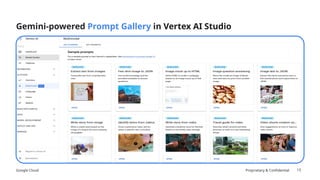
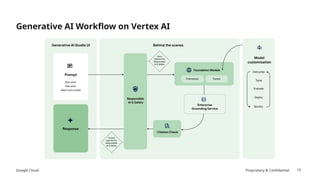
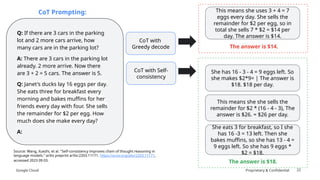
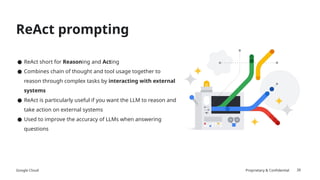
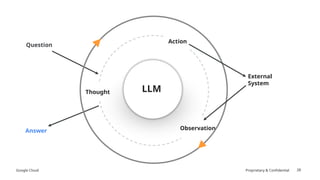
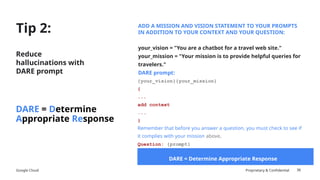
The document discusses prompt engineering techniques for optimizing interactions with large language models (LLMs) on Google Cloud's Vertex AI, including contextual prompting, examples, and advanced strategies like chain-of-thought and react prompting. It emphasizes best practices such as specificity, including structured text, and ensuring responsible AI use with safety filters. Additionally, it highlights the importance of evaluation prompts and tuning methods to enhance model performances.




![What does LLM do?
The cat sat on the
[...] [...] [...] [...] [...]
[...]
mat rug chair
Most likely
next word
Most likely
next word
Less likely
next word
…](https://image.slidesharecdn.com/exploringpromptengineering-241027124134-77d0c136/85/Exploring-prompt-engineering-in-depth-overview-4-320.jpg)



![Google Cloud Proprietary & Confidential
Add contextual information in your
prompt when you need to give
information to the model, or restrict
the boundaries of the responses to
only what's within the prompt.
Marbles:
Color: blue
Number: 28
Color: yellow
Number: 15
Color: green
Number: 17
How many green marbles are there?
Including examples in the
prompt is an effective strategy
for customizing the response
format.
Classify the following.
Options:
- red wine
- white wine
Text: Chardonnay
The answer is: white wine
Text: Cabernet
The answer is: red wine
Text: Riesling
The answer is:
8
Prompts can include one or more of the following types of
content
Question input:
What's a good name for a flower
shop that specializes in selling
bouquets of
dried flowers?
Task input:
Give me a list of things that I should
bring with me to a camping trip.
Entity input:
Classify the following as [large,
small].
Elephant
Mouse
Completion input:
Some strategies to overcome
writer's block include …
Input Context Examples](https://image.slidesharecdn.com/exploringpromptengineering-241027124134-77d0c136/85/Exploring-prompt-engineering-in-depth-overview-8-320.jpg)

![Google Cloud Proprietary & Confidential
Temperature
10
Knobs and levers
Tune the degree
of randomness.
Choose from the smallest set
of words whose cumulative
probability >= P.
Only sample from
the top K tokens.
Takes a value between 0 and 1
0 = always brings the most likely next token
...
1 = selects from a long list of options, more
random or “creative”
P = 0.8
[flowers (0.5),
trees (0.23),
herbs (0.07),
...
bugs (0.0003)]
K = 2
[flowers (0.5),
trees (0.23),
herbs (0.07),
...
bugs (0.0003)]
Top P Top K
(YOUR IMPACT ON THE “RANDOMNESS”)](https://image.slidesharecdn.com/exploringpromptengineering-241027124134-77d0c136/85/Exploring-prompt-engineering-in-depth-overview-10-320.jpg)
























![Google Cloud Proprietary & Confidential
Tip 9:
Always remember
Responsible AI and
safety filters
44
Gemini makes it easy to set safety settings in 3 steps
1. from vertexai.preview.generative_models import (
GenerationConfig,
GenerativeModel,
HarmCategory,
HarmBlockThreshold,
Image)
2. safety_config={
HarmCategory.HARM_CATEGORY_HARASSMENT:
HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
HarmCategory.HARM_CATEGORY_HATE_SPEECH:
HarmBlockThreshold.BLOCK_ONLY_HIGH,
HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT:
HarmBlockThreshold.BLOCK_ONLY_HIGH,
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT:
HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,}
3. responses = model.generate_content(
contents=[nice_prompt],
generation_config=generation_config,
safety_settings=safety_config,
stream=True,)](https://image.slidesharecdn.com/exploringpromptengineering-241027124134-77d0c136/85/Exploring-prompt-engineering-in-depth-overview-44-320.jpg)



![[GEMINI EXTERNAL DECK] Introduction to Gemini.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/geminiexternaldeckintroductiontogemini-240507183804-614e2404-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 23] Ivan Petrovic - Approach to Architecting Generative AI Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/ivanpetrovic-approachtoarchitectinggenerativeaisolutions-231129100808-16df2918-thumbnail.jpg?width=640&height=640&fit=bounds)




![[GDSC-GNIOT] Google Cloud Study Jams Day 2- Cloud AI GenAI Overview.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/gdsc-gniotgooglecloudstudyjamsday2-cloudaigenaioverview-230914161034-01a51925-thumbnail.jpg?width=640&height=640&fit=bounds)





















![Cloud Study Jam[1st OCT] gdscgtbit.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/cloudstudyjam1stoct-231001163504-5ffe193b-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 24] Tomislav Tipuric - Exploring LLMs across clouds – A Year in t...](https://cdn.slidesharecdn.com/ss_thumbnails/tomislavtipuric-241220211229-91d80fe1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 24] Ewelina Kucal & Maciej Dziezyc - How to Encourage Children to...](https://cdn.slidesharecdn.com/ss_thumbnails/ewelinakucalmaciejdziezyc-worldreader-250217194551-28a1a23a-thumbnail.jpg?width=640&height=640&fit=bounds)






![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

















