Meet Lalli
When Buddyhears, “Feeling hungry, I
would like to have some…”, She is
statistically more likely to say “biryani”,
“cherries”, or “food” rather than
unrelated words like “bicycle” or “book”
because of exposure frequency.
5.
Introducing LLMs
Computer programswhich use neural
networks to predict the next set of words
in a sentence based on historical data
patterns.
For example, a language model trained on
all movie-related Wikipedia articles can
predict movie-related sentences well, and
real-world applications like Gmail
autocomplete rely on such models.
6.
Lalli with divinepowers
She can overhear conversations
neighborhood-wide, across schools,
universities, and even globally, she’d have
much broader knowledge
With this massive exposure, Buddy could
now generate predictions about history,
nutrition, or poetry, demonstrating the
broad capabilities
7.
How LLMs learn?
●LLMs are trained on vast amounts of text
data from the internet (books, articles,
websites, conversations).
● The Goal: To predict the next word in a
sequence. This seems simple but forces the
model to learn grammar, facts, reasoning,
and even some creativity.
● Technique: Self-supervised learning – the
data itself provides the supervision.
● Example: If the model sees "The cat sat on
the...", it learns that "mat," "rug," or "couch"
are likely next words.
8.
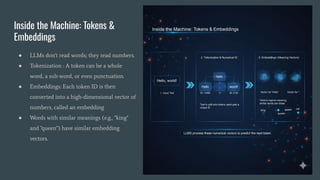
Inside the Machine:Tokens &
Embeddings
● LLMs don't read words; they read numbers.
● Tokenization : A token can be a whole
word, a sub-word, or even punctuation.
● Embeddings: Each token ID is then
converted into a high-dimensional vector of
numbers, called an embedding
● Words with similar meanings (e.g., "king"
and "queen") have similar embedding
vectors.
9.
Reinforcement Learning with
HumanFeedback (RLHF)
RLHF: a method where humans guide the
model’s responses by labeling outputs as “good”
or “toxic”
10.
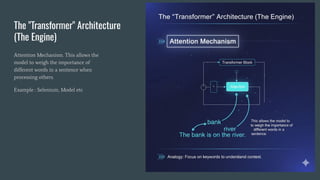
The "Transformer" Architecture
(TheEngine)
Attention Mechanism. This allows the
model to weigh the importance of
different words in a sentence when
processing others.
Example : Selenium, Model etc
11.
Key LLM Parameters(The Control
Knobs)
● Context Window: The maximum number of
tokens (words or sub-words) the model can
consider at one time.
● Temperature: Controls the randomness and
creativity of the output
● Top-P (Nucleus Sampling): Filters the next
word choices based on a cumulative
probability threshold.
● Top-K: Limits the model's choices to the top k
most probable words for the next token,
regardless of their probability.
● Frequency/Presence Penalty: Discourages the
model from repeating the same words or
phrases.
Prompt Engineering
● TheArt and Science of
Communication with AI
● Guiding AI Behavior
● Maximizing AI Value
● Key components: Clarity, Context,
Constraints.
14.
Common pitfalls
● Vagueprompts → irrelevant output
● No context → misses edge cases
● Overly complex prompts → AI
ignores instructions
● Forgetting QA verification → always
validate AI-generated test cases
15.
The Four Pillarsof a Good
Prompt
● Persona: Who should the AI
pretend to be? (e.g., "You are a
senior QA analyst...")
● Task: What exactly do you want
it to do? (e.g., "Your task is to
identify security
vulnerabilities...")
● Context: What background
information does it need? (e.g.,
"The website is
example-shop.com...")
● Format: How should the output
be structured? (e.g., "Present
your findings in a bulleted
list...")
16.
Basic Prompting Demo
●Scenario: You're testing an e-commerce
login page.
● Prompt (Good Example):
"You are a senior QA analyst. Your task is to
identify potential security vulnerabilities in
the login form of an e-commerce website.
The website is example-shop.com. Analyze
the form for common vulnerabilities like
SQL injection, cross-site scripting (XSS),
and weak password policies. Present your
findings in a bulleted list."
17.
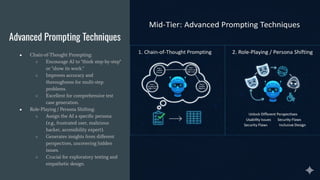
Advanced Prompting Techniques
●Chain-of-Thought Prompting:
○ Encourage AI to "think step-by-step"
or "show its work."
