Downloaded 10 times





















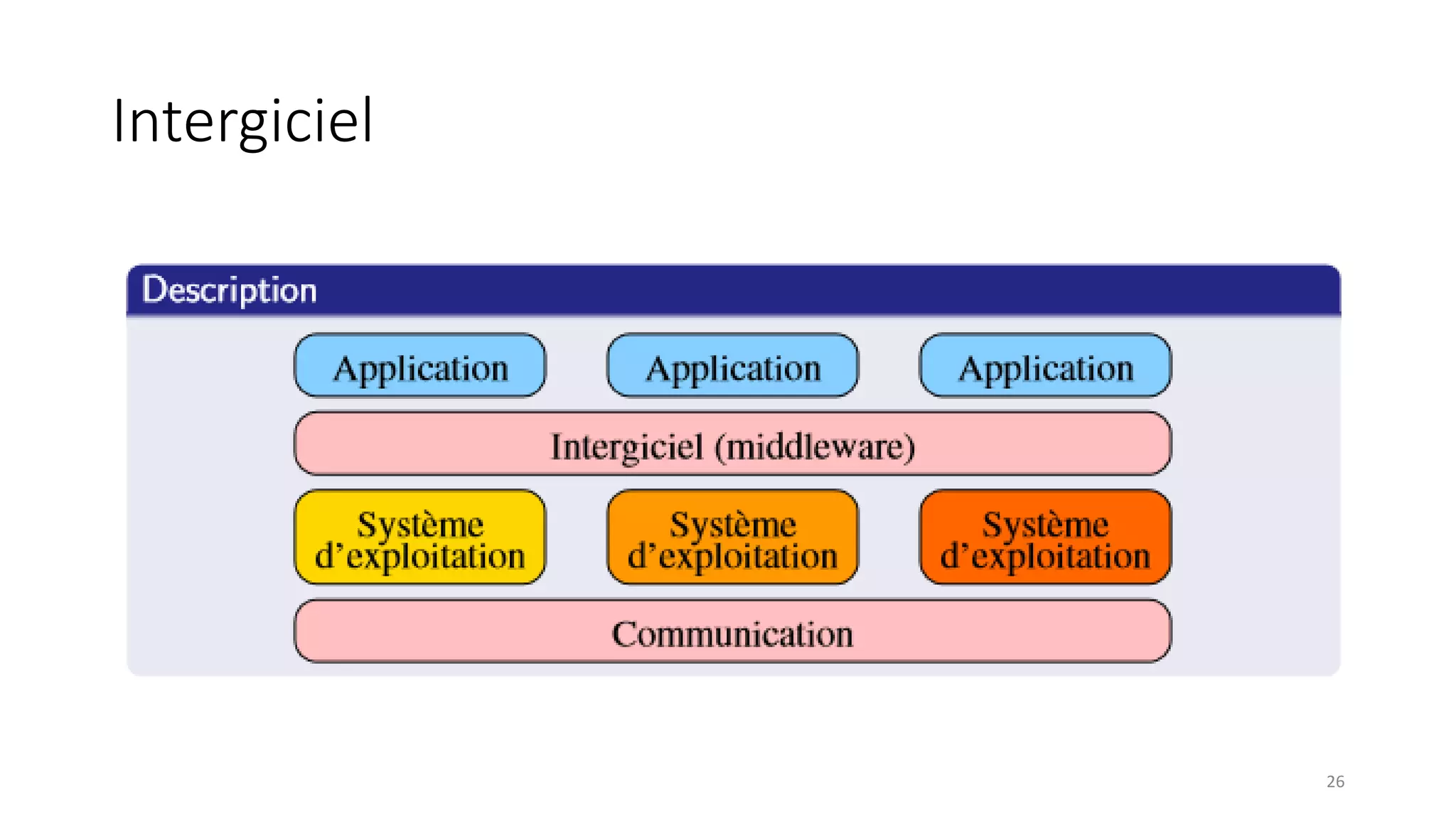
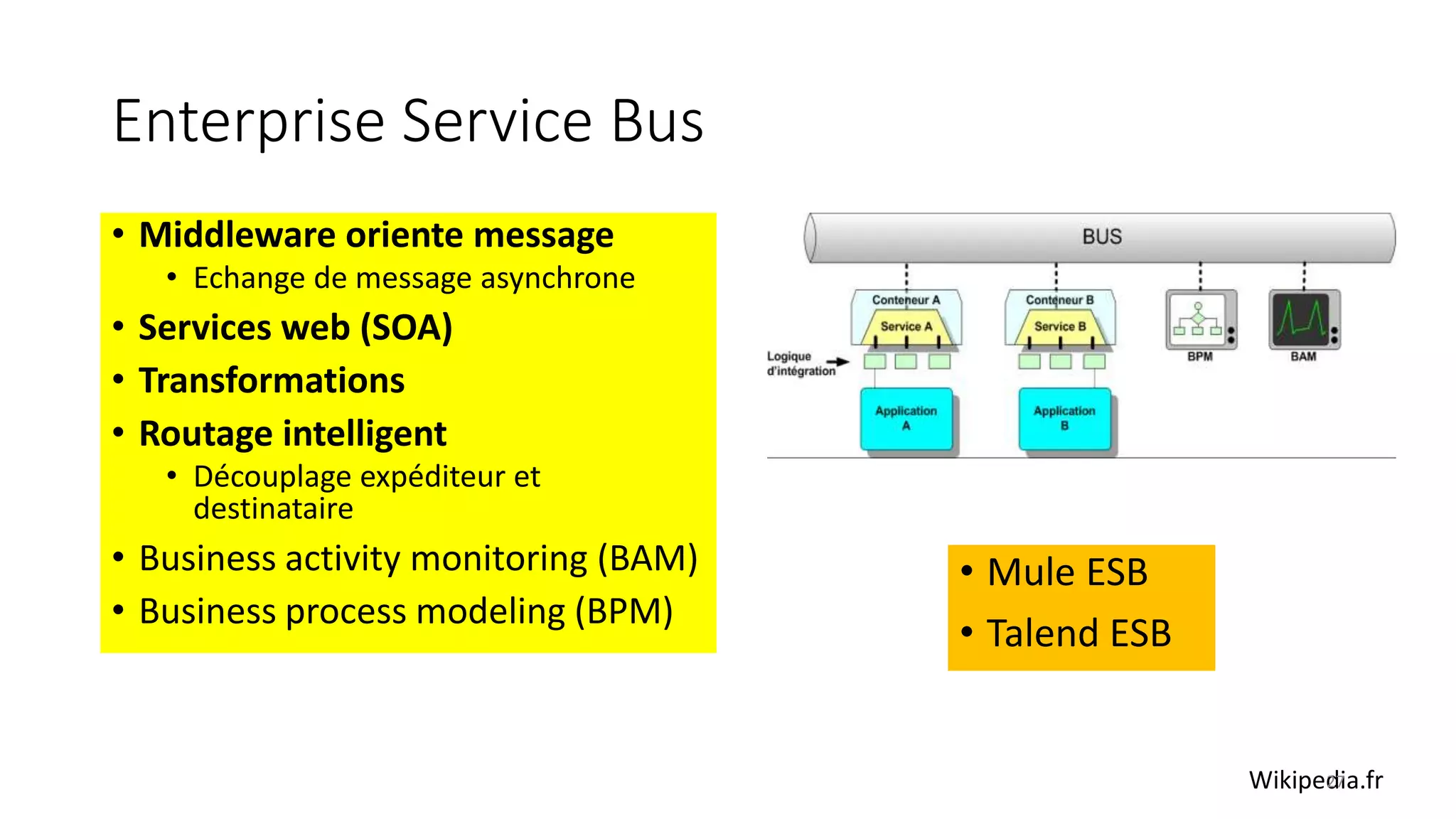
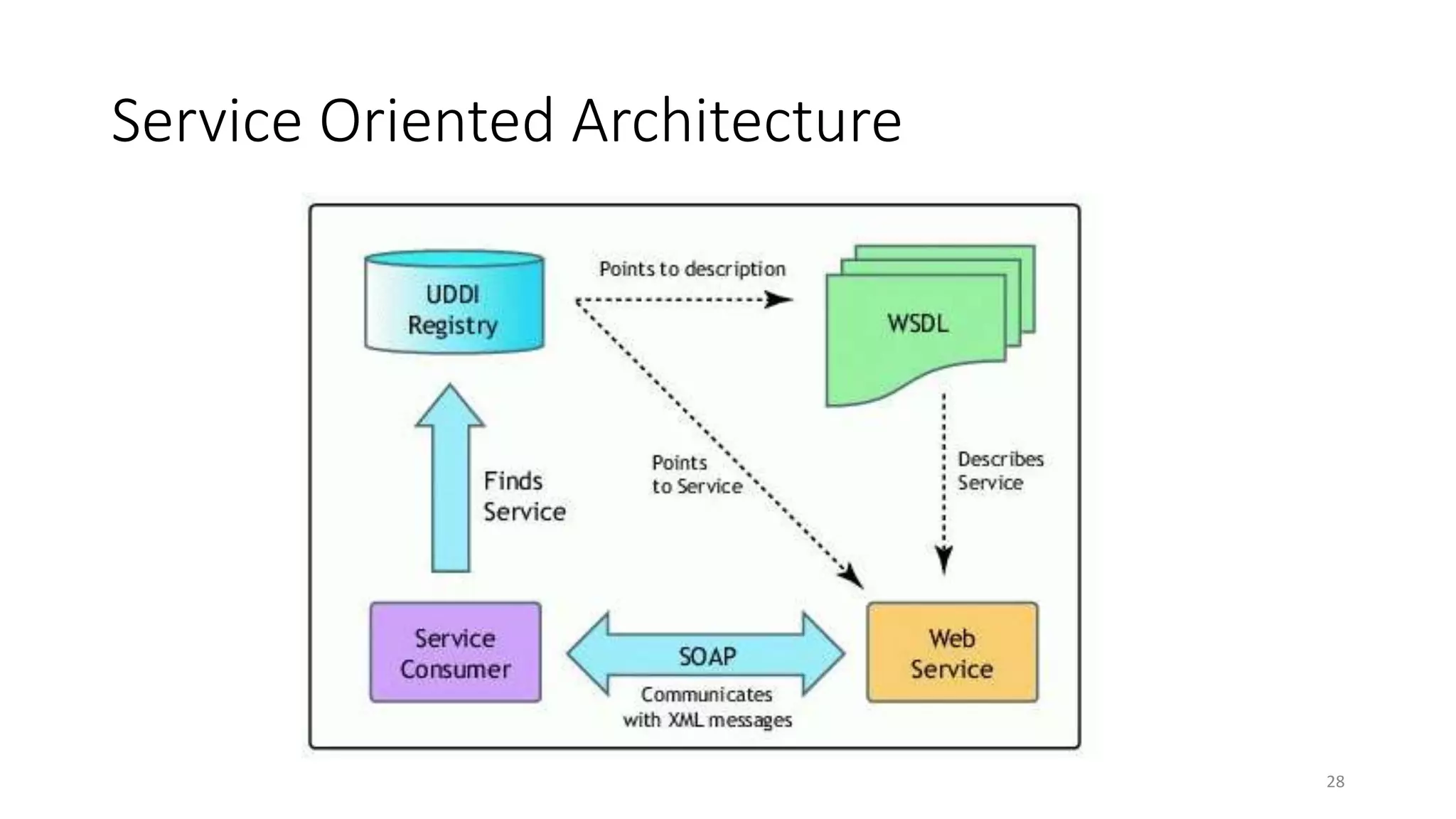

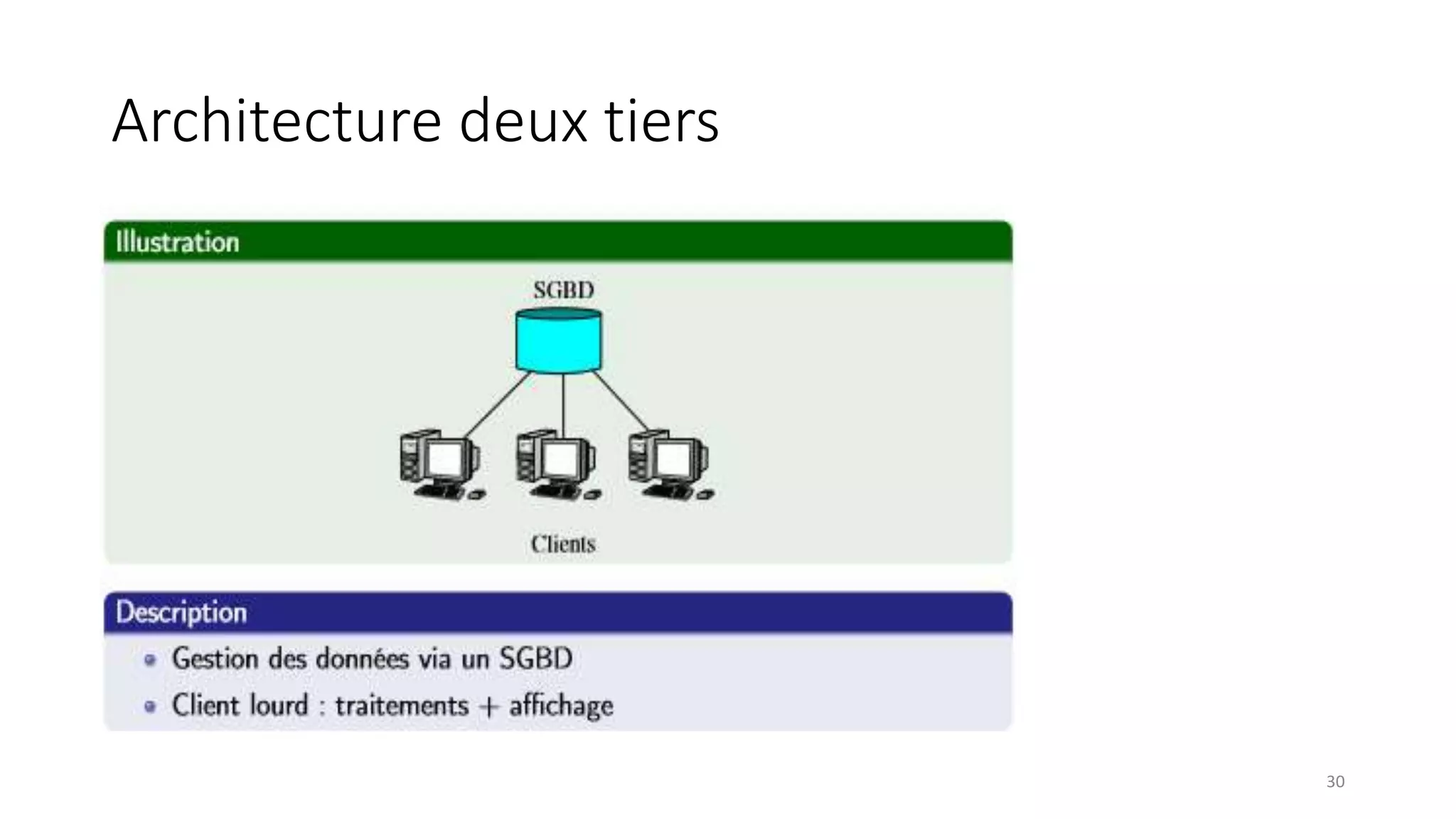
