This document proposes a melody extraction method using multi-column deep neural networks (MCDNNs). The key points are:
1. An MCDNN architecture is used to classify frames into multiple pitch resolutions (e.g. 1 semitone, 0.5 semitone) for improved accuracy and resolution.
2. Data augmentation by pitch shifting and a singing voice detector are used to increase training data.
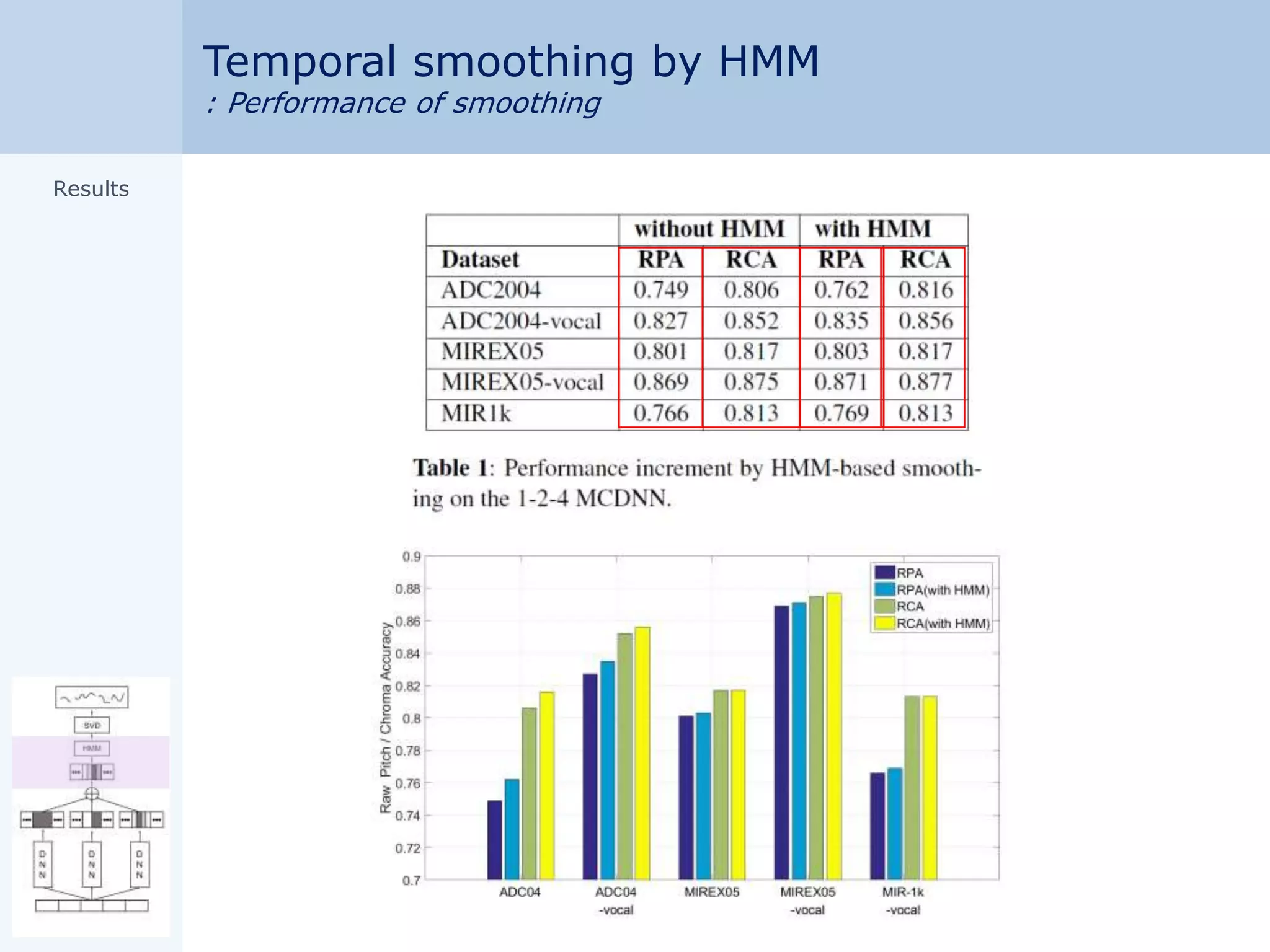
3. Hidden Markov models provide temporal smoothing of MCDNN outputs.
4. Evaluation on various datasets shows the MCDNN approach outperforms state-of-the-art methods for melody extraction.

![Melody extraction
: from polyphonic music
Definition:
Automatically obtain the f0 curve of the predominant melodic line drawn from multiple sources [1]
[1] Bittner, R. M., Salamon, J., Essid, S., & Bello, J. P. Melody extraction by contour classification. In Proc. ISMIR (pp. 500-506).
