Downloaded 218 times






![MTS-Dialog Dataset [1]
§ To avoid privacy infringement risks, we created simulated conversations from publicly available
de-identified clinical notes from the Mtsamples collection.
§ Eight trained annotators used the notes sections to write simulated conversations according to
guidelines derived from a study of a large private collection of real conversations and notes.
New Datasets
We created and released two new datasets free of PHI that can be used for benchmarking and research on
clinical note generation and accelerate research efforts on this understudied NLP task.
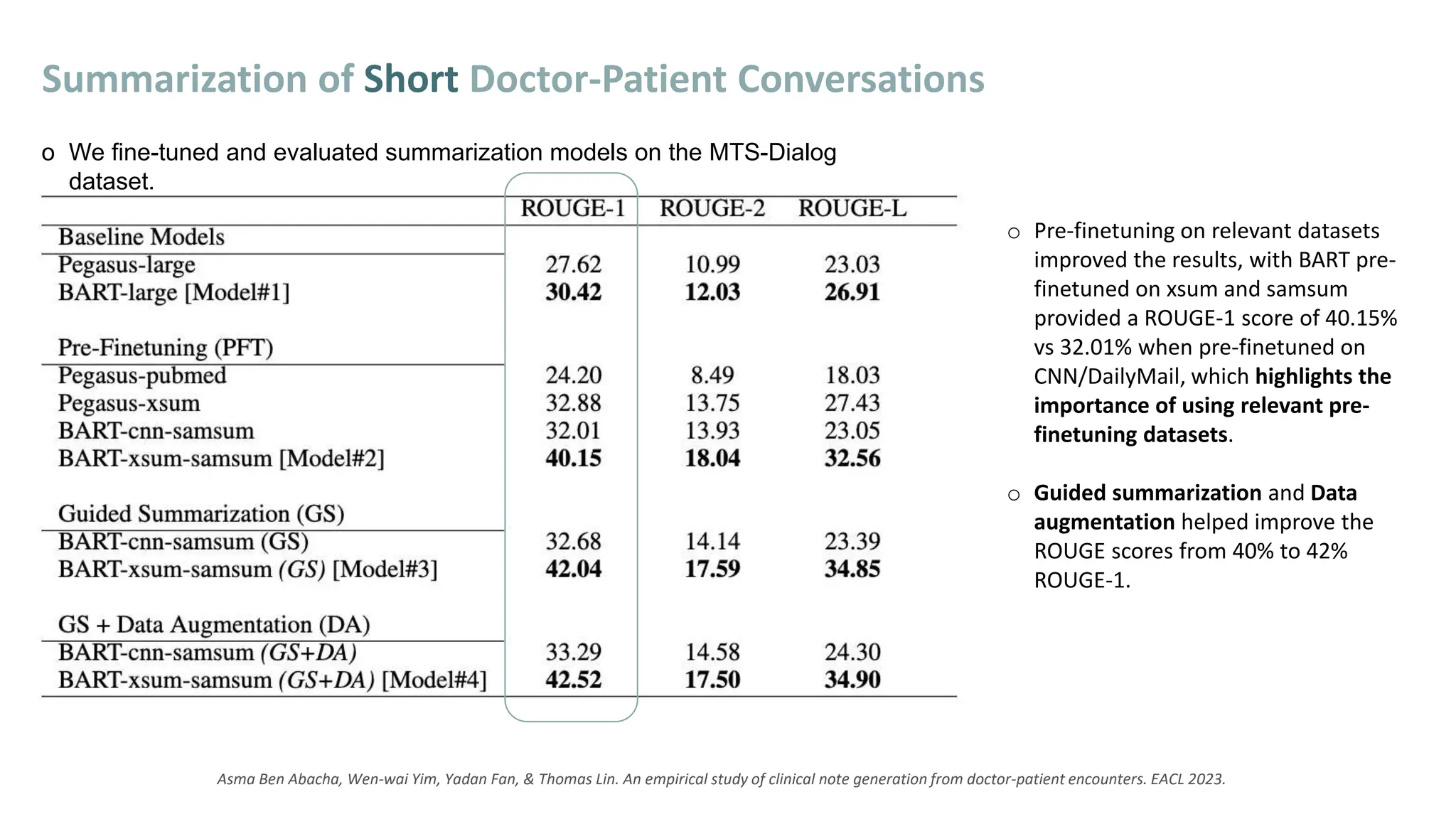
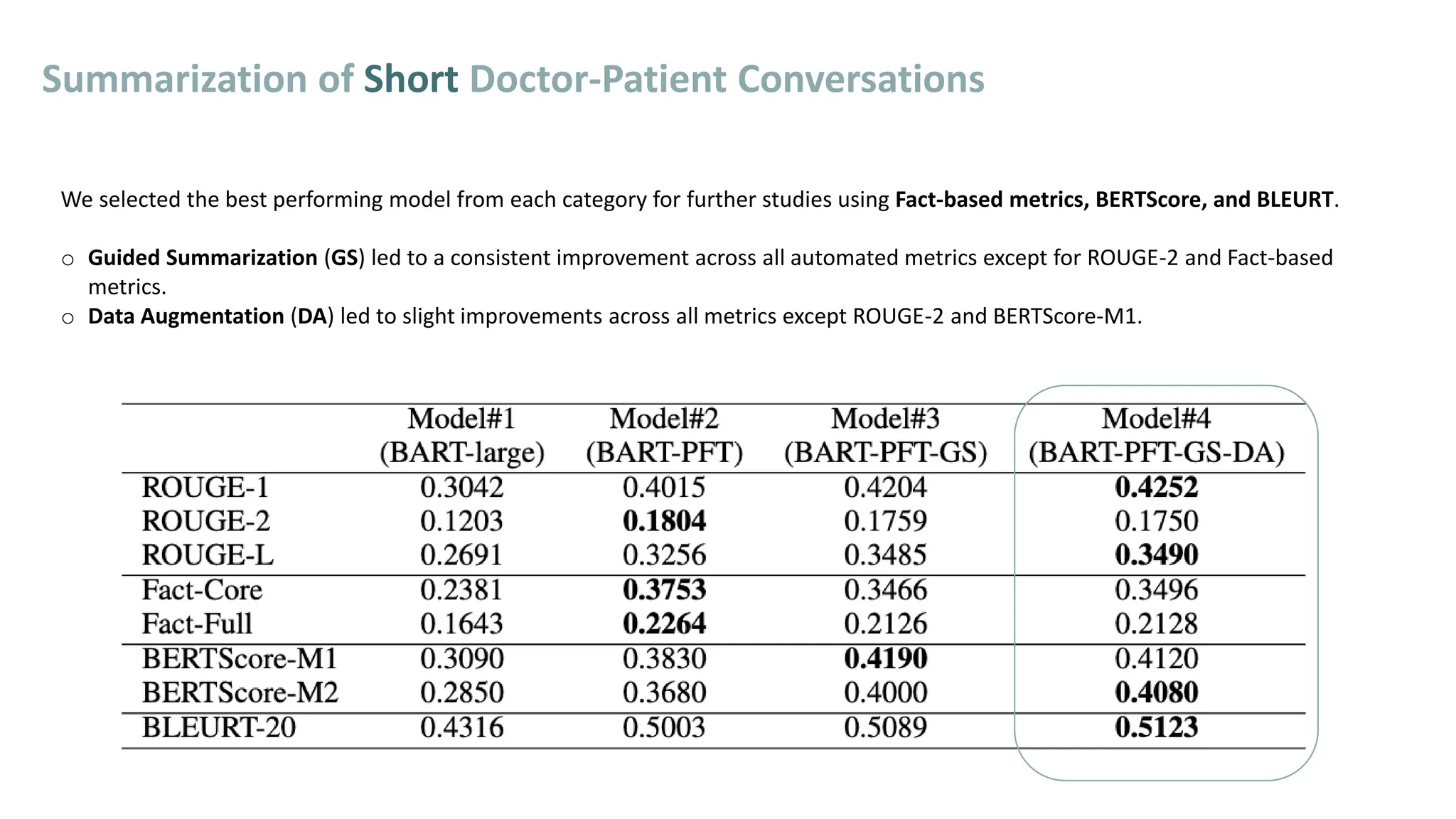
[1] Asma Ben Abacha, Wen-wai Yim, Yadan Fan, & Thomas Lin. An empirical study of clinical note generation from doctor-patient encounters. EACL 2023.
[2] Wen-wai Yim, Yujuan Fu, Asma Ben Abacha, Neal Snider, Thomas Lin, & Meliha Yetisgen. ACI-Bench: a novel ambient clinical intelligence dataset for
benchmarking automatic visit note generation. Nature Scientific Data 2023.
ACI-BENCH: Ambient Clinical Intelligence Benchmark [2]
§ Includes full clinical notes and associated conversations from simulated encounters.
