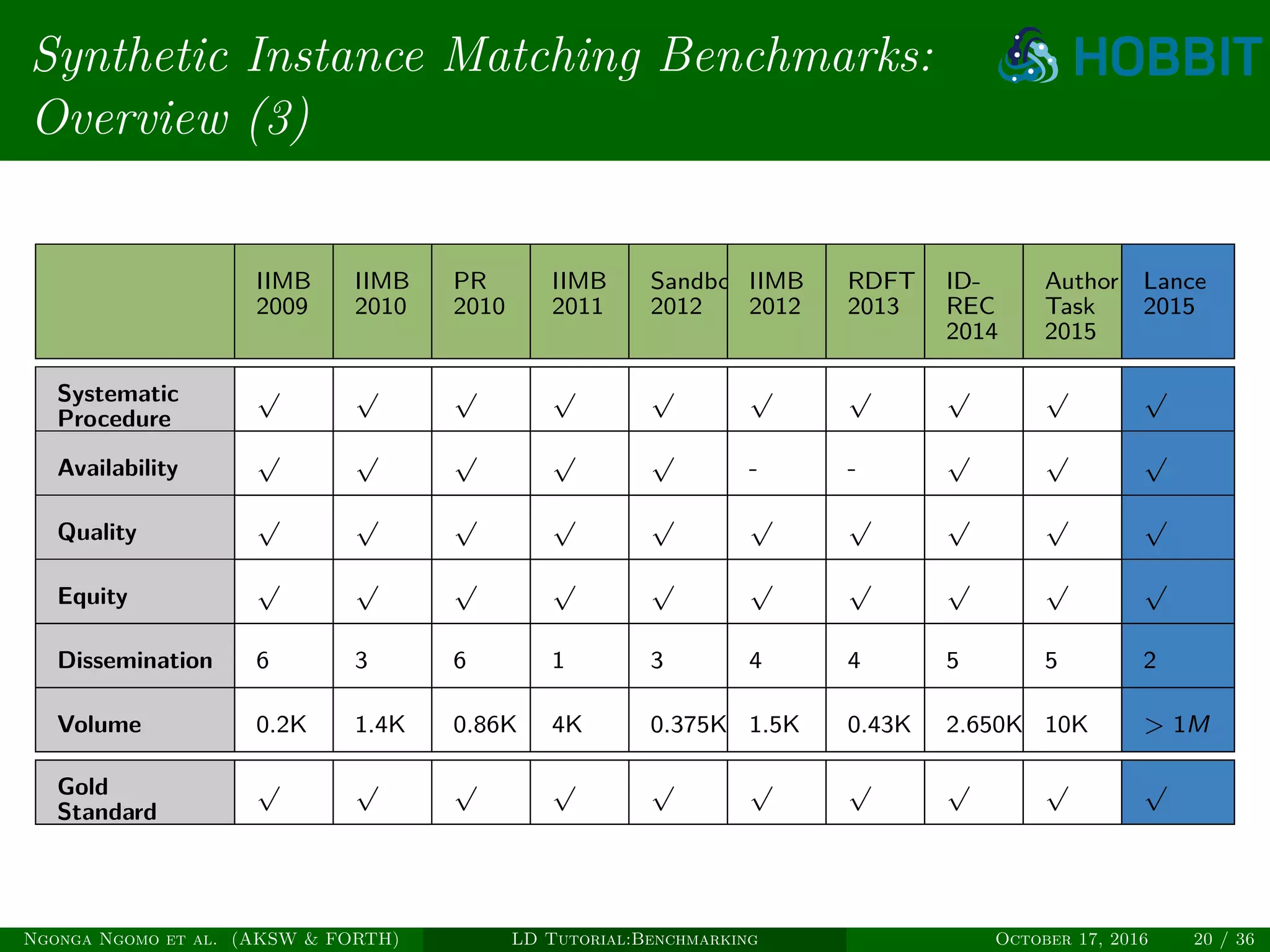
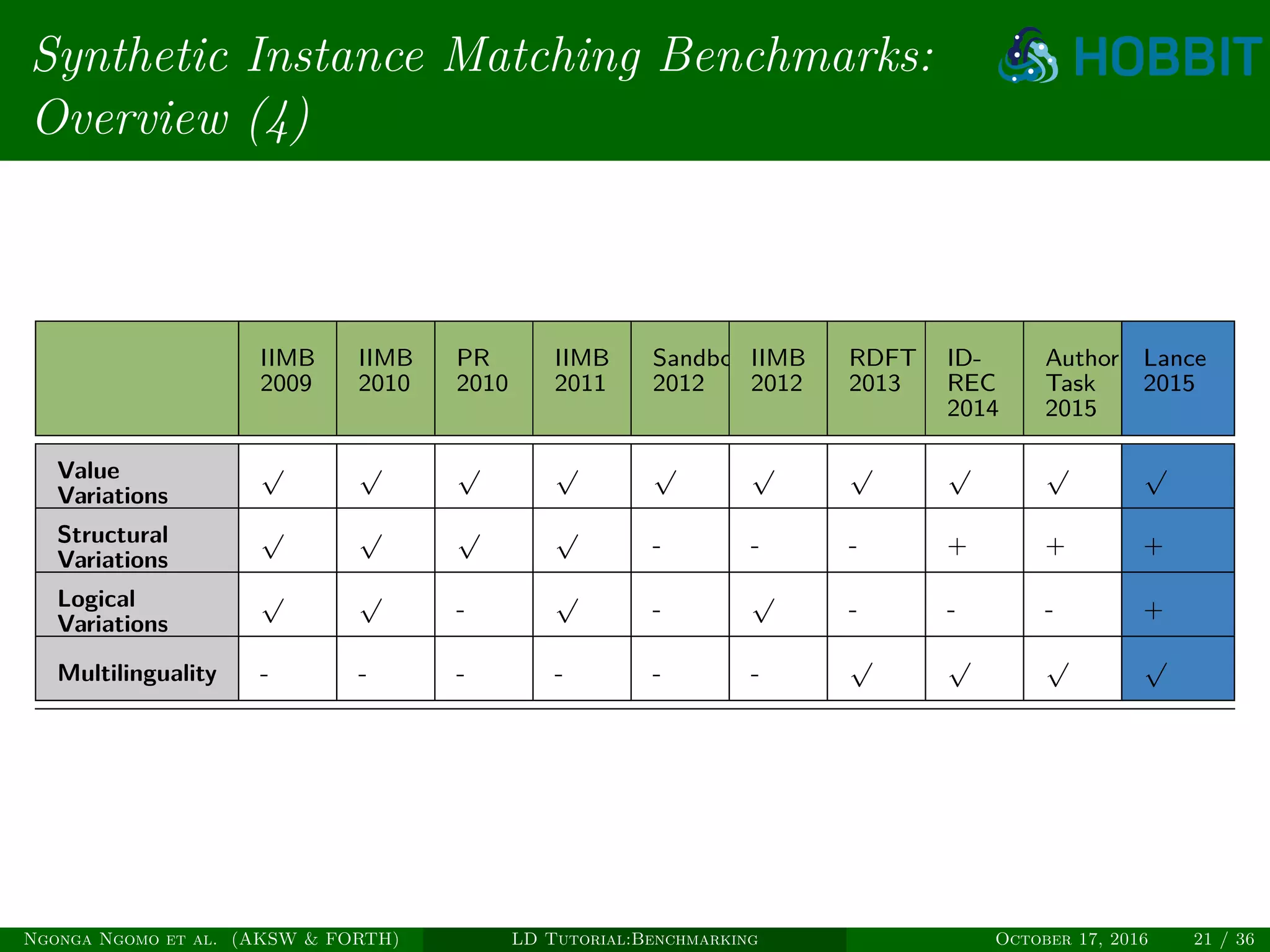
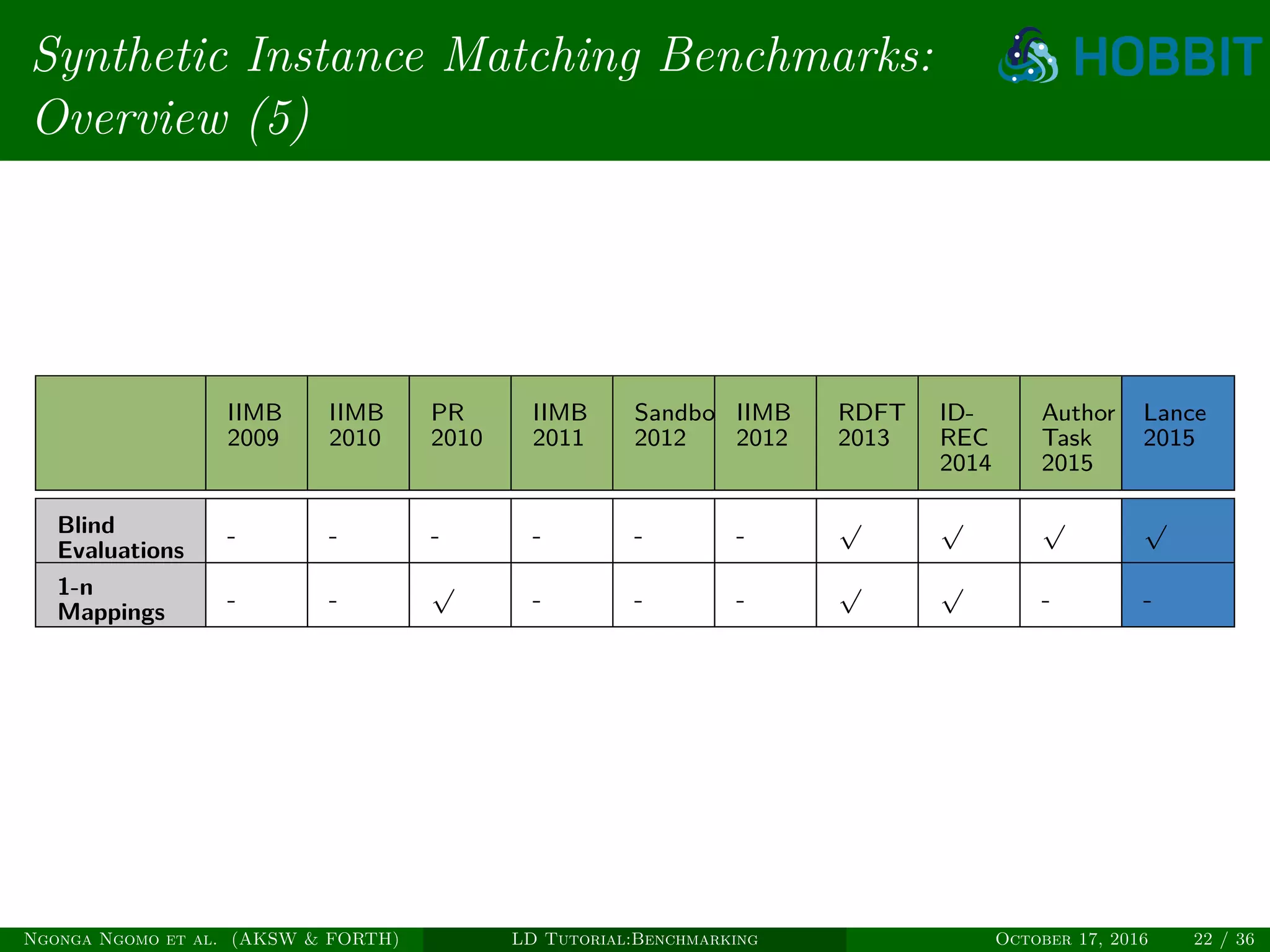

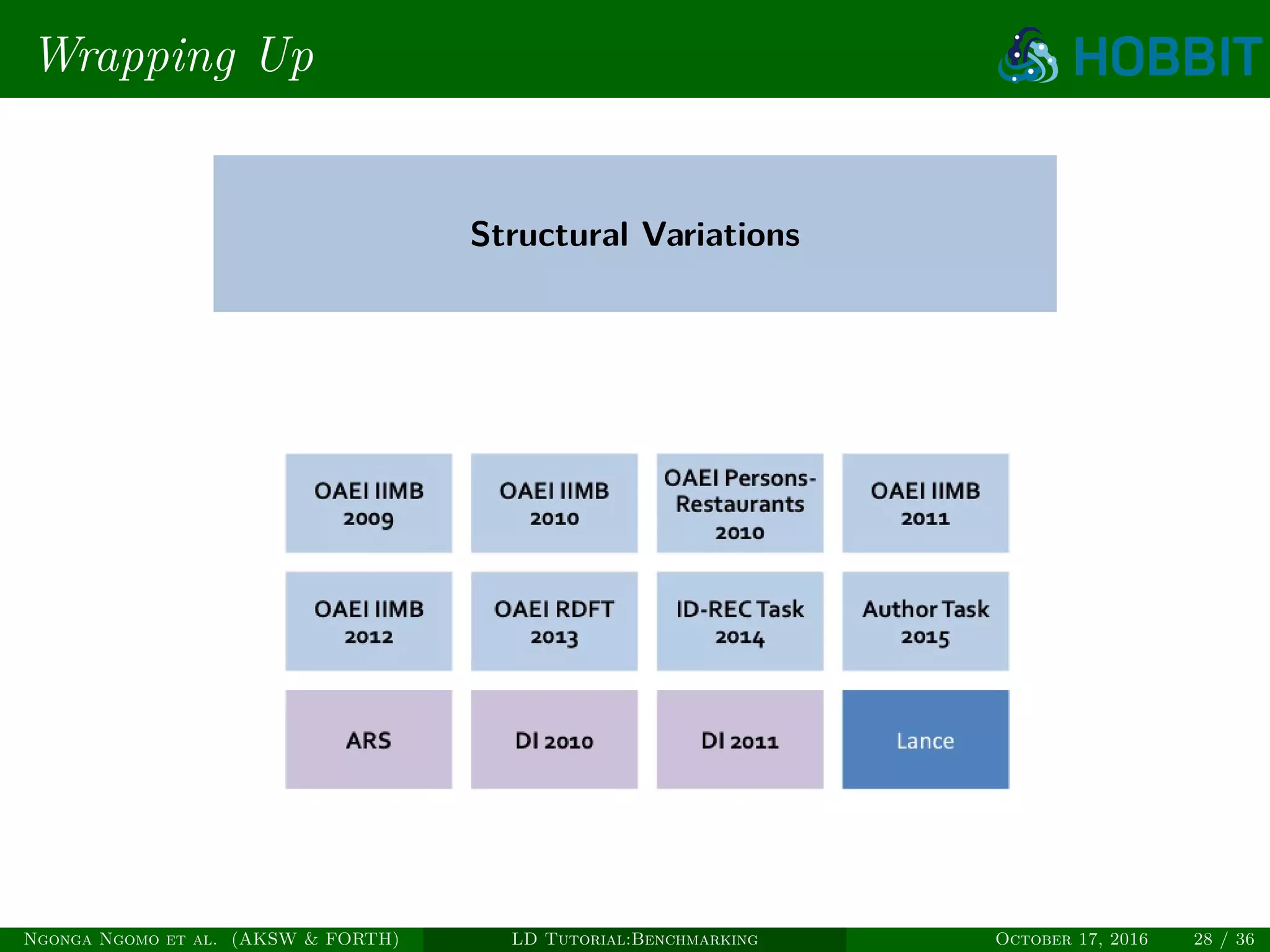