<An example of melody extraction, Beyonce - ‘Halo’>](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-2-2048.jpg)
![Melody extraction algorithms
[2] Salamon, Justin, et al. "Melody extraction from polyphonic music signals: Approaches, applications, and challenges." Signal Processing Magazine,
IEEE31.2 (2014): 118-134.
Salience based
approaches
Source separation
based approaches
Data driven
based approaches](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-3-2048.jpg)
![<posteriorgram [3] >
Support vector machine note
classifier
Pitch labels : 60 MIDI notes (G2~F#7)
Resolution = 1 semitone
Losing detailed information about
singing styles
ex) vibrato, transition patterns
[3] Ellis, Daniel PW, and Graham E. Poliner. "Classification-based melody transcription." Machine Learning 65.2 (2006)
Melody extraction algorithms
: Data-driven based approaches
Data Posteriorgram
Support
Vector
Machine
G2~ F#7
60 MIDI
scale
HMM](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-4-2048.jpg)





![<Fig. (b) Classification accuracyon the validation set>
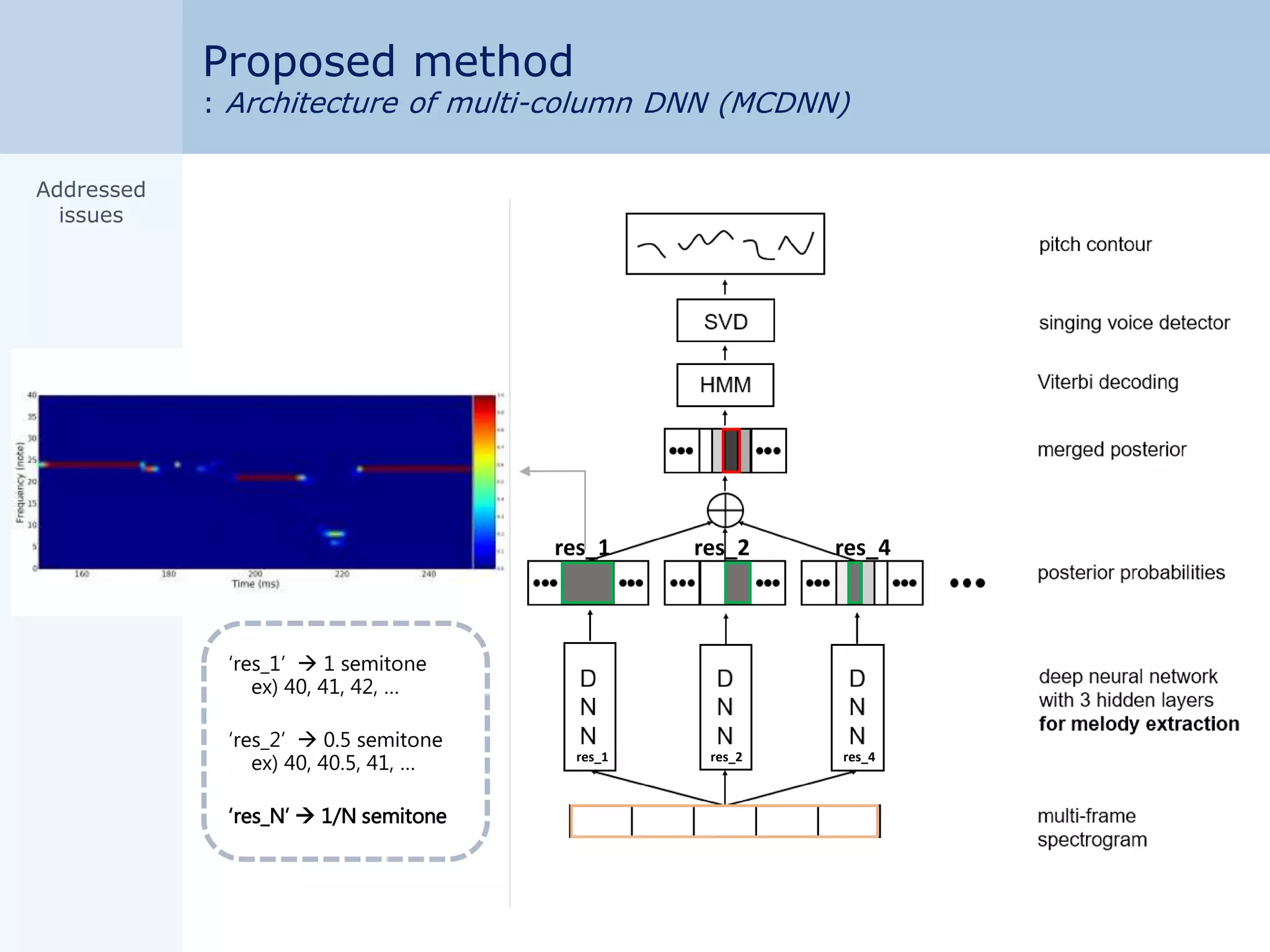
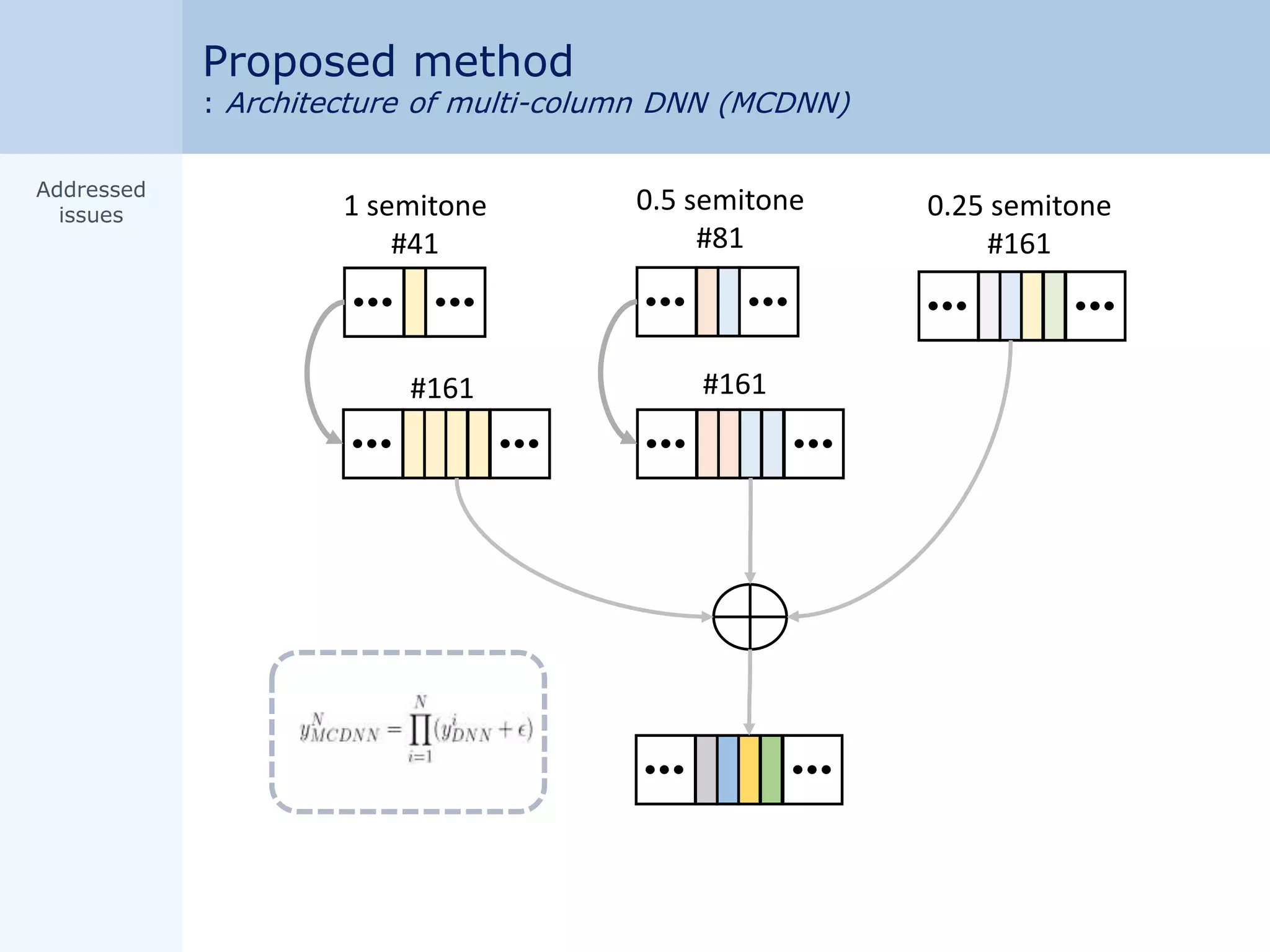
Motivation
: Classification accuracy & pitch resolution
res_1 res_2 res_4
high pitch
resolution
high
classification
accuracy
<Fig. (a) Multi-column DNN>
D
N
N
D
N
N
D
N
N
res_1 res_2 res_4
Addressed
issues
[4] Ciregan, Dan, Ueli Meier, and Jürgen Schmidhuber. "Multi-column deep neural networks for image classification." Computer Vision and Pattern Recognition (CVPR), 2012.