§ Four annotators with medical backgrounds validated the dataset.](https://image.slidesharecdn.com/asmabenabacha-guestlecture-feb-29-2024-240301001039-beb9c4d5/75/Large-Language-Models-and-Applications-in-Healthcare-9-2048.jpg)

















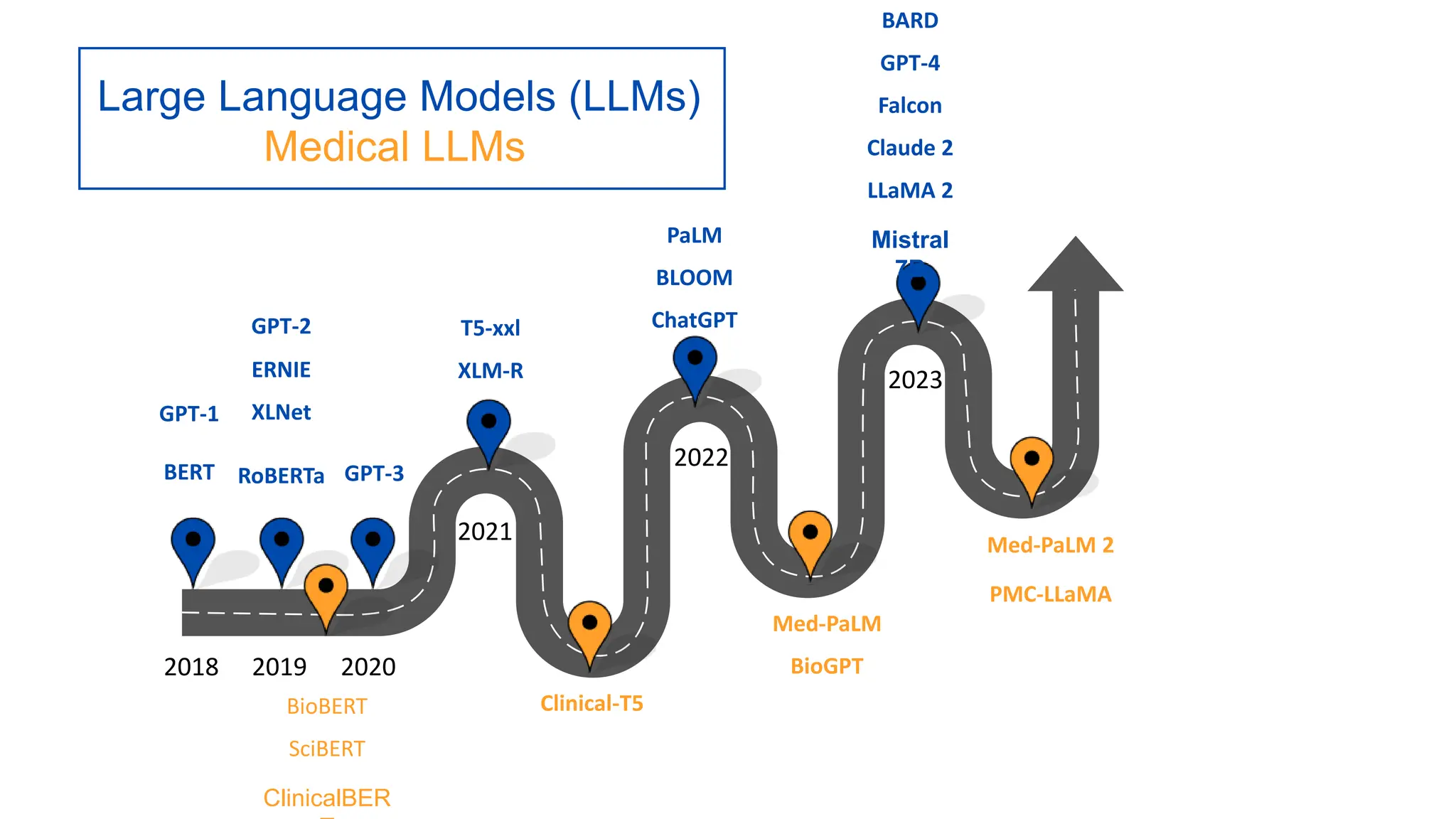
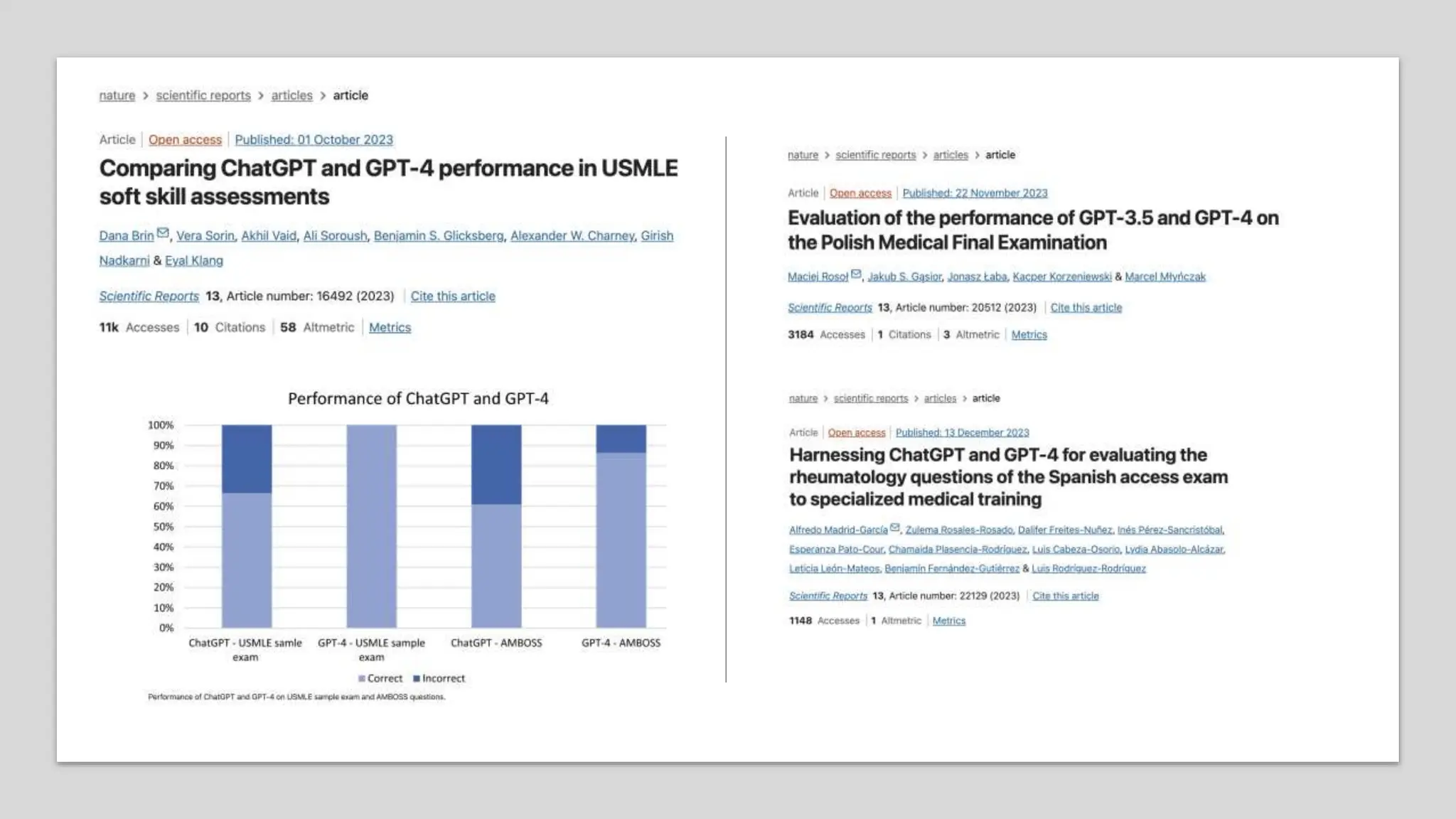
The lecture discusses the impact of large language models (LLMs) on healthcare, particularly in automating clinical note generation and detecting medical errors. It outlines how LLMs can alleviate the documentation burden on physicians, improving efficiency and reducing burnout, and highlights the creation of new datasets for benchmarking these tasks. Additionally, it emphasizes the importance of proper evaluation metrics and methodologies for ensuring accurate and safe application of LLMs in clinical settings.






























![[DSC Europe 24] Ivan Lorencin How LLMs are transforming modern medicine.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dsceurope24ivanlorencinhowllmsaretransformingmodernmedicine-241210182036-8a43ab21-thumbnail.jpg?width=640&height=640&fit=bounds)
































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

