Download as PDF, PPTX




















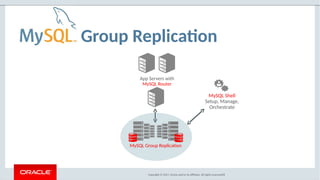
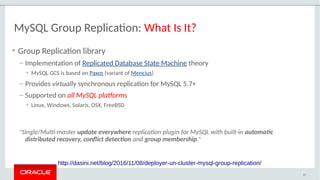


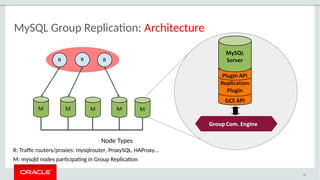
![MySQL Group Replication: What Sets It Apart?
• Built by the MySQL Engineering Team
– Natively integrated into Server: InnoDB, Replication, GTIDs, Performance Schema, SYS
– Built-in, no need for separate downloads
– Available on all platforms [Linux, Windows, Solaris, FreeBSD, etc]
• Better performance than similar offerings
– MySQL GCS has optimized network protocol that reduces the impact on latency
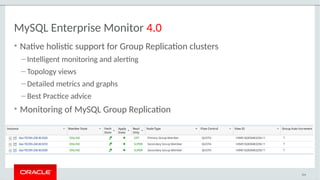
• Easier monitoring
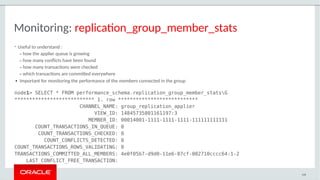
– Simple Performance Schema tables for group and node status/stats
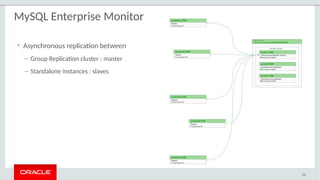
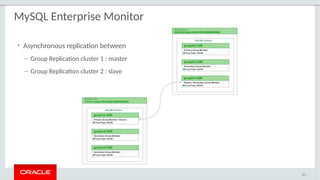
– Native support for Group Replication in MySQL Enterprise Monitor
• Modern full stack MySQL HA being built around it
44](https://image.slidesharecdn.com/mysqlinnodbcluster201801-180328095452/85/MySQL-5-7-InnoDB-Cluster-Jan-2018-37-320.jpg)
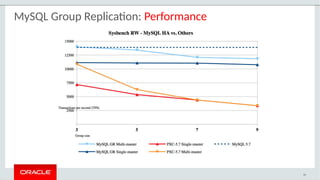
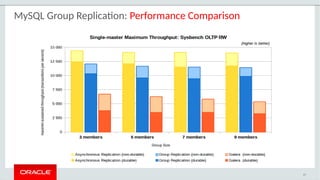
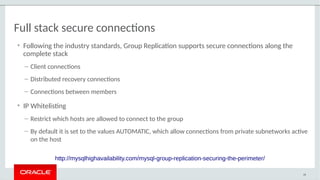

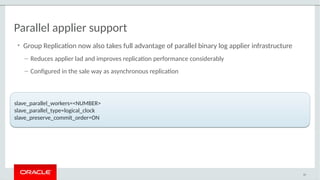
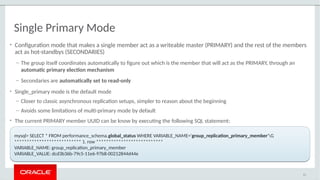


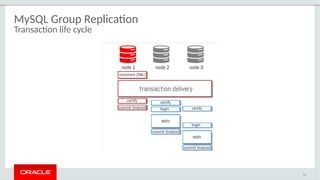
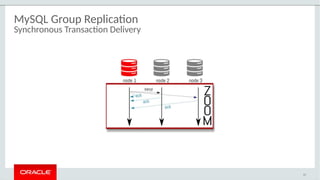
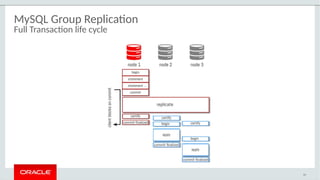
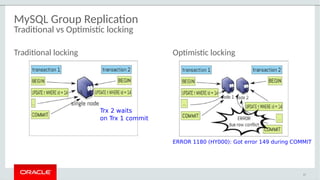

