Downloaded 89 times


![©2017 Discover Financial Services - Confidential and Proprietary - Do not copy or distribute
Ingesting complex data - How complex?
Format of files will vary, some are easy to consume, others hard
Example: Records with Dynamic arrays/vectors of primitives or strings
Schema: First Name, Last Name, Array_size of Sibling_Name[], Sibling_Name[0-N], City
Data:
John, Doe, 2, Susie, Chris, Chicago
Mary, Johnston, 3, Ashley, Tom, Mike, Atlanta
Frank, Smith, 1, Ralph, Toronto
Example: Records with an array of Struct data types
Schema: First Name, Array_size of CompanyStruct[], CompanyStruct.Name, CompanyStruct.City,
CompanyStruct.YearsWorked, Age
Data:
John, 1, Discover, Chicago, 3 , 44
Mary, 3, Sales Unlimited, Dallas, 2, Auditors R’ Us, Atlanta, 5, Discover, Chicago 4, 35
10](https://image.slidesharecdn.com/santoshbardwajcontinuousdataingestionpipelinefortheenterprise-170621184658/85/Continuous-Data-Ingestion-pipeline-for-the-Enterprise-10-320.jpg)
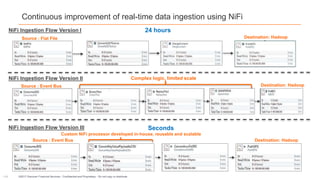



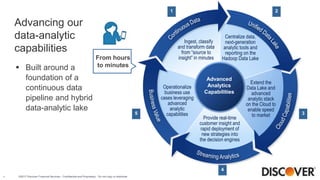
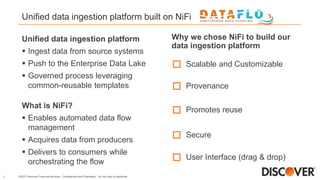
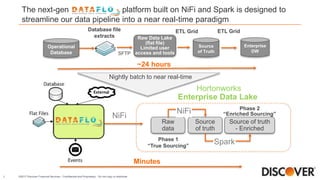
The document presents Discover Financial Services' next-gen data ingestion platform built on NiFi, discussing its capabilities, challenges faced during development, and future enhancements. The platform enables rapid data ingestion and real-time analytics, streamlining operations from hours to minutes through scalable and customizable processes. It emphasizes the integration of advanced analytics and cloud capabilities to enhance data integration and operational efficiencies.


![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)



















































































