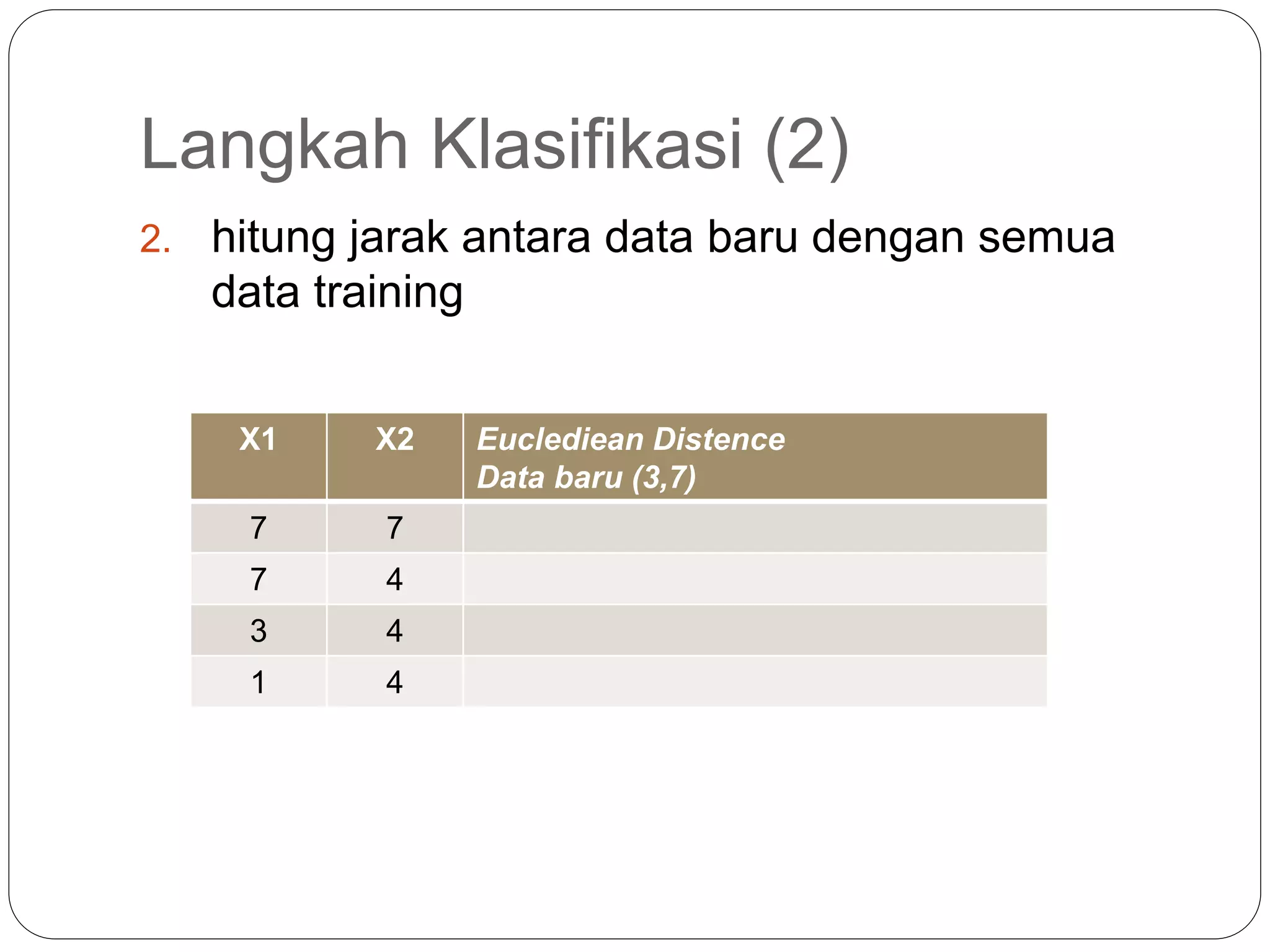
Algoritma K-nearest neighbor (KNN) adalah metode supervised learning dimana kelas suatu data baru ditentukan berdasarkan kelas mayoritas dari K tetangga terdekatnya. KNN mengklasifikasikan data baru berdasarkan atribut dan data pelatihan dengan menghitung jarak antara data baru dengan data pelatihan lalu menentukan K tetangga terdekat. Kelas prediksi data baru ditentukan dari kelas mayoritas K tetangga terdekat tersebut.