[5] Agostinelli, Forest, Michael R. Anderson, and Honglak Lee. "Adaptive multi-column deep neural networks with application to robust image denoising." Advances in Neural
Information Processing Systems. 2013.](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-10-2048.jpg)
![Motivation
: Multi-column DNN
[4] Ciregan, Dan, Ueli Meier, and Jürgen Schmidhuber. "Multi-column deep neural networks for image classification." Computer Vision and Pattern Recognition
(CVPR), 2012.
[5] Agostinelli, Forest, Michael R. Anderson, and Honglak Lee. "Adaptive multi-column deep neural networks with application to robust image denoising."
Advances in Neural Information Processing Systems. 2013.
Addressed
issues](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-11-2048.jpg)

![Training Datasets
RWC Database [6]
American, Japanese pop music
100 songs
: Training set (85 songs)
: Validation set (15 songs)
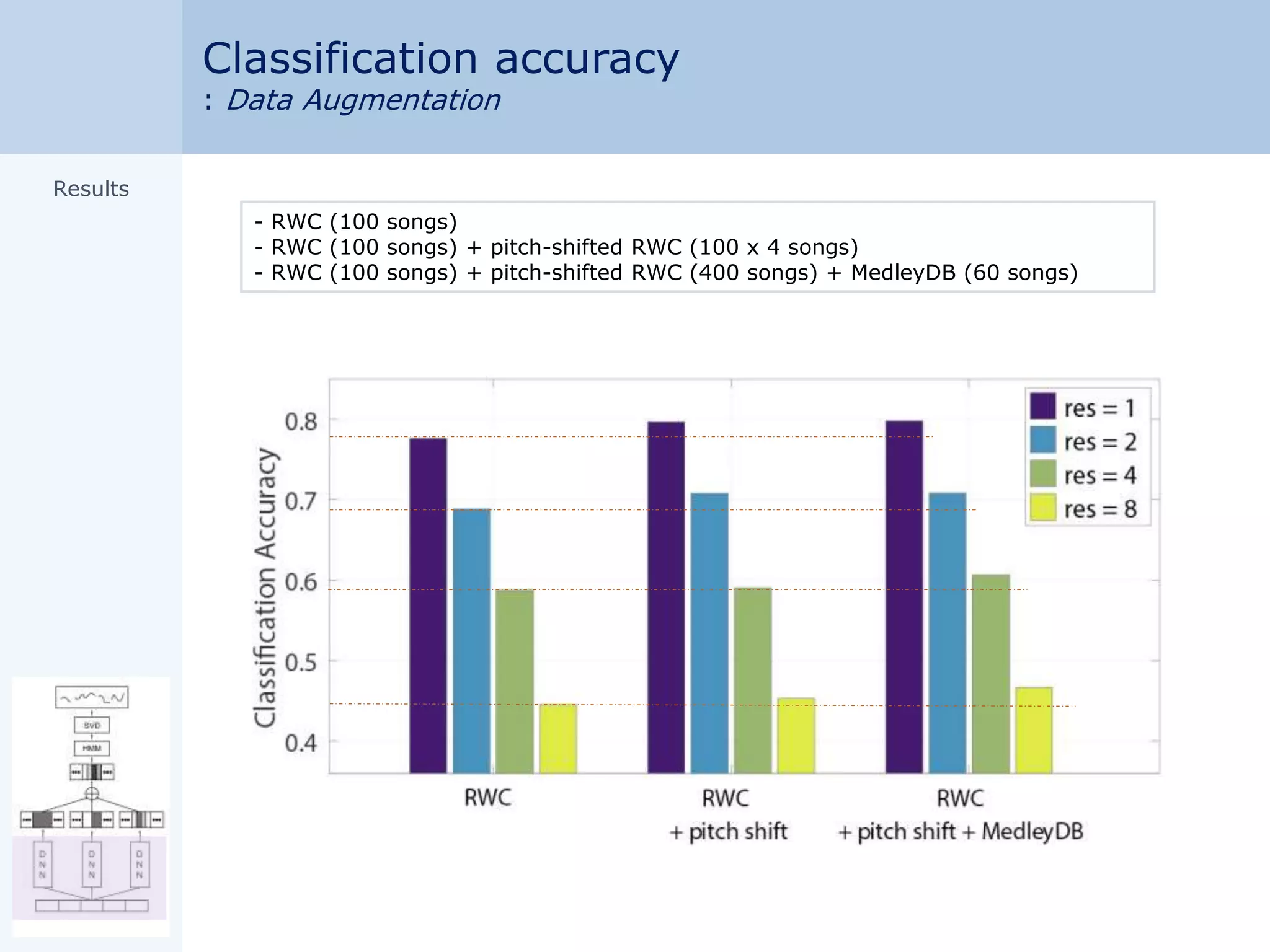
Data augmentation
Pitch-shifted songs
(±1, 2 𝑠𝑒𝑚𝑖𝑡𝑜𝑛𝑒)
: 100 500 songs
RWC
(100 songs)
RWC
+1
semitone
RWC
-1
semitone
RWC
+2
semitone
RWC
-2
semitone
Data augmentation
[6] Goto, Masataka, et al. "RWC Music Database: Popular, Classical and Jazz Music Databases." ISMIR. Vol. 2. 2002.