○ Improves accuracy and
thoroughness for multi-step
problems.
○ Excellent for comprehensive test
case generation.
● Role-Playing / Persona Shifting:
○ Assign the AI a specific persona
(e.g., frustrated user, malicious
hacker, accessibility expert).
○ Generates insights from different
perspectives, uncovering hidden
issues.
○ Crucial for exploratory testing and
empathetic design.
18.
Advanced Prompt Template
●Persona: [Role the AI should adopt, e.g., "Senior QA Analyst," "Security Auditor," "End User"]
● Context: [System or Feature being tested, e.g., "E-commerce checkout flow," "User registration API," "Mobile
banking app's transfer feature"]
● Task: [Specific action verb and goal, e.g., "Generate test cases," "Identify vulnerabilities," "Analyze user feedback
for patterns"]
● Method (Optional but Recommended): [Specify a technique like "Chain-of-Thought," "Role-Play," "A/B
comparison"]
● Format: [Desired output style, e.g., "Bulleted list," "Table with columns: ID, Description, Expected Result," "JSON,"
"Markdown narrative"]
● Constraints: [Limitations or specific rules, e.g., "No more than 10 test cases," "Exclude scenarios involving credit
card numbers," "Focus only on payment processing"]
● Examples (Optional): [Provide input/output examples if the task or format is complex]
19.
Markdown Best Practicesfor Effective QA Prompts
● Headings (#, ##, ###): Organize sections
● Bulleted Lists (-): Enumerate test cases
● Numbered Lists (1.): Sequential steps
● Tables: Structured test cases
● Code Blocks (```): Scripts or JSON
● Bold/Italics: Highlight constraints
● Checklists (- [ ]): Exploratory QA tracking
20.
Hands-On Mini Project:
PostCreation Feature
Your Task: Work with a neighbor.
You are all QA engineers for a
new social media app. The
feature under test is post
creation.
Feature Details: Users can write
text (limit 280 chars), upload
one image (JPG/PNG, max
5MB), and add an optional
location.
Prompt
21.
Best Practices &Future Outlook
● Iterate and Refine: Your first prompt
might not be perfect. Experiment!
● Be Specific, but Concise: Avoid ambiguity,
but don't add unnecessary filler.
● Use Examples: If the output format is
complex, provide a small example.
● Understand AI Limitations: AI can
hallucinate or generate plausible-sounding
but incorrect information. Always verify
critical outputs.
















![Advanced Prompt Template
● Persona: [Role the AI should adopt, e.g., "Senior QA Analyst," "Security Auditor," "End User"]
● Context: [System or Feature being tested, e.g., "E-commerce checkout flow," "User registration API," "Mobile
banking app's transfer feature"]
● Task: [Specific action verb and goal, e.g., "Generate test cases," "Identify vulnerabilities," "Analyze user feedback
for patterns"]
● Method (Optional but Recommended): [Specify a technique like "Chain-of-Thought," "Role-Play," "A/B
comparison"]
● Format: [Desired output style, e.g., "Bulleted list," "Table with columns: ID, Description, Expected Result," "JSON,"
"Markdown narrative"]
● Constraints: [Limitations or specific rules, e.g., "No more than 10 test cases," "Exclude scenarios involving credit
card numbers," "Focus only on payment processing"]
● Examples (Optional): [Provide input/output examples if the task or format is complex]](https://image.slidesharecdn.com/llmpromptengineering1-250922064652-c48011f9/85/Large-Language-Models-Prompt-Engineering-18-320.jpg)
![Markdown Best Practices for Effective QA Prompts
● Headings (#, ##, ###): Organize sections
● Bulleted Lists (-): Enumerate test cases
● Numbered Lists (1.): Sequential steps
● Tables: Structured test cases
● Code Blocks (```): Scripts or JSON
● Bold/Italics: Highlight constraints
● Checklists (- [ ]): Exploratory QA tracking](https://image.slidesharecdn.com/llmpromptengineering1-250922064652-c48011f9/85/Large-Language-Models-Prompt-Engineering-19-320.jpg)





![[BEDROCK] Claude Prompt Engineering Techniques.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bedrockclaudepromptengineeringtechniques-231213183236-1d873607-thumbnail.jpg?width=640&height=640&fit=bounds)

































































