Downloaded 5,466 times





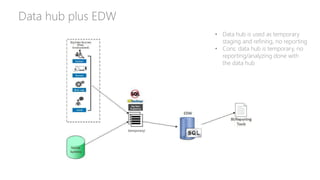








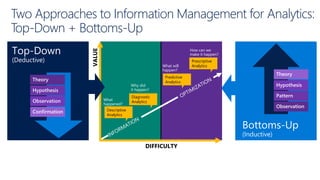


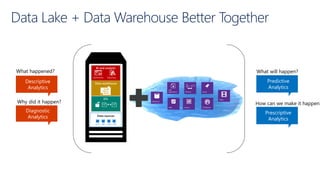



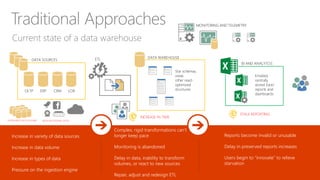











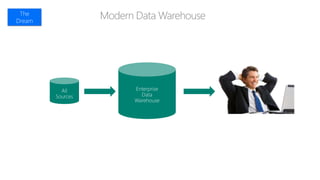
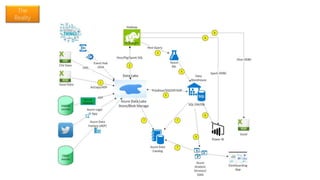
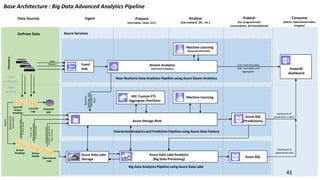











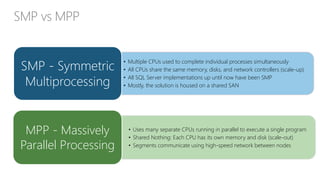
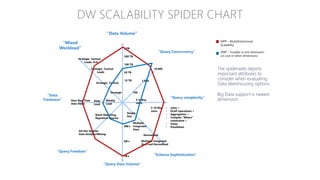





The document provides an overview of big data architectures and the data lake concept. It discusses why organizations are adopting data lakes to handle increasing data volumes and varieties. The key aspects covered include: - Defining top-down and bottom-up approaches to data management - Explaining what a data lake is and how Hadoop can function as the data lake - Describing how a modern data warehouse combines features of a traditional data warehouse and data lake - Discussing how federated querying allows data to be accessed across multiple sources - Highlighting benefits of implementing big data solutions in the cloud - Comparing shared-nothing, massively parallel processing (MPP) architectures to symmetric multi-processing (




































































































