Download as PDF, PPTX




![Past: Automated Software Testing
• 10 years of collaboration with Microsoft Research on Pex
• .NET Test Generation Tool based on Dynamic Symbolic Execution
• Example Challenges
• Path explosion [DSN’09: Fitnex]
• Method sequence explosion [OOPSLA’11: Seeker]
• Shipped in Visual Studio 2015/2017 Enterprise Edition
• As IntelliTest
• Code Hunt [ICSE’15 JSEET] w/ > 6 million (6,114,978) users after 3.5 years
• Including registered users playing on www.codehunt.com, anonymous users and
accounts that access http://api.codehunt.com/ directly via the documented REST
APIs) https://www.codehunt.com/
http://taoxie.cs.illinois.edu/publications/ase14-pexexperiences.pdf](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-6-320.jpg)
![Past: Android App Testing
• 2 years of collaboration with Tencent Inc. WeChat testing team
• Guided Random Test Generation Tool improved over Google Monkey
• Resulting tool deployed in daily WeChat testing practice
• WeChat = WhatsApp + Facebook + Instagram + PayPal + Uber …
• #monthly active users: 963 millions @2017 2ndQ
• Daily#: dozens of billion messages sent, hundreds of million photos uploaded,
hundreds of million payment transactions executed
• First studies on testing industrial Android apps
[FSE’16IN][ICSE’17SEIP]
• Beyond open source Android apps
focused by academia
WeChat
http://taoxie.cs.illinois.edu/publications/esecfse17industry-replay.pdf
http://taoxie.cs.illinois.edu/publications/fse16industry-wechat.pdf](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-7-320.jpg)
![Next: Intelligent Software Testing(?)
• Learning from others working on the same things
• Our work on mining API usage method sequences to test the API
[ESEC/FSE’09: MSeqGen]
• Visser et al. Green: Reducing, reusing and recycling constraints in program
analysis. FSE’12.
• Learning from others working on similar things
• Jia et al. Enhancing reuse of constraint solutions to improve symbolic execution.
ISSTA’15.
• Aquino et al. Heuristically Matching Solution Spaces of Arithmetic Formulas to
Efficiently Reuse Solutions. ICSE’17.
[Jia et al. ISSTA’15]](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-8-320.jpg)
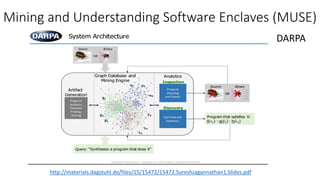

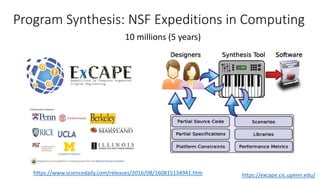
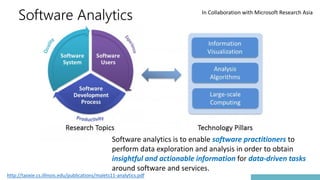
![Past: Software Analytics
• StackMine [ICSE’12, IEEESoft’13]: performance debugging in the large
• Data Source: Performance call stack traces from Windows end users
• Analytics Output: Ranked clusters of call stack traces based on shared patterns
• Impact: Deployed/used in daily practice of Windows Performance Analysis team
• XIAO [ACSAC’12, ICSE’17 SEIP]: code-clone detection and search
• Data Source: Source code repos (+ given code segment optionally)
• Analytics Output: Code clones
• Impact: Shipped in Visual Studio 2012; deployed/used in daily practice of
Microsoft Security Response Center
In Collaboration with Microsoft Research Asia
Internet](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-14-320.jpg)
![Past: Software Analytics
• Service Analysis Studio [ASE’13-EX]: service incident management
• Data Source: Transaction logs, system metrics, past incident reports
• Analytics Output: Healing suggestions/likely root causes of the given incident
• Impact: Deployed and used by an important Microsoft service (hundreds of
millions of users) for incident management
In Collaboration with Microsoft Research Asia](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-15-320.jpg)

