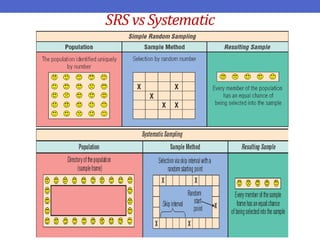
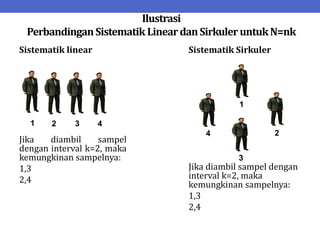
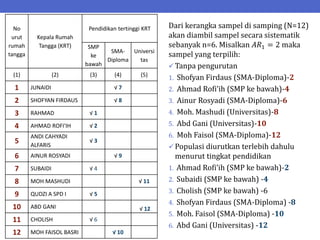
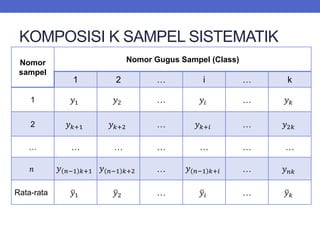
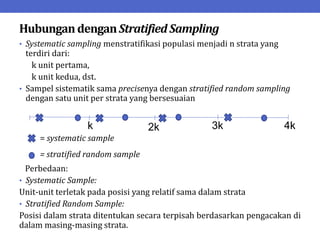
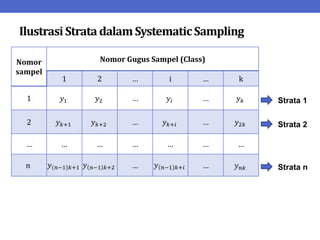
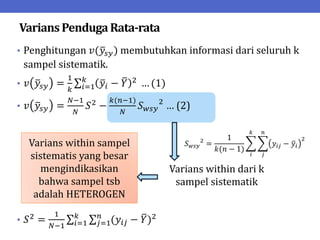
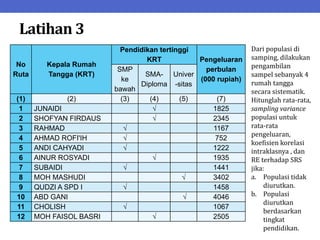
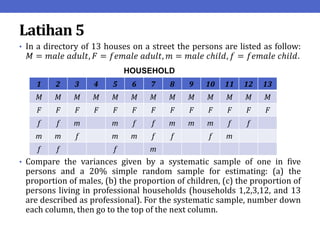
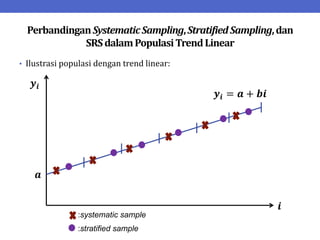
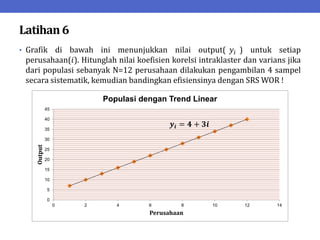
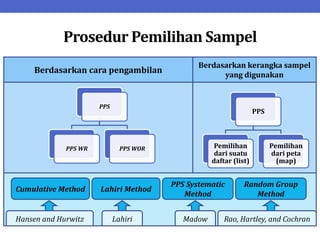
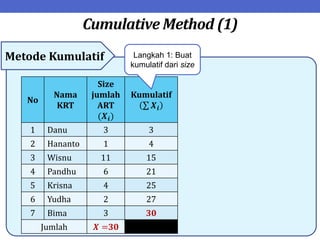
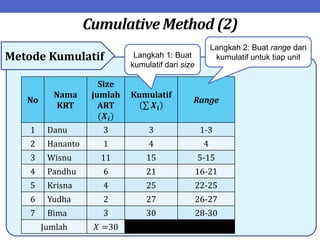
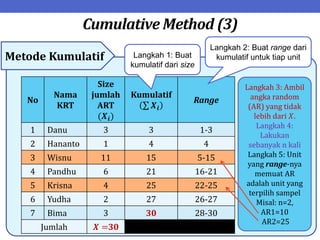
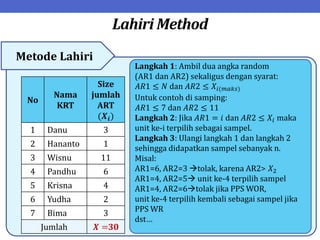
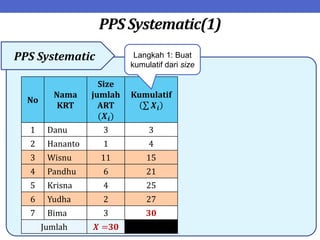
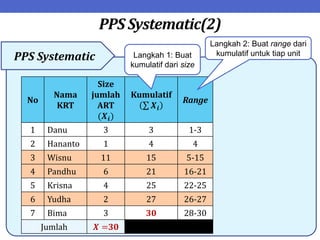
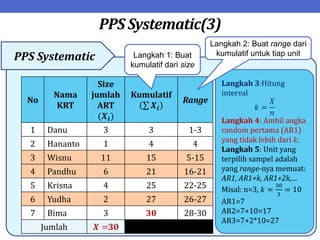
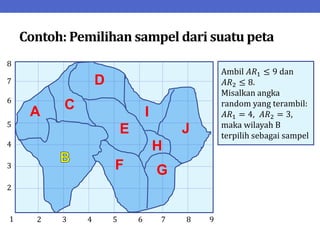
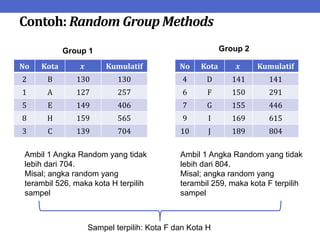
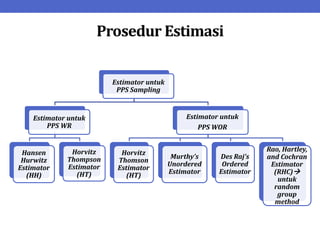