[7] Bittner, Rachel M., et al. "MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research." ISMIR. 2014.
MelodyMCDNNTest
Data
Training
Data
Addressed
issues](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-15-2048.jpg)
![Training Datasets
RWC Database [6]
American, Japanese pop music
100 songs
: Training set (85 songs)
: Validation set (15 songs)
Data augmentation
Pitch-shifted songs
(±1, 2 𝑠𝑒𝑚𝑖𝑡𝑜𝑛𝑒)
: 100 500 songs
MedleyDB [7]
Total : 122 songs
60 vocal songs
Genre :
Singer/Songwriter, Classical, Rock,
Folk, Pop, Musical Theatre
RWC
(100 songs)
MedleyDB
(60 songs)
RWC
+1
semitone
RWC
-1
semitone
RWC
+2
semitone
RWC
-2
semitone
Data augmentation
[4] Goto, Masataka, et al. "RWC Music Database: Popular, Classical and Jazz Music Databases." ISMIR. Vol. 2. 2002.
[5] Bittner, Rachel M., et al. "MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research." ISMIR. 2014.
MelodyMCDNNTest
Data
Training
Data
Addressed
issues](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-16-2048.jpg)

![Temporal smoothing by HMM
: Viterbi decoding
Bayes' theorem
Viterbi decoding
transition
priorposterior
Addressed
issues