![18
Existing Approaches on NL Regular Expressions
[Ranta 1998], [Kushman and Barzilay 2013], [Locascio et al. 2016]
Used only synthetic data for training and testing
Are these approaches effective to address
real-world situations ?
Deep Learning for NLRegex: Get Real!
Zhong et al. Generating Regular Expressions from Natural Language Specifications: Are We There Yet? In AAAI 2018
Workshop on NLP for Software Engineering (NL4SE 2018)
http://taoxie.cs.illinois.edu/publications/nl4se18-regex.pdf](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-18-320.jpg)
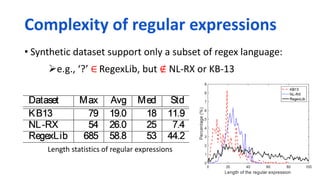
![Synthetic datasets
KB13 [Kushman and Barzilay 2013] (824 pairs)
Write NL sentences to capture the examples strings
NL-RX [Locascio et al., 2016] (10,000 pairs)
Parse a regex and generate initial NL sentences based on a predefined grammar
Paraphrase the generated sentences
Real-world dataset
RegexLib (3,619 pairs)
From regexlib.com
19
Characteristic Study](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-19-320.jpg)

![Deep-Regex [Locascio et al. 2016]
Regular expression generation Machine translation
22
Experimental Study
Sequence-to-sequence learning
https://github.com/nicholaslocascio/deep-regexhttps://aclweb.org/anthology/D/D16/D16-1197.pdf](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-22-320.jpg)


![Variations of NL sentences
NL-RX: NL sentences are generated from a predefined grammar
Augmenting training data may alleviate the error
Numerical range
25
New Causes of Errors on Real-world Dataset
Description Ground Truth Predicted Result
Match the numbers 100 to 199. 1[0-9][0-9] ([0-9])*](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-25-320.jpg)

![String test cases can handle the ambiguity of NL sentences
String test cases can differentiate regular expression candidates
help select the best candidate during beam search
27
Description Ground Truth Predicted Result
Items with a small letter preceding “dog”,
at least thrice
([a-b].*dog.*){3,} ([a-b]).*((dog){3,})
Test case:“adogadogadog”
Ongoing Work: Testability of Regular Expressions](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-27-320.jpg)




![Microsoft's Teen Chatbot Tay
Turned into Genocidal Racist (2016 March 23/24)
http://www.businessinsider.com/ai-expert-explains-why-microsofts-tay-chatbot-is-so-racist-2016-3
"There are a number of precautionary
steps they [Microsoft] could have taken.
It wouldn't have been too hard to create
a blacklist of terms; or narrow the scope
of replies. They could also have simply
manually moderated Tay for the first few
days, even if that had meant slower
responses."
“businesses and other AI developers will
need to give more thought to the
protocols they design for testing and
training AIs like Tay.”](https://image.slidesharecdn.com/isec18keynote-ise-180210165205/85/ISEC-18-Keynote-Intelligent-Software-Engineering-Synergy-between-AI-and-Software-Engineering-34-320.jpg)


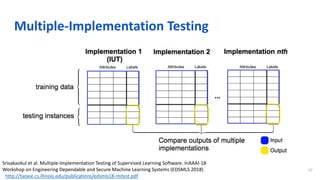

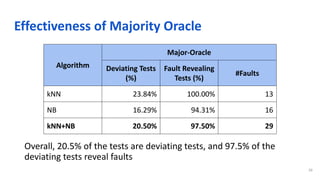
















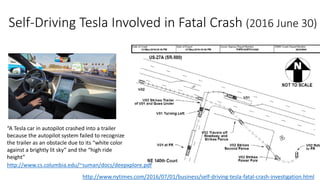
The document discusses the integration of artificial intelligence in software engineering, emphasizing the historical and ongoing efforts in intelligent software testing and analytics. It covers various collaborations, tools, and research conducted by organizations like Microsoft and Tencent, along with challenges faced in software analytics and machine learning testing. The outline includes past achievements, future directions, and the importance of collaboration in addressing complex problems in software engineering.




















































