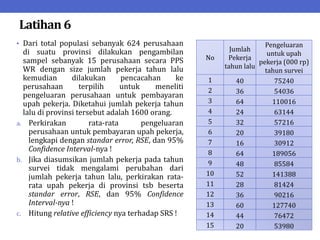
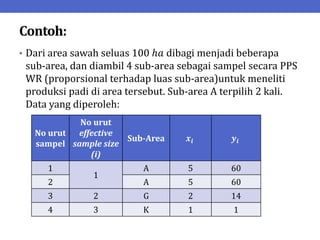
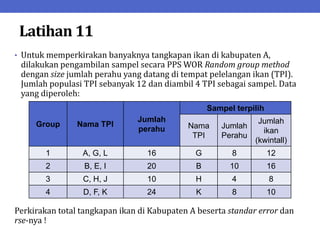
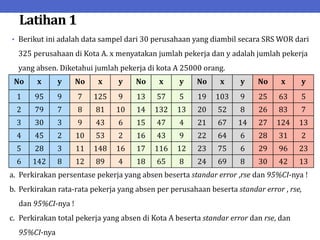
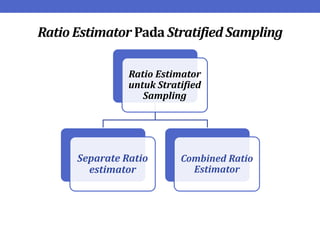
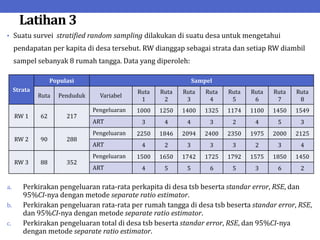
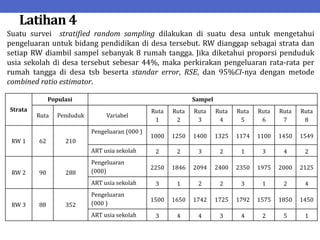
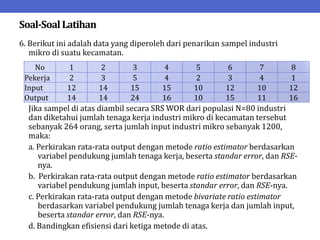
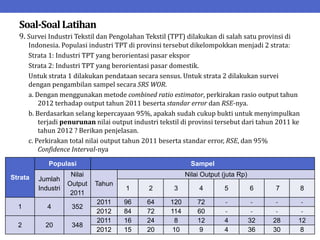
Dokumen ini menjelaskan tentang teknik penarikan sampel sistematik dalam penelitian yang memanfaatkan angka random untuk memilih unit pertama, kemudian mengikuti interval tertentu untuk unit berikutnya. Terdapat dua metode utama, yaitu linear dan circular systematic sampling, masing-masing dengan cara menghitung interval dan mengambil angka random dari tabel. Selain itu, dokumen ini juga membahas masalah yang mungkin muncul dengan interval dan konsep pengaturan unit untuk meningkatkan efisiensi sampling.