[3] Ellis, Daniel PW, and Graham E. Poliner. "Classification-based melody transcription." Machine Learning 65.2 (2006)](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-18-2048.jpg)





![ ADC2004 [8]
• 12 songs
• Rock, R&B, Pop, Jazz, Opera
MIREX05 [9]
• Total 25 songs
• 13 songs
( 9 vocal songs + 4 instrument songs)
MIR1k [10]
• 1000 vocal songs
[8,9] http://labrosa.ee.columbia.edu/projects/melody
[10] https://sites.google.com/site/unvoicedsoundseparation/mir-1k
MelodyMCDNNTest
Data
Training
Data
Evaluation
: Test Datasets
Evaluation](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-26-2048.jpg)


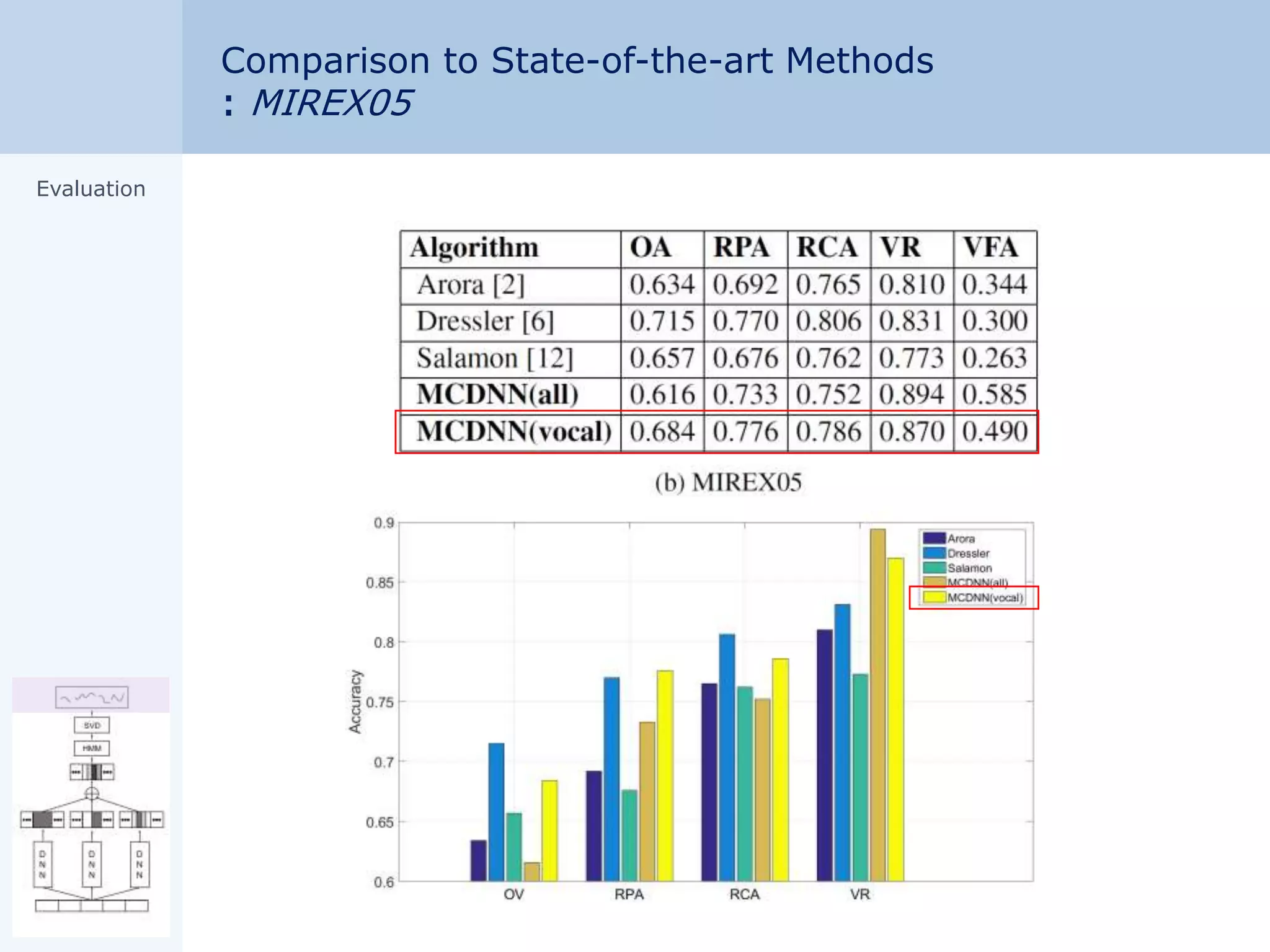




![Appendix
Resample : 8 kHz
Merge stereo channel into mono.
STFT :
• FFT size : 1024 (1 bin = 7.81Hz)
• Window size = 1024 (Hann)
• Hop size : 80 (1 frame = 10ms)
• Compressing the magnitude by a log
scale
• Using 256 bins
(0 ~ 2000Hz : vocal range)
Multi-frame
• 11 frame spectrogram / example
[] Ellis, Daniel PW, and Graham E. Poliner. "Classification-based melody transcription." Machine Learning 65.2 (2006): 439-456.
Pre-processing
voice frame](https://image.slidesharecdn.com/ismir16melodyextraction-160820083925/75/ISMIR-2016_Melody-Extraction-34-2048.jpg)


















