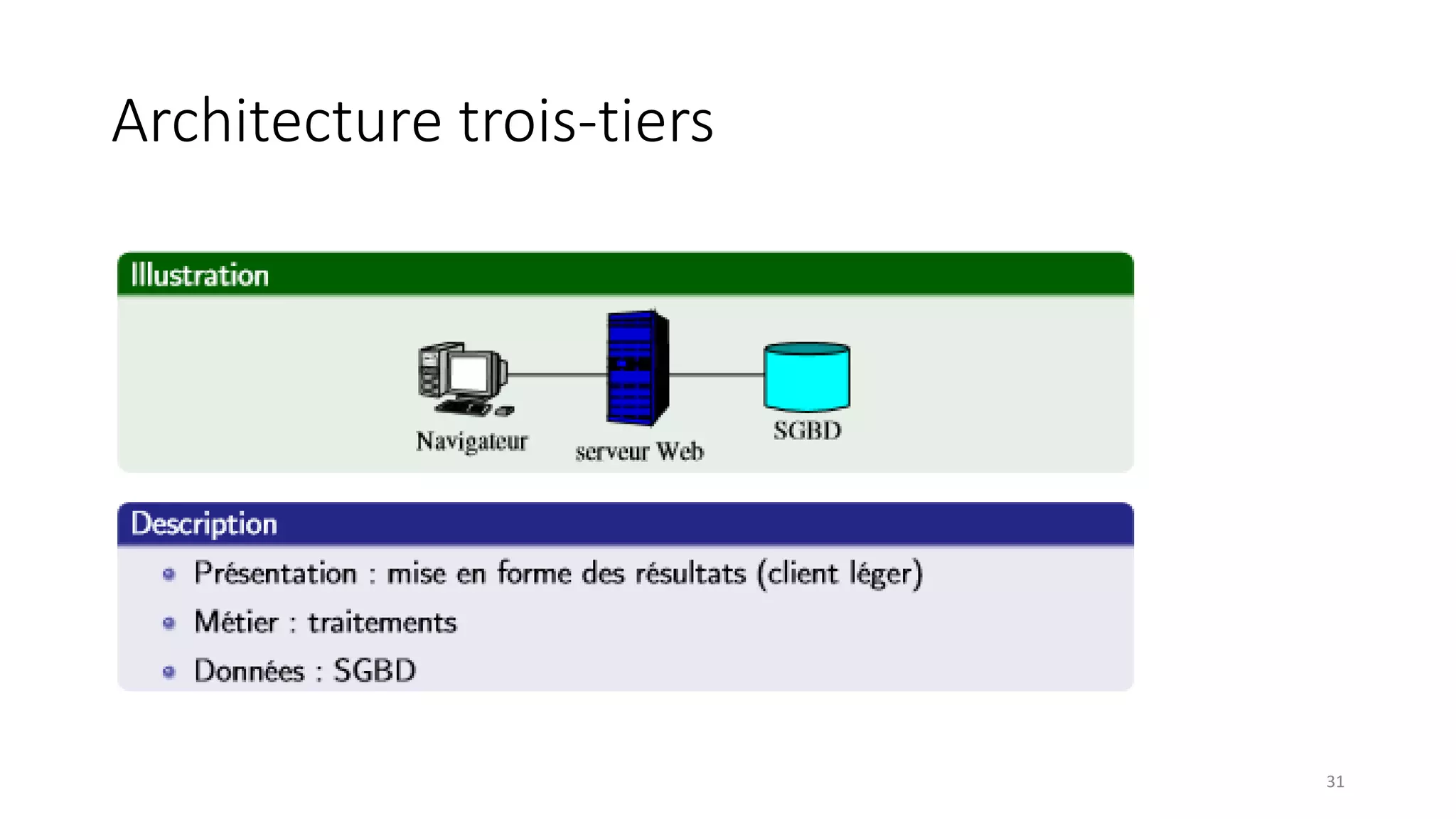
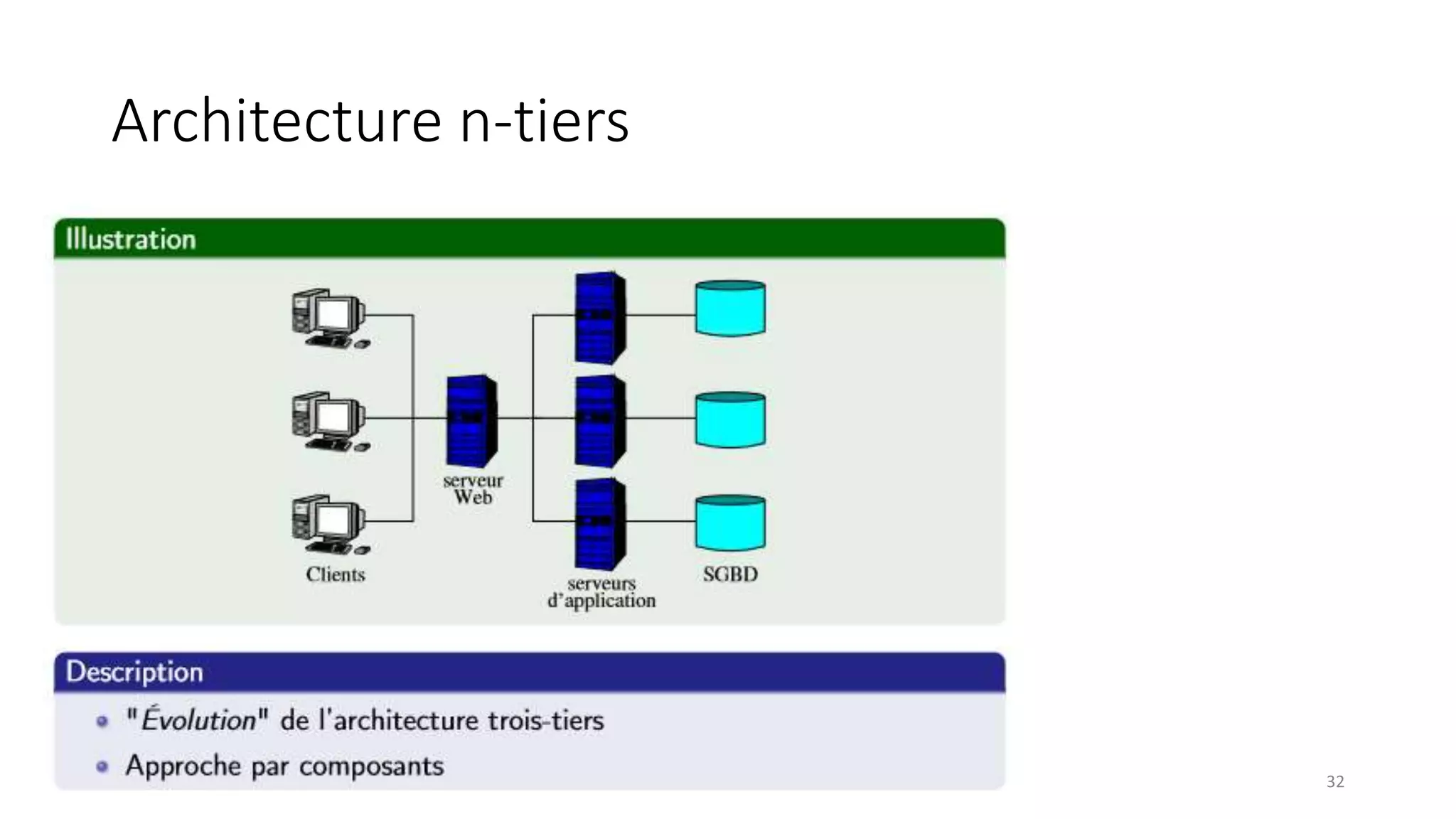

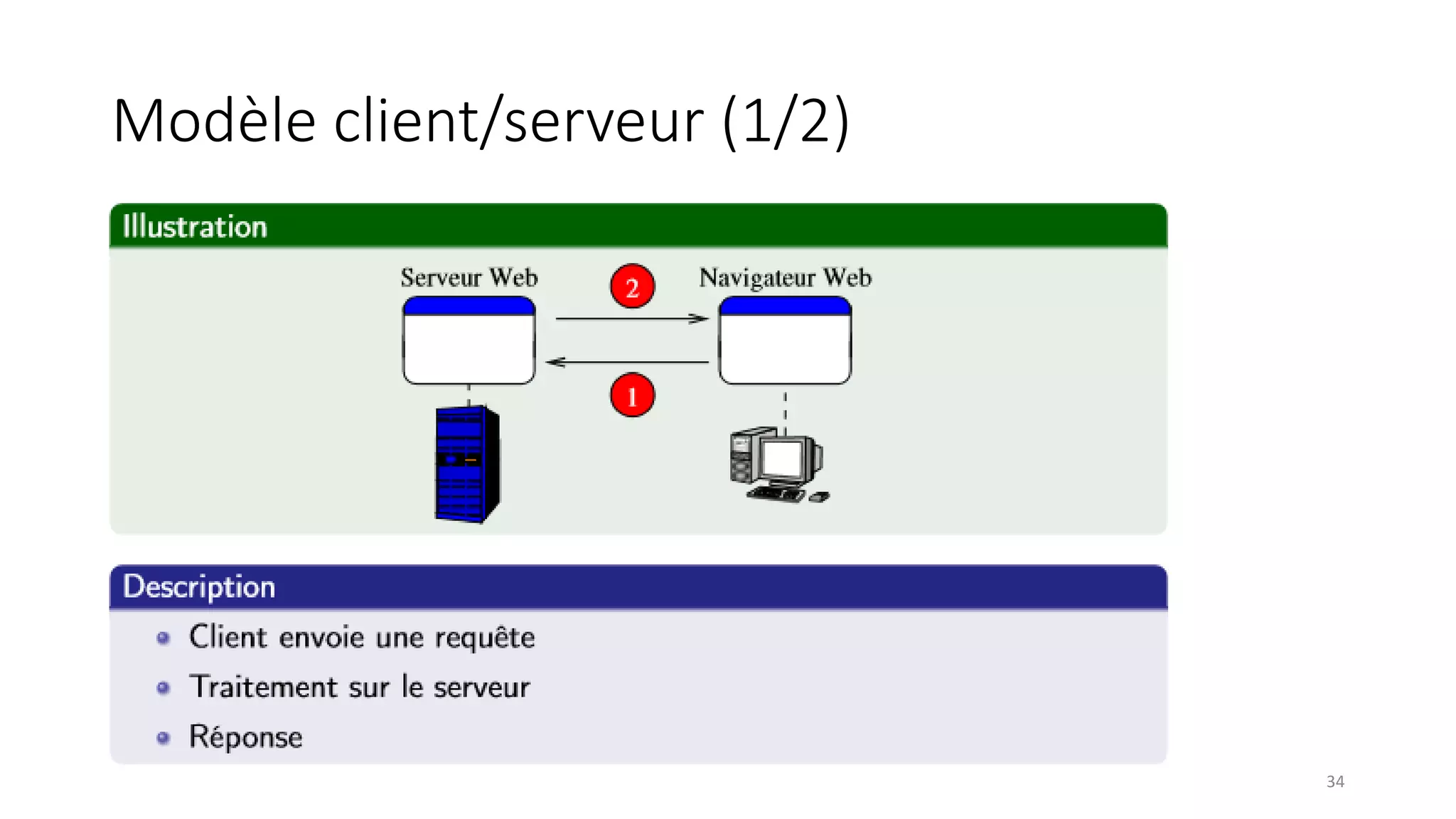
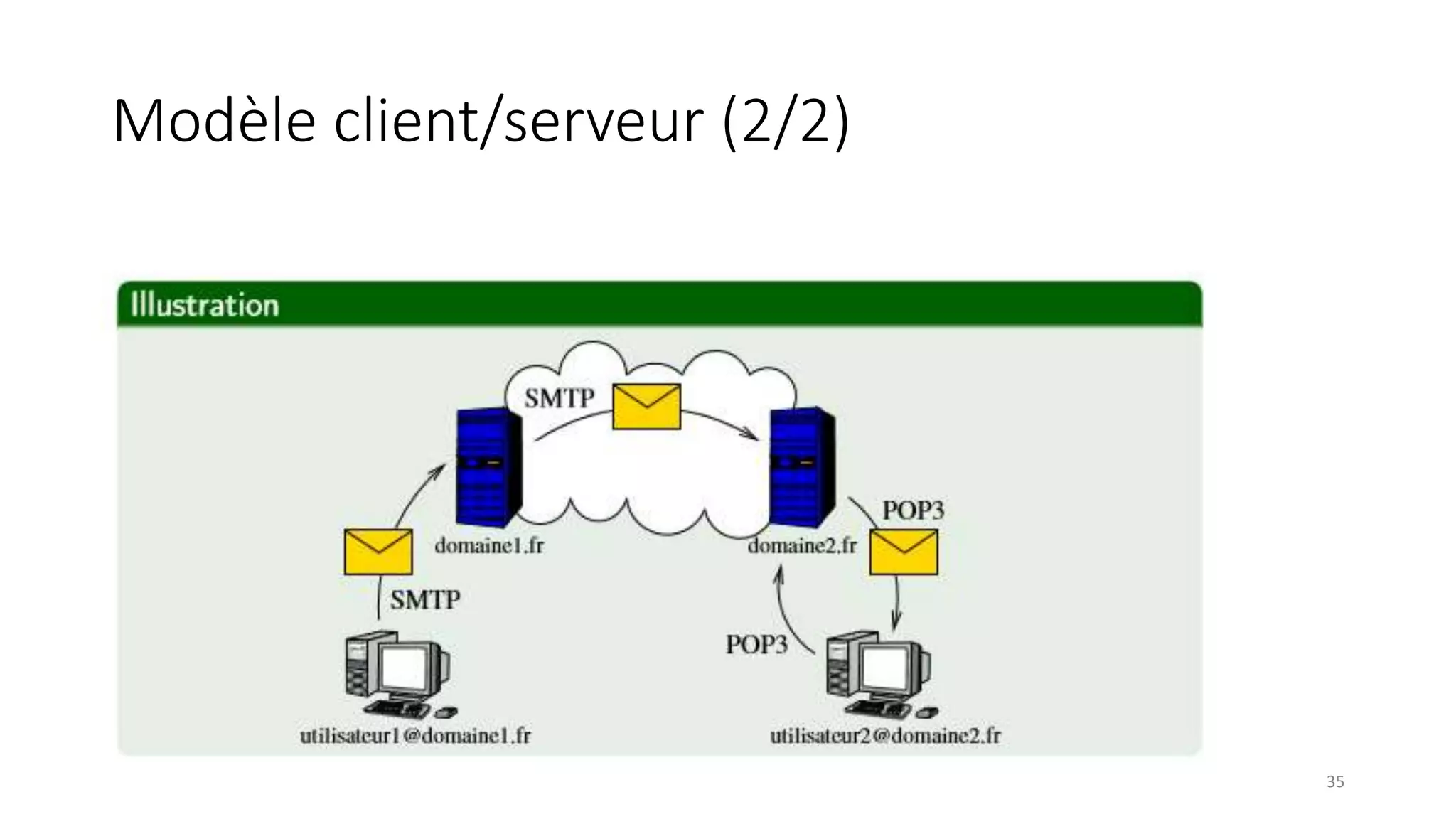

