Downloaded 16 times







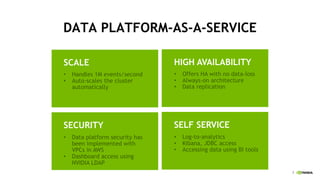
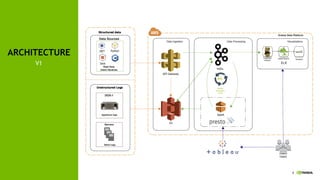
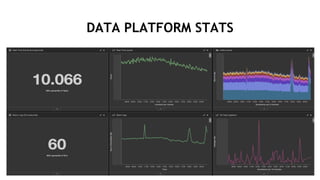

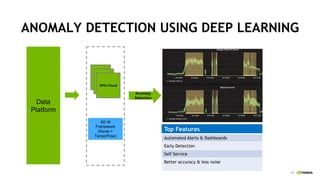
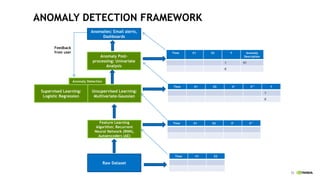
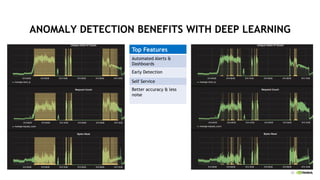
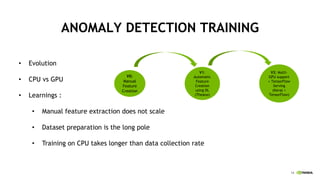
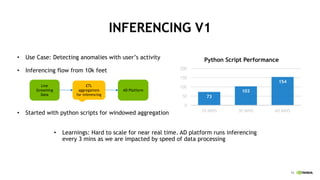


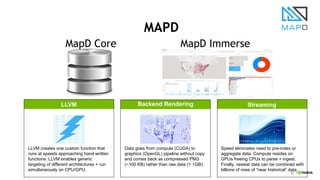
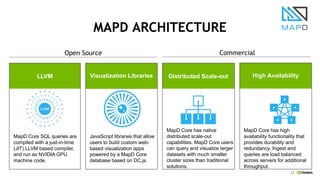

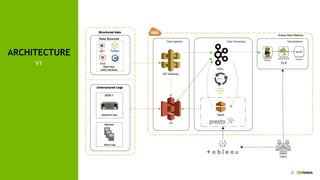
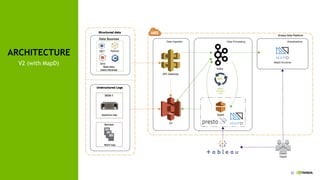



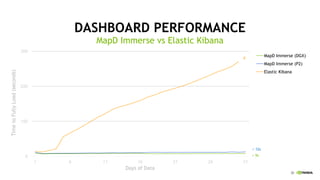
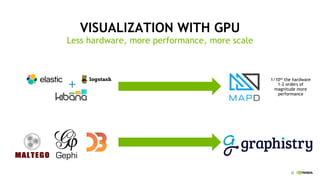
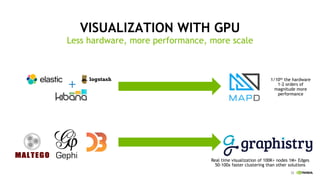

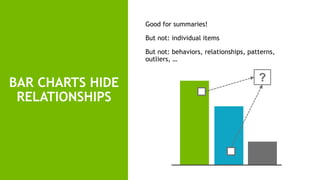

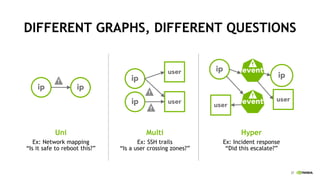
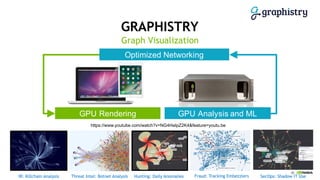

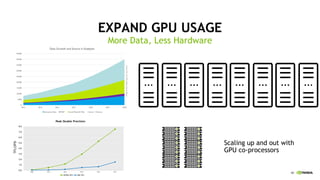
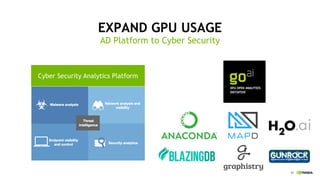
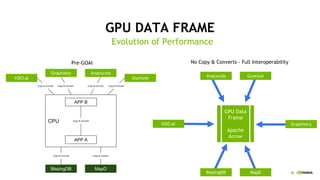
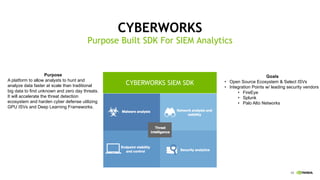

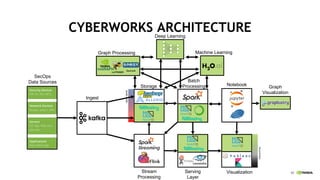
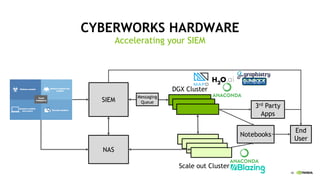
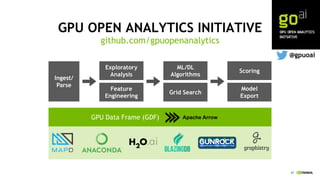

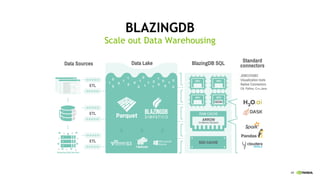
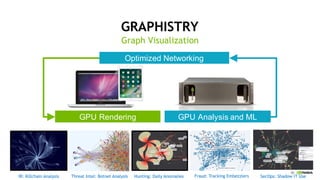







This document discusses accelerating cyber threat detection with GPUs. It begins by noting that current detection methods are too slow, taking an average of 98 days for financial services and up to 7 months for retailers. It then discusses how attacks are becoming more sophisticated and provides examples. The document outlines principles for cybersecurity, including improving indication of compromise through combining machine learning, graph analysis, and other methods. It discusses building an anomaly detection platform using deep learning and GPUs for improved performance. It also covers using GPU databases and visualization to further accelerate analytics and hunting of threats.











































![[DSC Croatia 22] Building smarter ML and AI models and making them more accur...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingsmartermlandaimodelsandmakingthemmoreaccurate-auniqueandacceleratedapproachfordecisionsuppor-220608090138-b107b477-thumbnail.jpg?width=640&height=640&fit=bounds)





