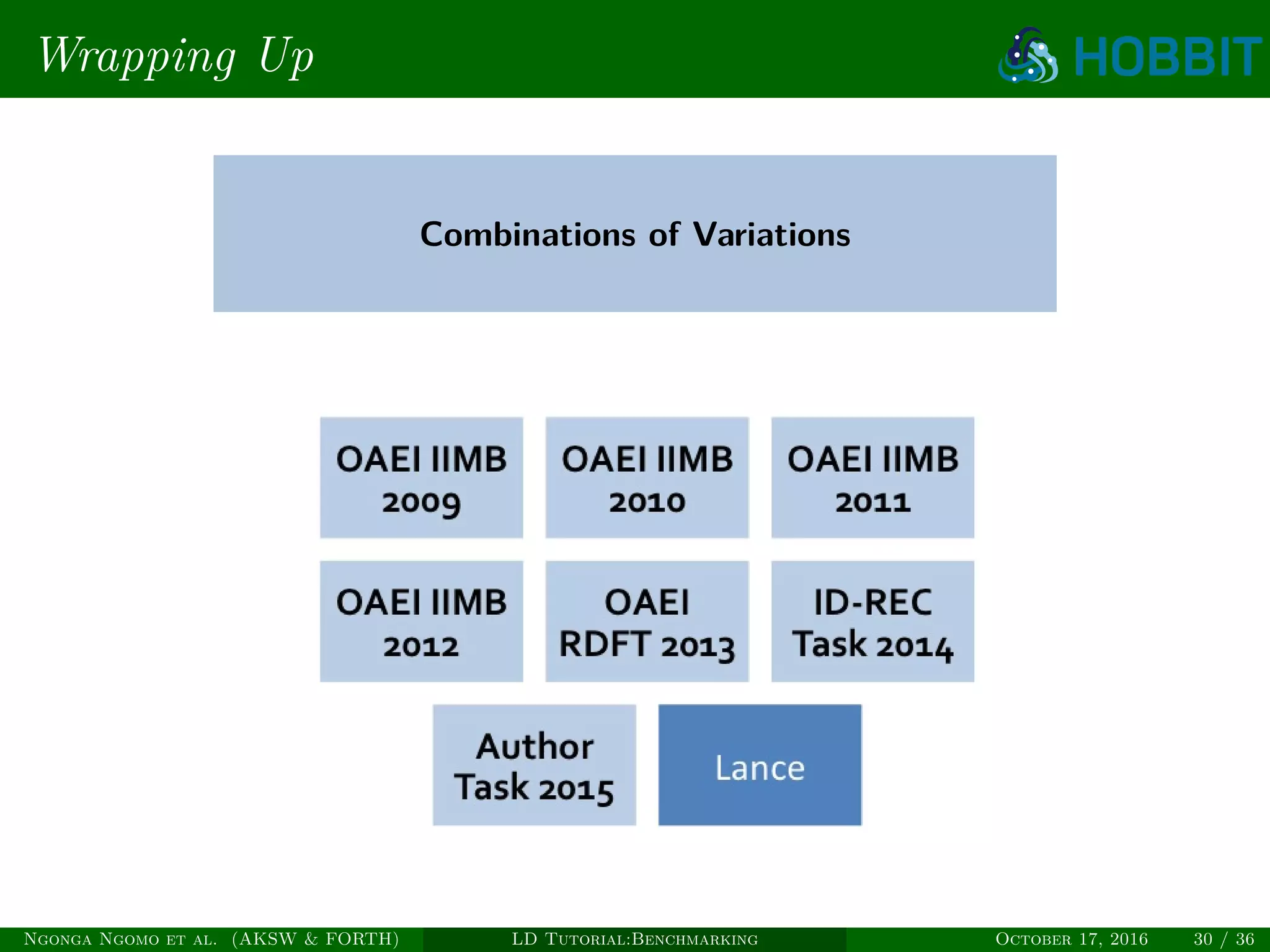







The document is a tutorial on benchmarking instance matching systems, discussing the importance, methodologies, and characteristics of effective benchmarks. It emphasizes the need for standardized evaluation processes to measure the performance of various tools and promote improvement in instance matching technologies. Additionally, it highlights the existing benchmarks, their attributes, and calls for advancements to address complex variations and scalability challenges in the field.























































































