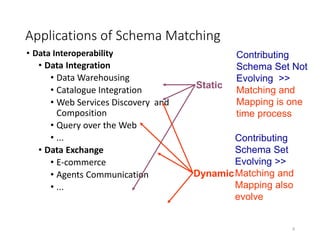
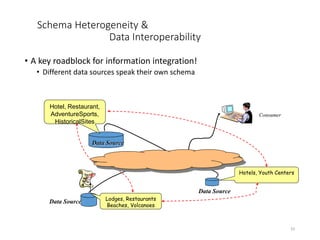
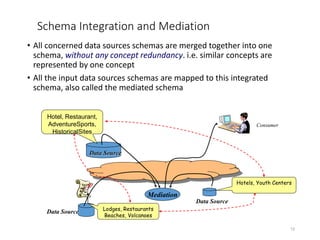
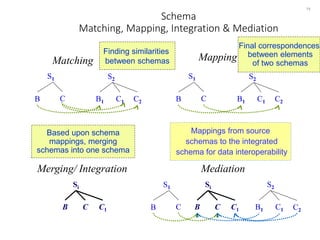
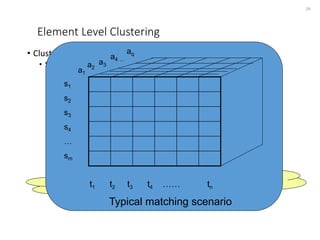
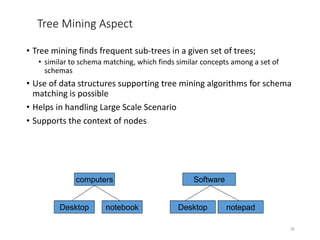
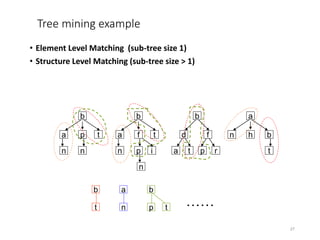
The document discusses schema matching and integration for large scale scenarios. It proposes handling schemas as trees and applying a hybrid approach involving clustering the schema elements based on label similarity, performing tree mining to find similar sub-trees, and developing a mediated schema through an automated matching, mapping, and integration process to enable data interoperability across large, heterogeneous schemas.







![Schema Matching
7
• Takes two schemas/ontologies as input and produces a
mapping between elements of the two schemas that
correspond semantically to each other [Halevy05]
1-1 match
complex match
26,60 Harry Potter J. K. Rowling
11,50 Marie Des Juliette Benzoni
Intrigues
16,50 Nous Les Bernard Werber
Dieux
24 Pompei Robert Harris
price book-title author-name
Books
Source A
listed-price title a-fname a-lname
Books
Source B](https://image.slidesharecdn.com/lecture05-schemamatching-230202070451-1e25f2d9/85/Lecture-05-SchemaMatching-ppt-7-320.jpg)


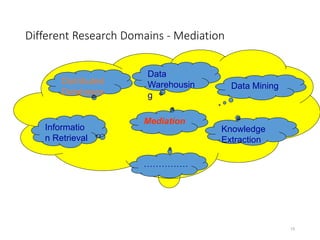
![Mediation
Schema Mapping is key to any data sharing architecture
13
[Tomasic et al. IEEE TKDE 1998].
Mediated Schema
Source n
Source 1 Source 2
mappings
...
wrapper wrapper wrapper
User Query
sub-query
sub-query
sub-query](https://image.slidesharecdn.com/lecture05-schemamatching-230202070451-1e25f2d9/85/Lecture-05-SchemaMatching-ppt-13-320.jpg)


![Related Work
18
Pre-Match
eTuner
[Lee&Doan 07]
Amid-Match
SCIA
[Wang et al 07]
Post-Match
COMA++
[Do et al 07,
Manakanatas06]
Tuning approach
Large Scale Schema Matching and
Integration Approaches
Incremental Holistic
Fragmentation Clustering Mining
Data-mining
Element
Level
Schema
Level
Tree-mining
COMA++
[Do&Rahm07]
BellFlower
[Smiljanic06]
DCM [He et al 04]
xClust
[Lee et al 02]
PORSCHE
[Saleem et al 08]](https://image.slidesharecdn.com/lecture05-schemamatching-230202070451-1e25f2d9/85/Lecture-05-SchemaMatching-ppt-18-320.jpg)

![From city or airport* To city or airport*
I f y o u a r e u n s u r e o f t h e s p e l l i n g o f a c i t y o r a i r p o r t , e n t e r t h e
f i r s t 3 o r m o r e l e t t e r s f o l l o w e d b y a n a s t e r i s k ( * ) .
Departure date Departure time
Jul 2008 23 Any Time
Wednesday
Return Date Return time
Jul 2008 24 Any Time
Thursday
Traveler types
Adults
(12-64 yrs)
1
Children
(2-11 yrs)
0
Seniors
(65+ yrs)
0
Infants (0-
23 months)
0
Cabin type
Coach
Direct or Non-Stop flights only
More search options
20
Schemas as trees – Web Interface Forms
absTravel
From
D_City
To
A_City
Departure
Date
D_Month
D_Day
D_Time
Return
Date
R_Month
R_Day
R_Time
CabinType
TravelerTypes
Adults
Children
Seniors
Infants
absTravel
D_City
D_Day
Return
D_Month
Departure
A_City
D_Time
CabinType
Adults
Children
Seniors
Infants
D_Day
D_Month
D_Time
TravlerTypes
From
To
Date
Date
[He et al. KDD 2004]](https://image.slidesharecdn.com/lecture05-schemamatching-230202070451-1e25f2d9/85/Lecture-05-SchemaMatching-ppt-20-320.jpg)
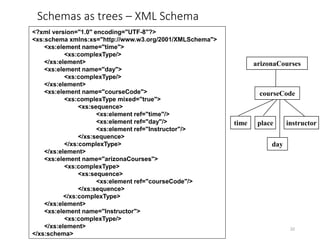
![Schemas as trees – Relational Database
21
books
book_id
author_id
author
detail
name
publisher
title
pub_id name
book_id
book
title
author_id
author
name pub_id
publisher
name
book_id
detail
author_id pub_id
books
[Lee et al. CIKM 2006]](https://image.slidesharecdn.com/lecture05-schemamatching-230202070451-1e25f2d9/85/Lecture-05-SchemaMatching-ppt-21-320.jpg)



![[Evaldas Taroza - Master thesis] Schema Matching and Automatic Web Data Extra...](https://cdn.slidesharecdn.com/ss_thumbnails/5c1568bc-753d-44dc-88ac-dcf114742b88-150313043325-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































