Downloaded 12 times



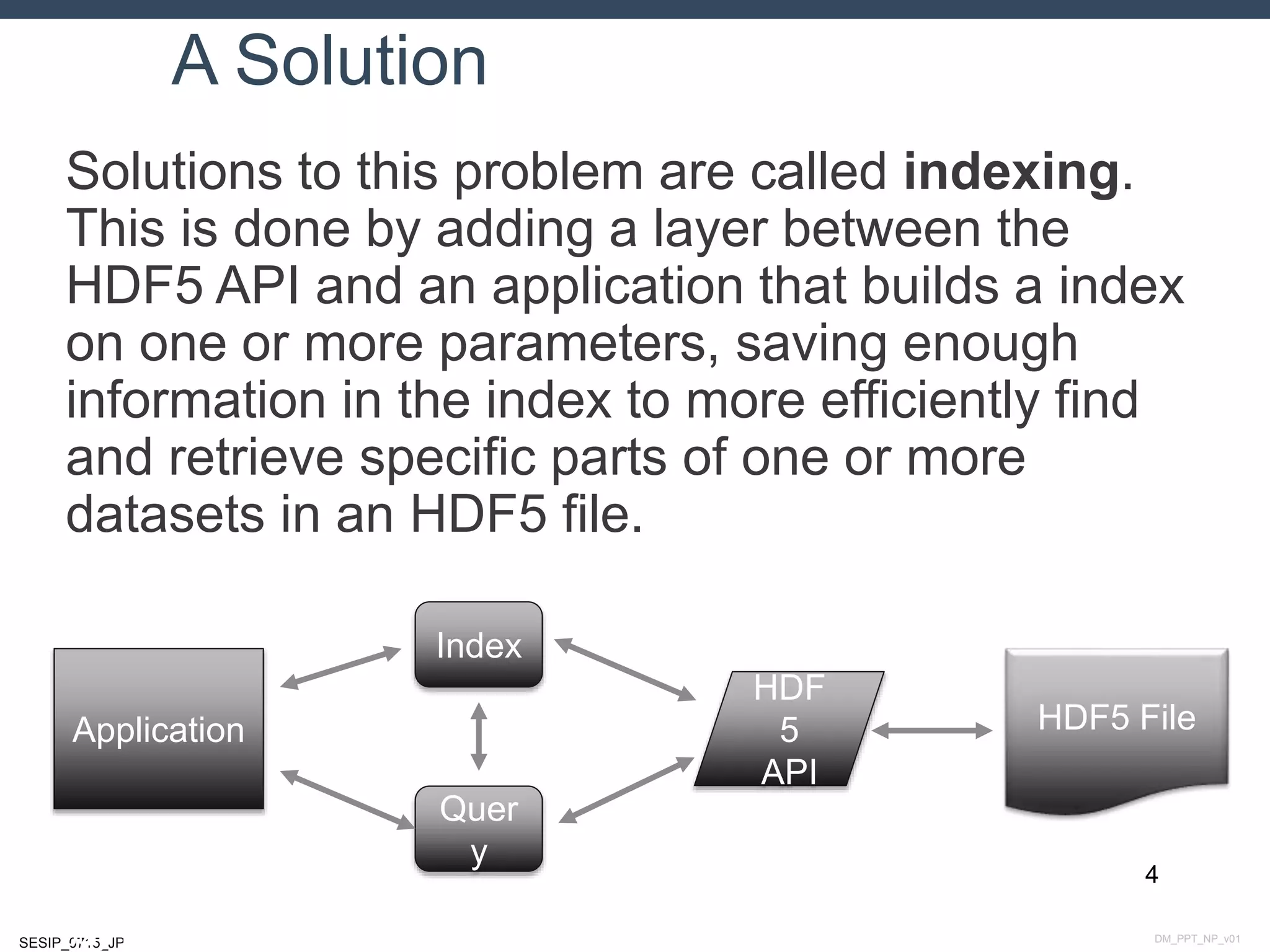















The document discusses indexing methods for HDF5 files to enable efficient searching and access of data based on data values. It describes several existing implementations of HDF5 indexing, including PyTables, FastQuery/FastBit, Alacrity, and prototypes from The HDF Group. It also outlines current and future work to develop indexing and querying capabilities within HDF5 to allow complex multi-dimensional searches across metadata and datasets.










































































