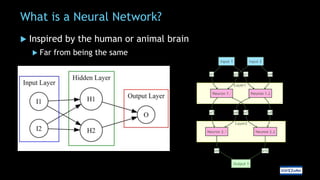
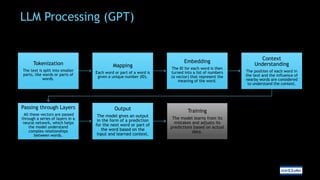
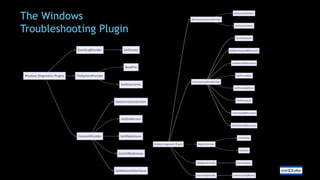
The document discusses the use of generative AI and large language models in software development, highlighting types of AI, neural networks, and the importance of fine-tuning models for specific tasks. It emphasizes prompt engineering for effective AI interactions and introduces the semantic kernel as a versatile tool for integrating AI into applications. Additionally, the document covers practical implementations, including developing ChatGPT plugins using C# and managing AI model parameters effectively.