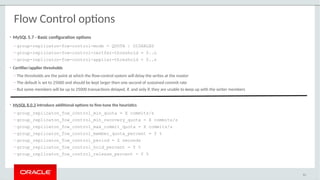


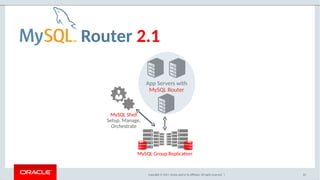

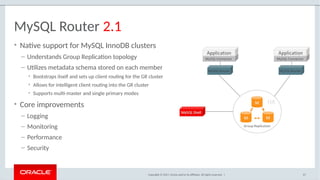
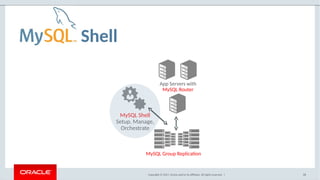


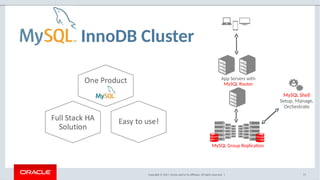



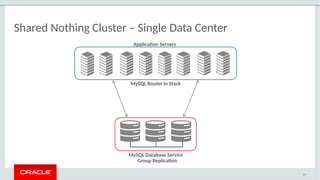
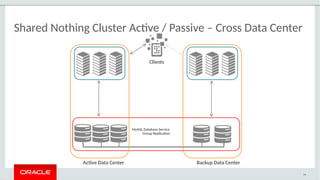
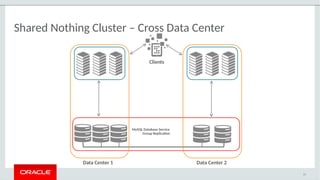
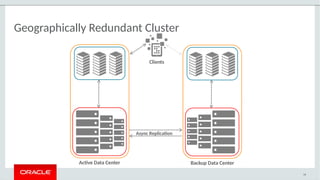
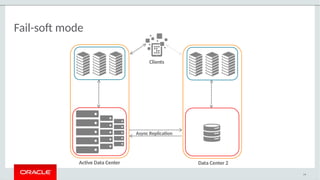
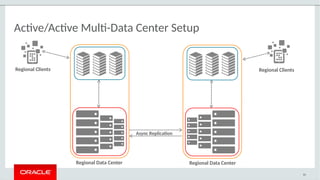


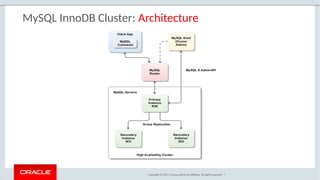
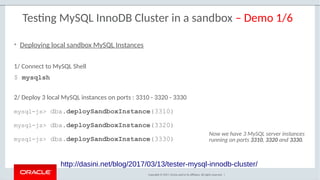



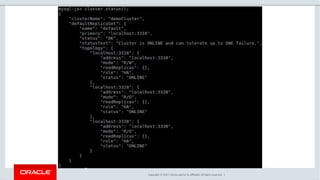

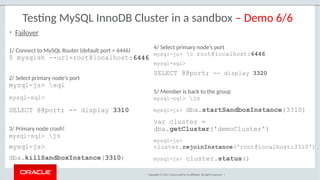


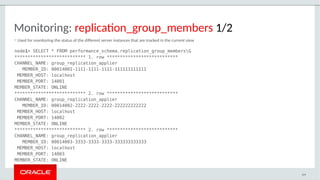
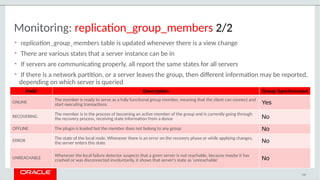
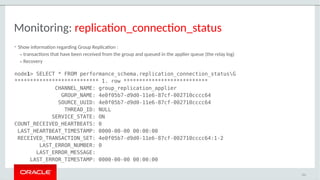





The document provides a comprehensive overview of MySQL's high availability solutions, particularly focusing on MySQL InnoDB Cluster and Group Replication as key architectures for ensuring uninterrupted service. It details the importance of redundancy across hardware, software, and data to minimize downtime, alongside various replication modes and considerations. Additionally, it emphasizes MySQL's capabilities in supporting a wide array of applications through its robust replication and clustering features.























































