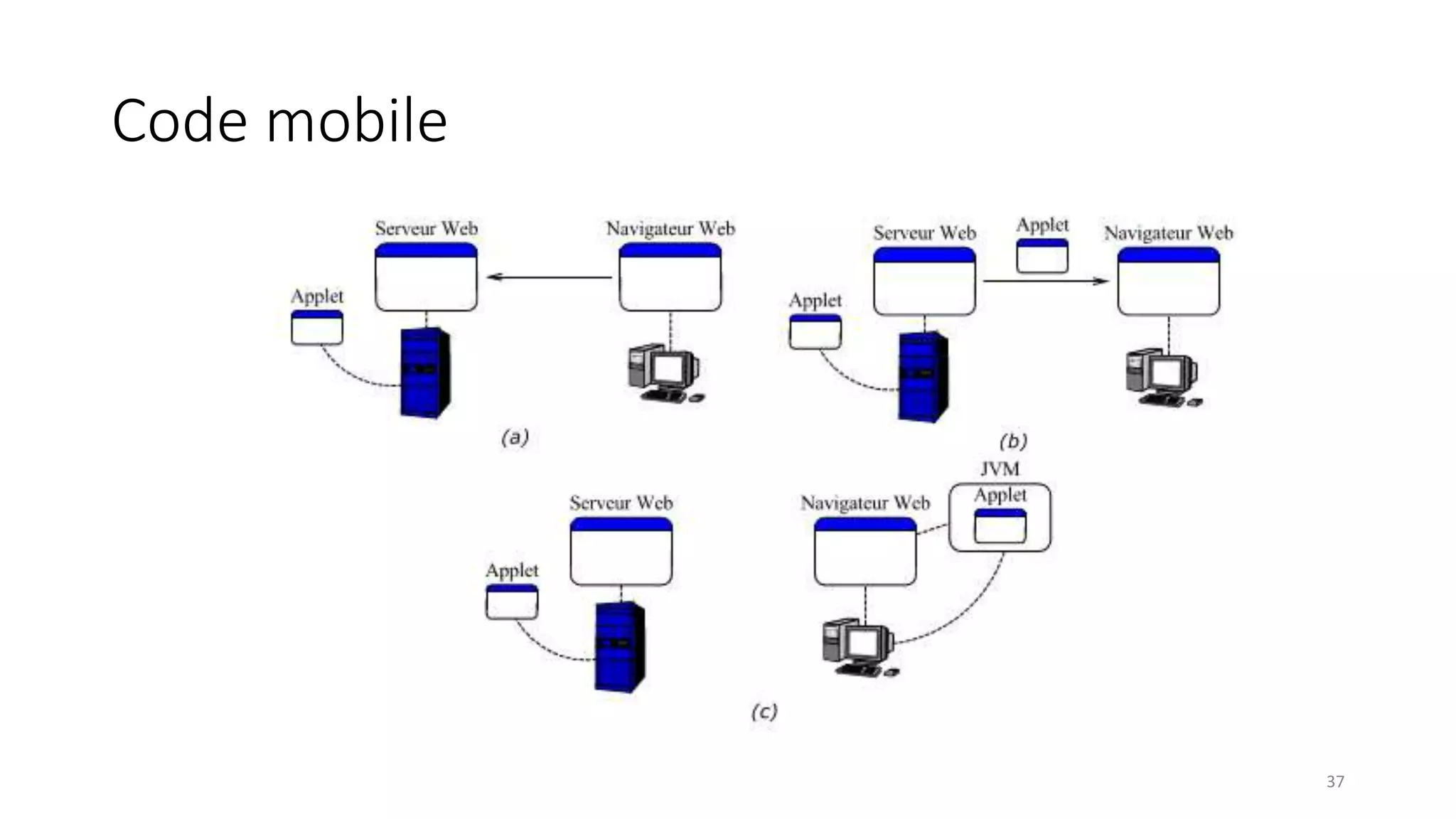
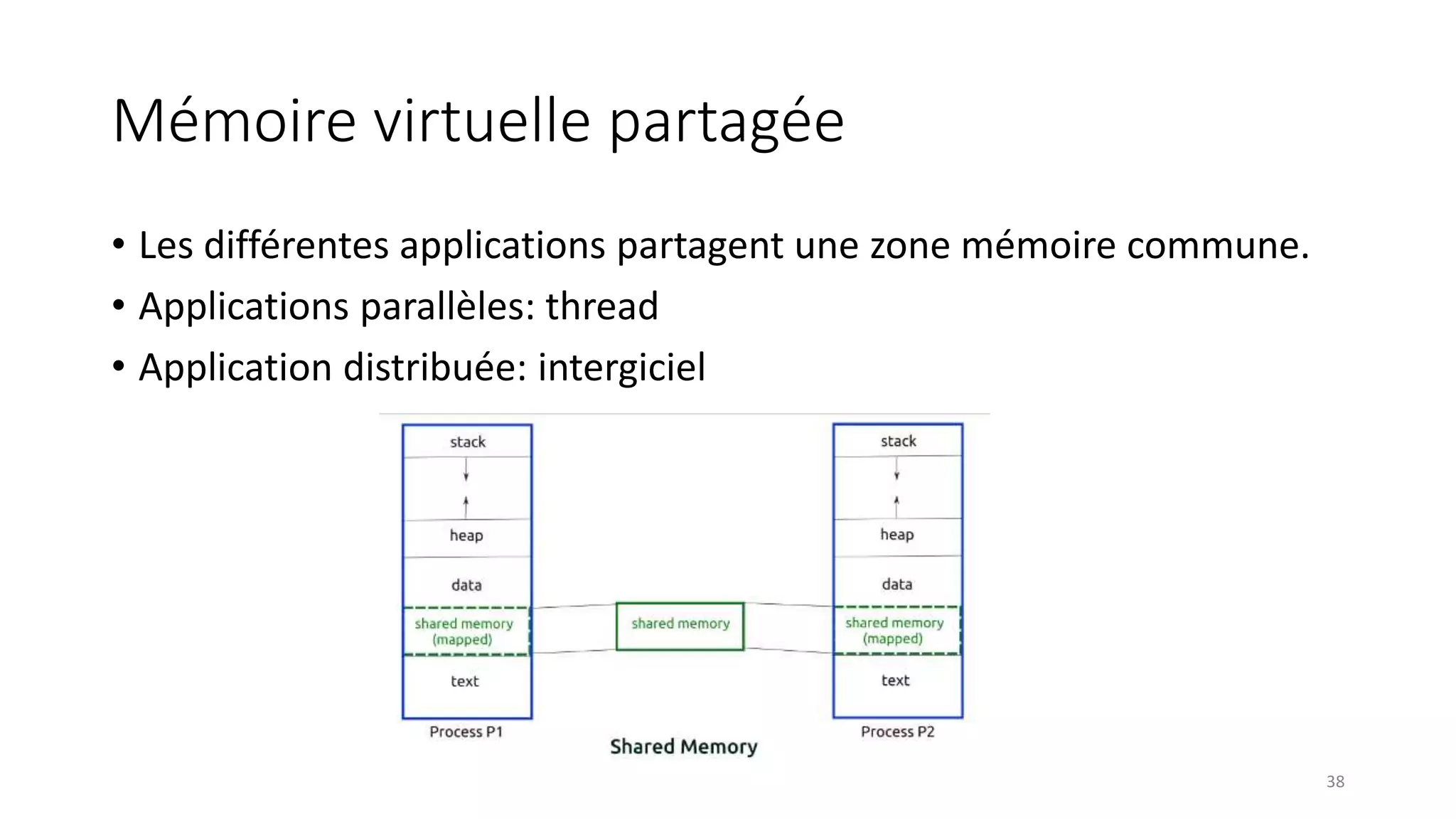

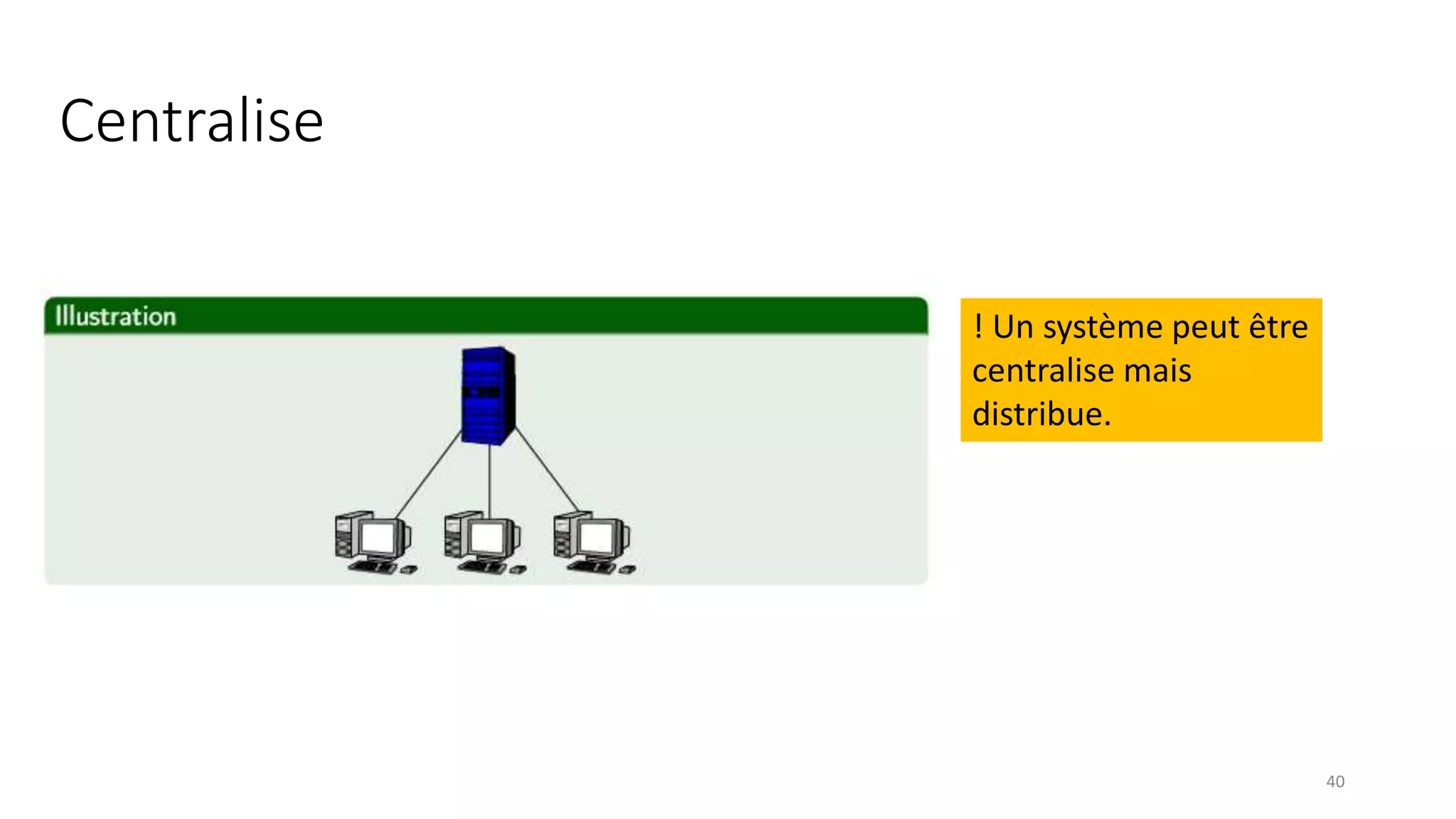
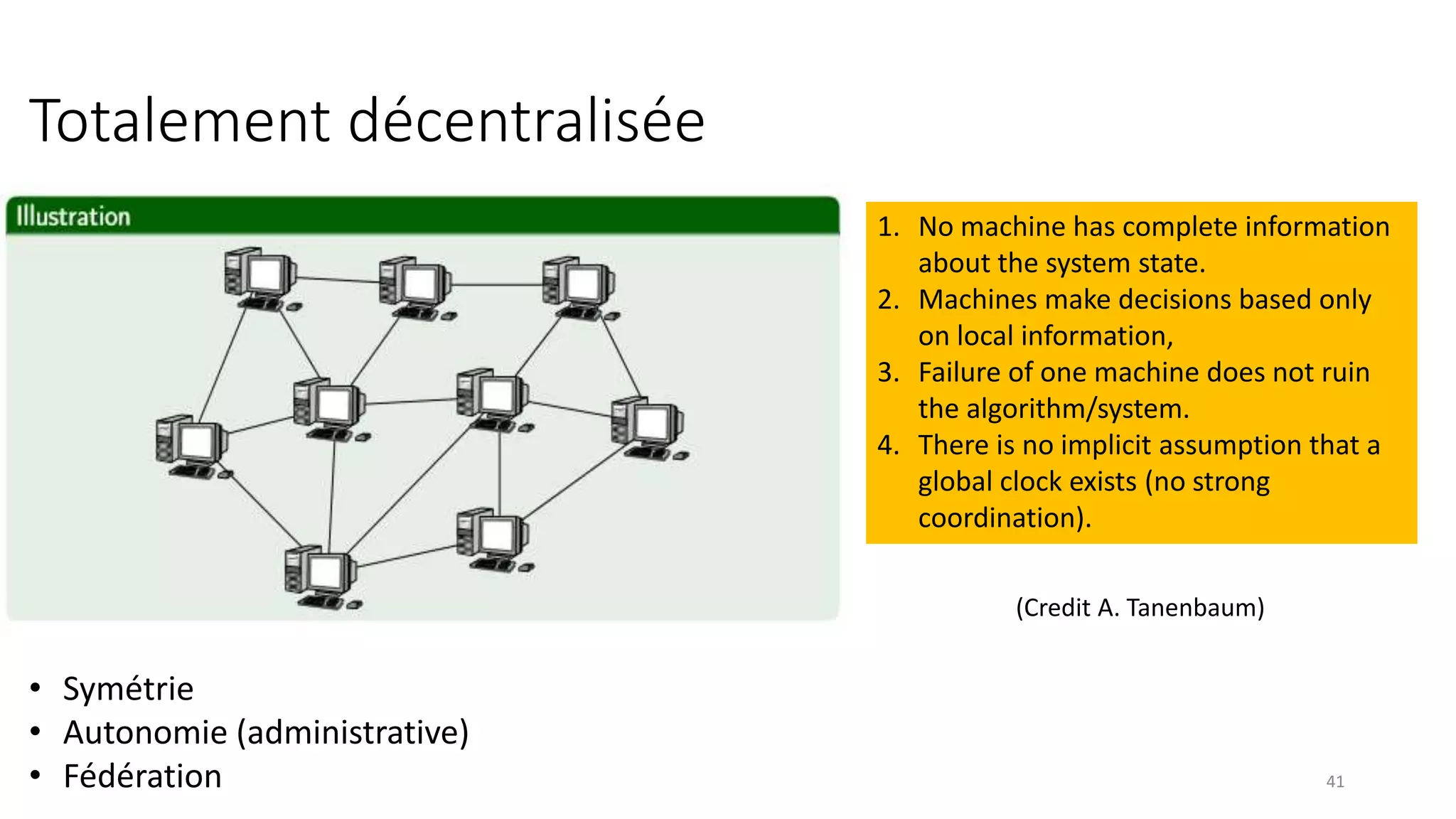
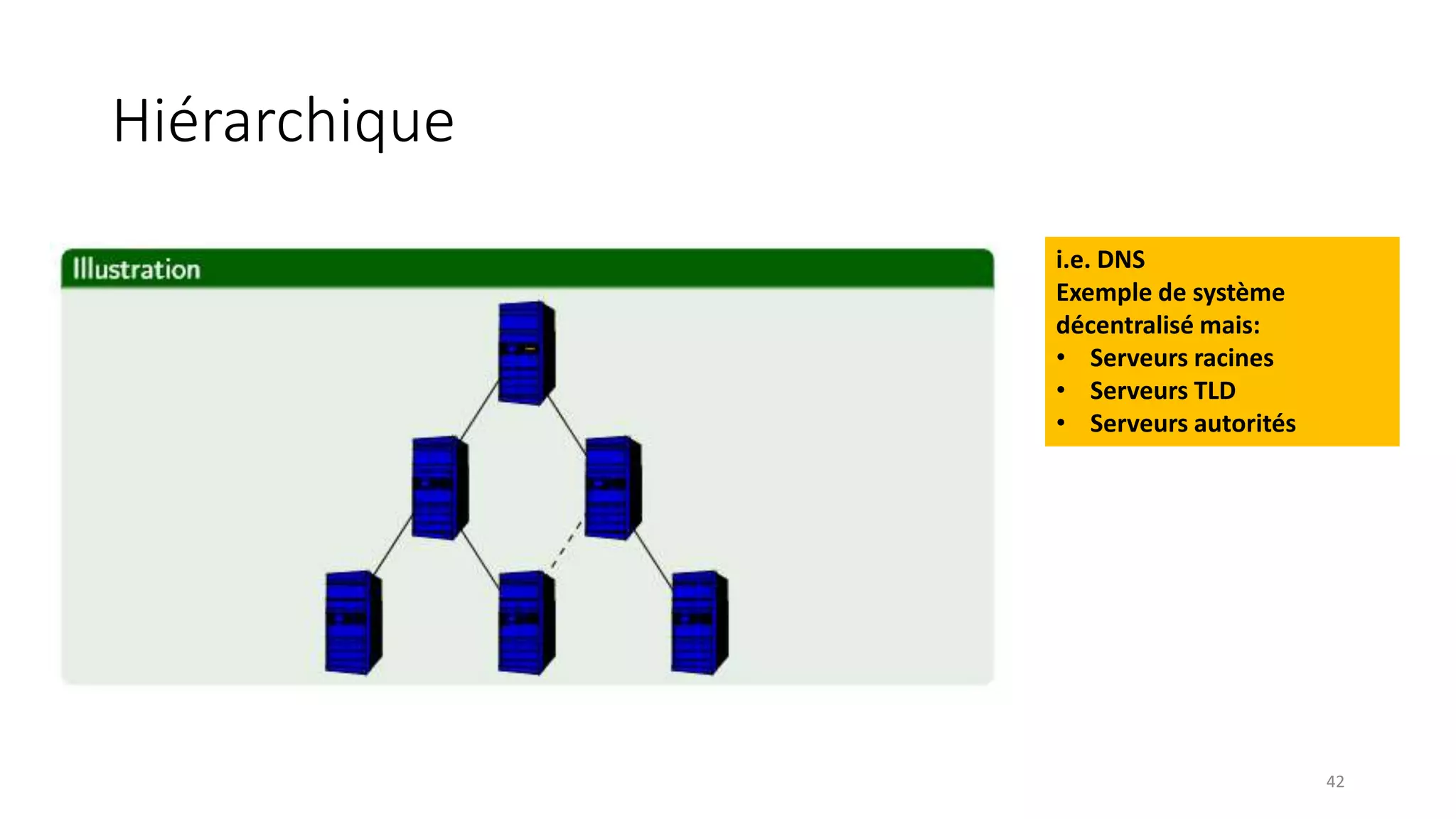
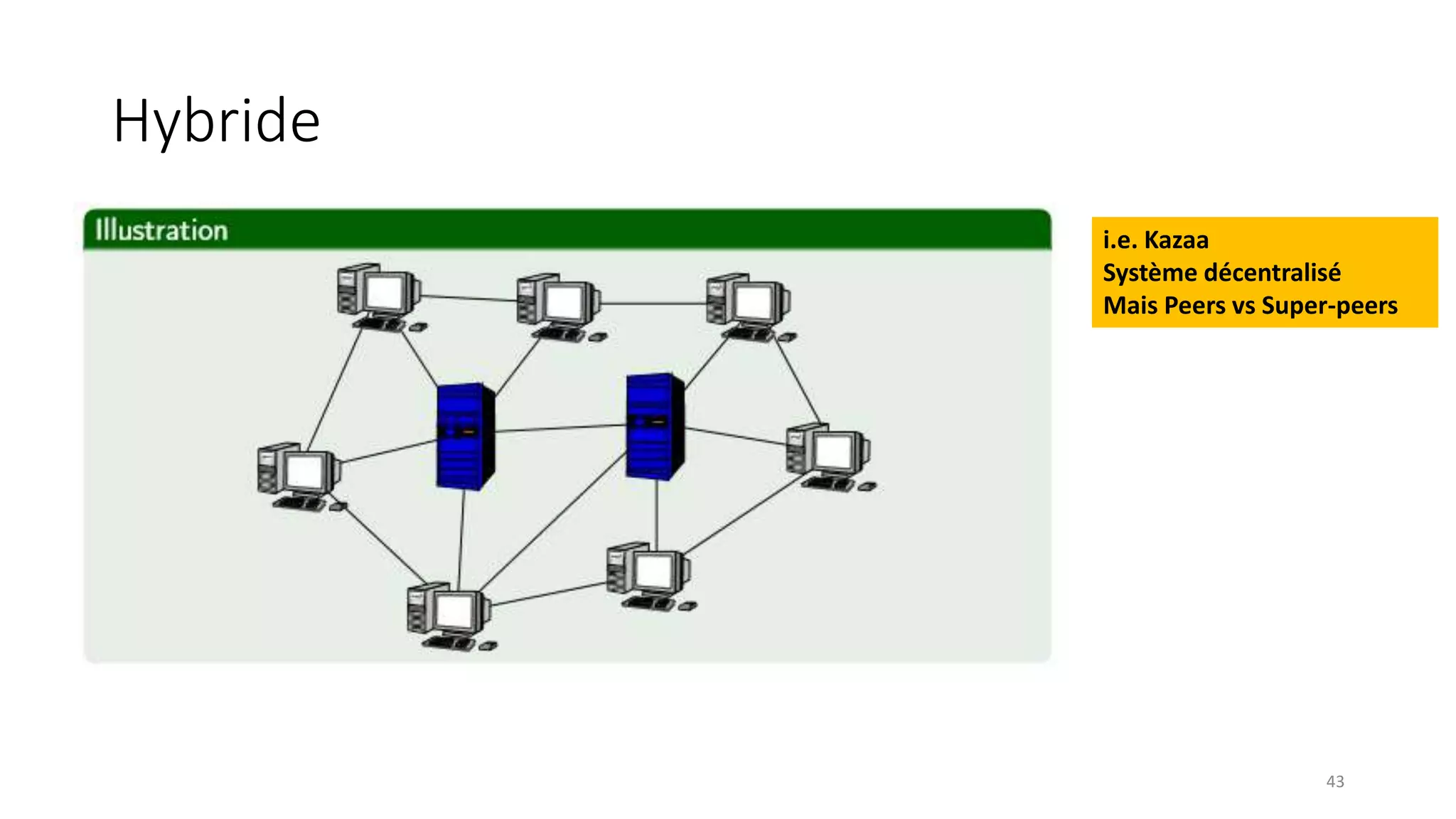

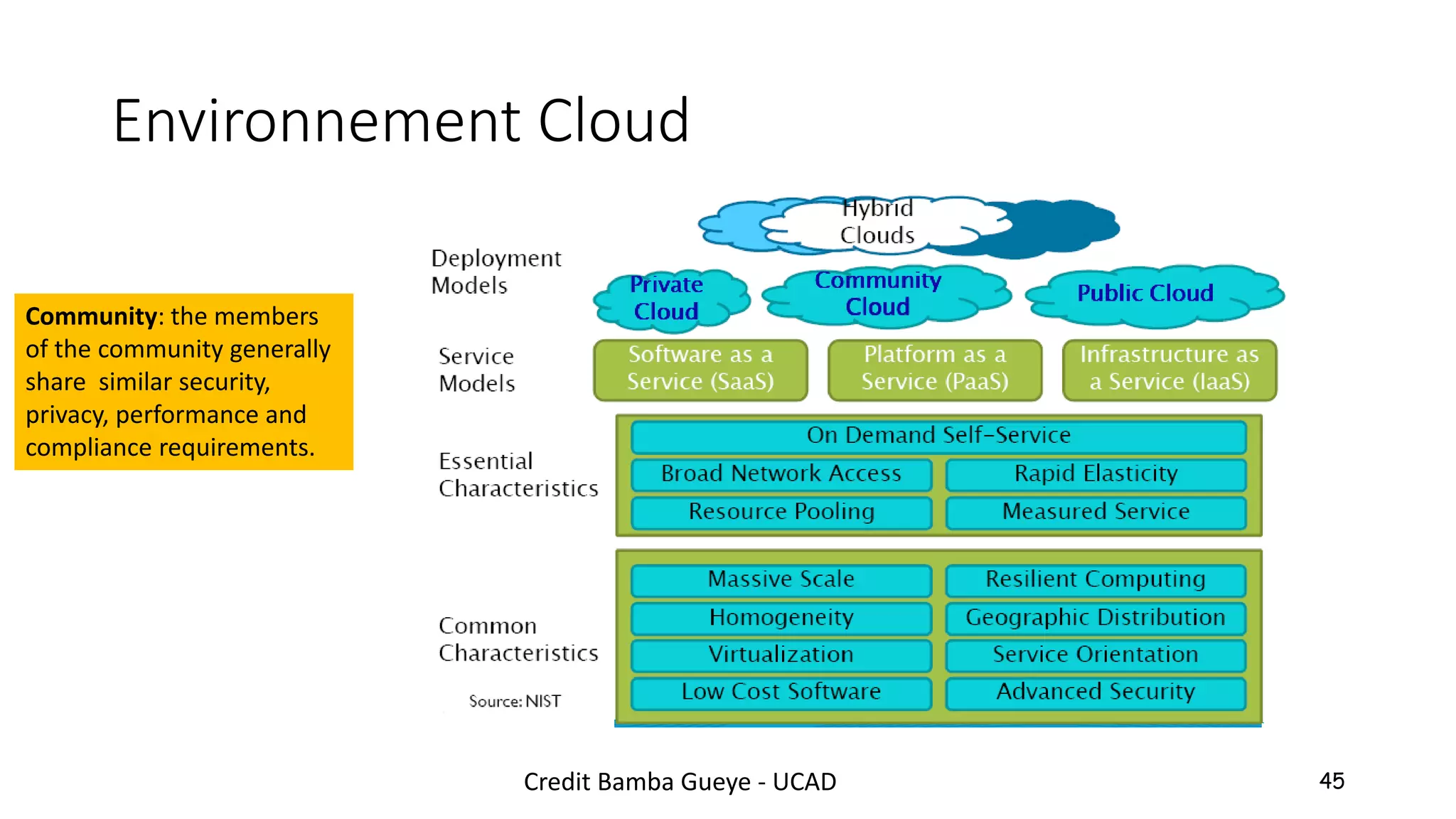

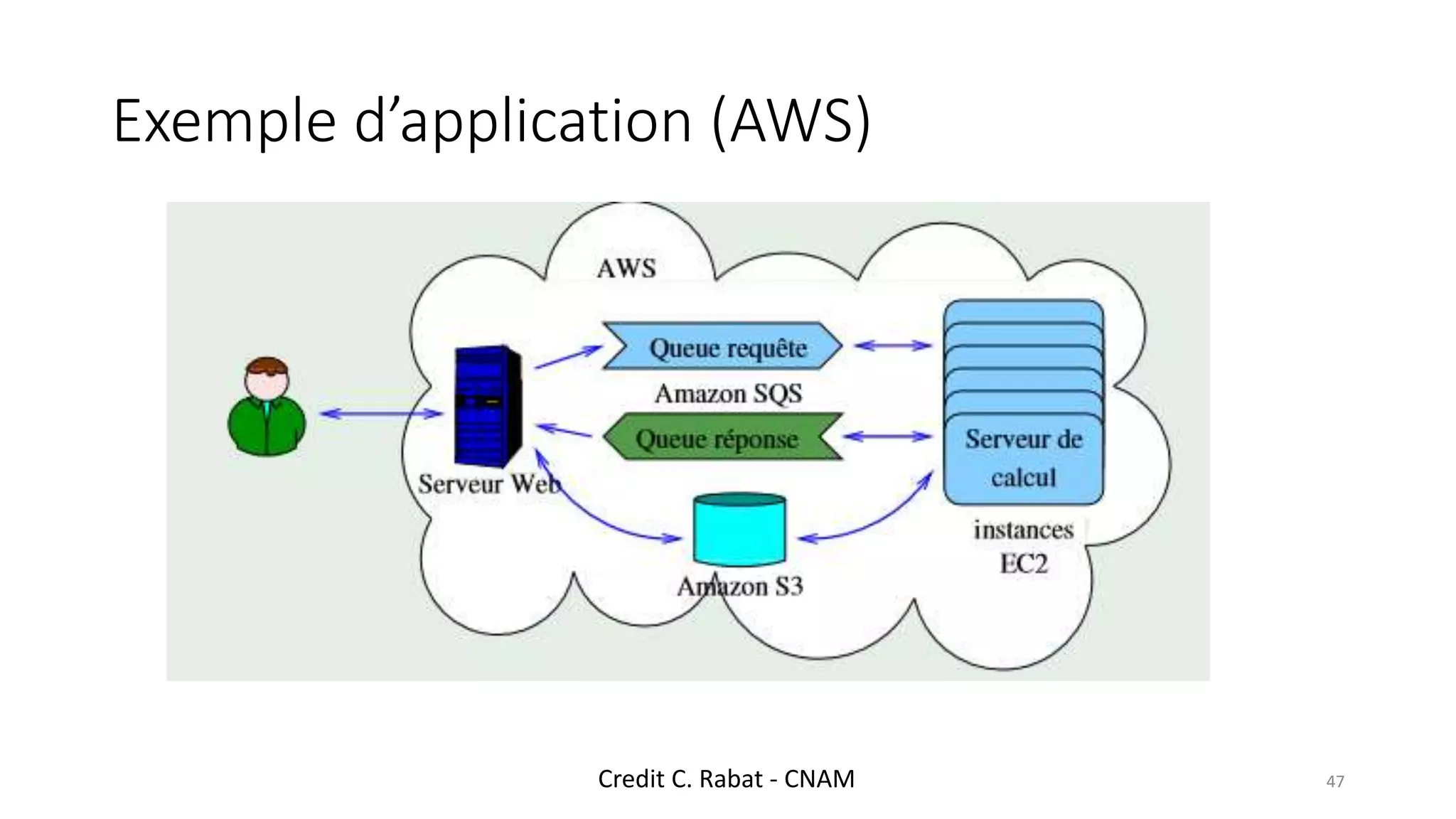







This document provides an overview of a distributed systems course taught in French. It includes the following key points: - The course objectives are to understand challenges in distributed systems, implement distributed systems, discover distributed algorithms, study examples of distributed systems, and explore distributed systems research. - The course consists of 8 sessions over 4 hours each that include lectures, tutorials, labs, presentations, and an exam. - Distributed systems are defined as independent computers that appear as a single coherent system to users. Key characteristics include concurrency, lack of global state, potential node and message failures, unsynchronized clocks, and heterogeneity.




























































