Downloaded 16 times








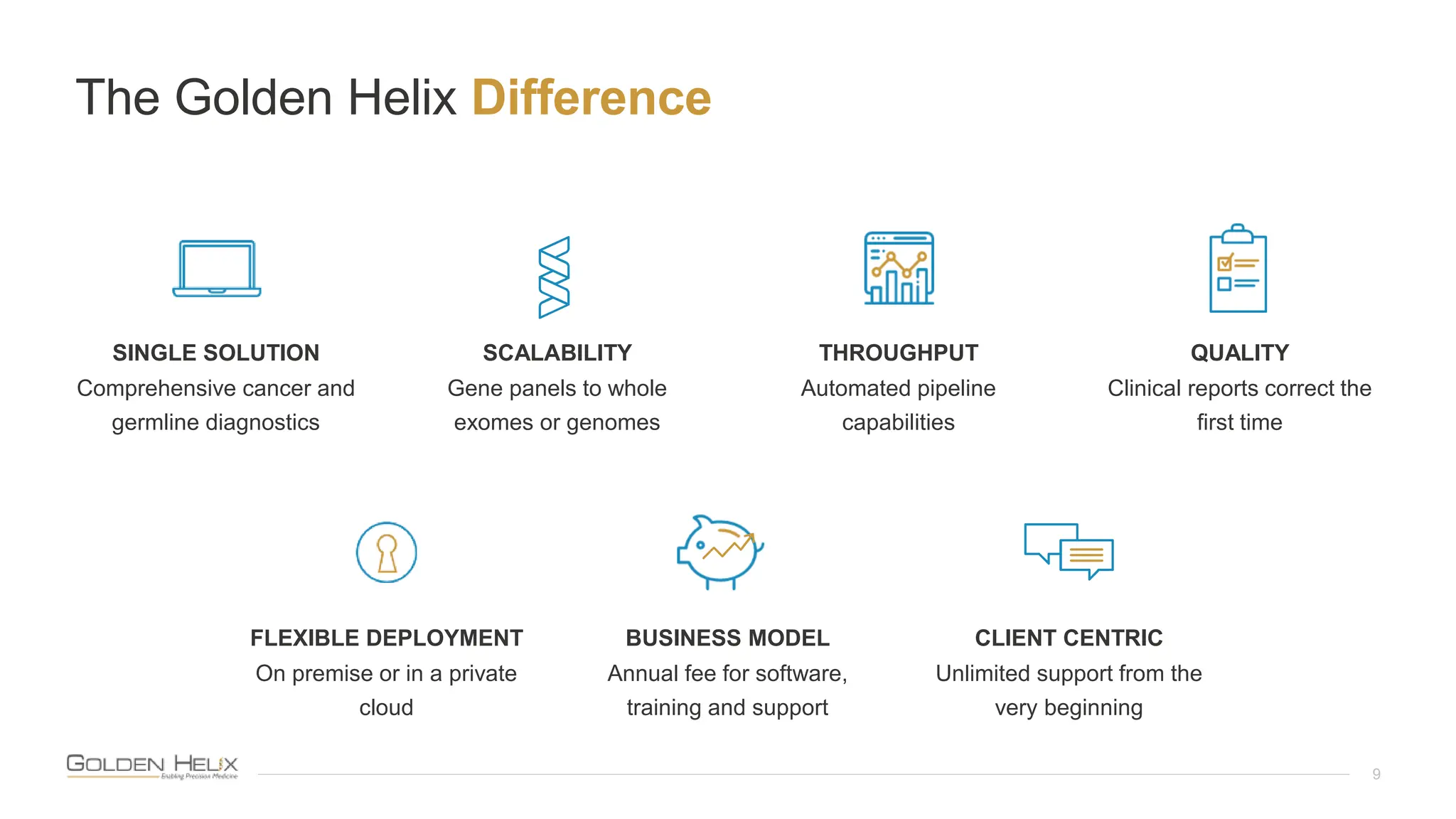

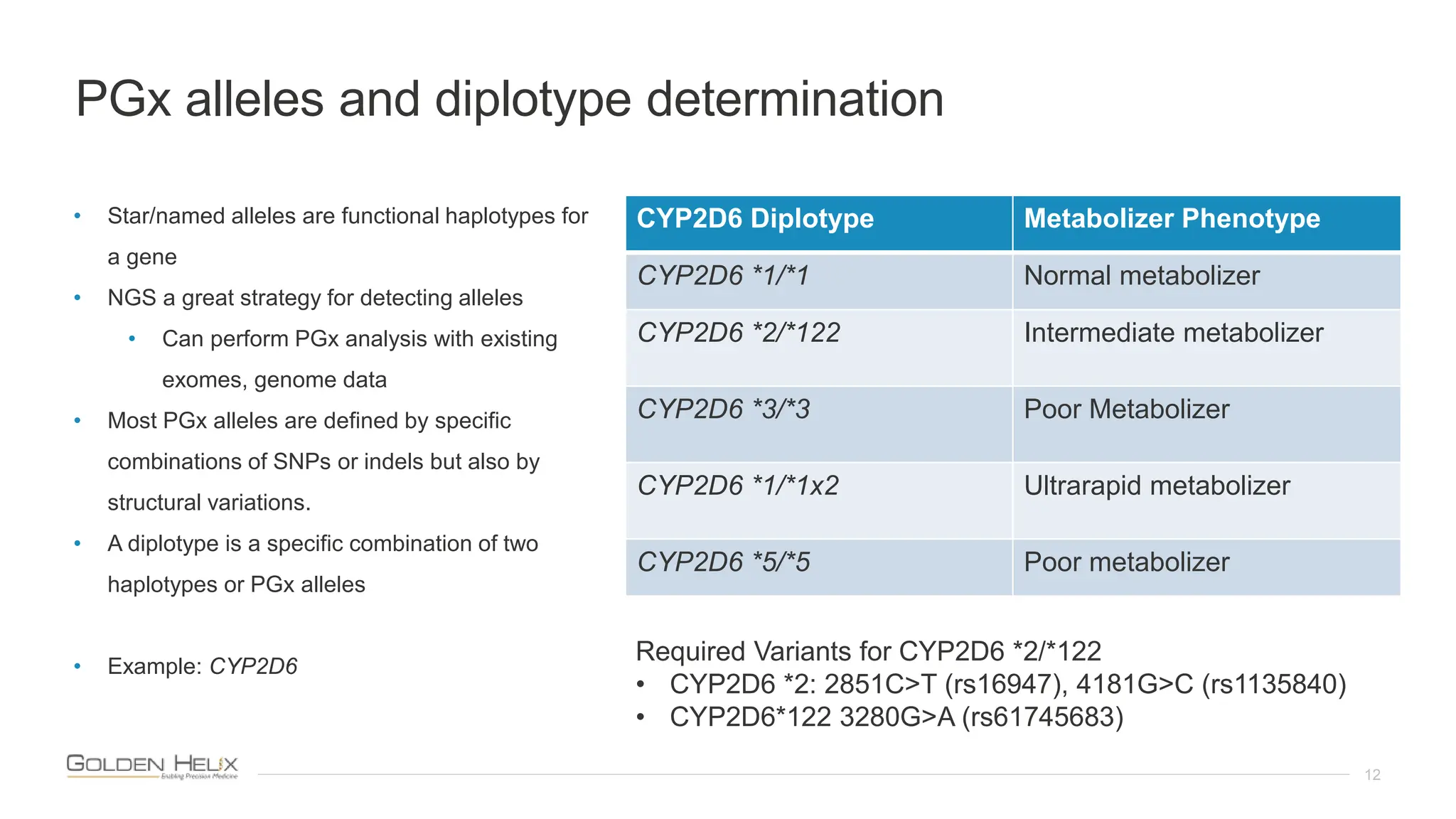











The document introduces VSPGX, a pharmacogenomics testing solution within the VarSeq framework, presented by research leaders from Golden Helix. It outlines the support from NIH grants and highlights the importance of pharmacogenomics in predicting drug response and treatment strategies based on individual genetics. Additionally, it describes Golden Helix's commitment to quality through ISO 13485:2016 certification and announces an upcoming user meeting to discuss advancements in genomic analysis.























![[DSC Europe 23][DigiHealth] Branka Zukic Big Data Personalized medicine](https://cdn.slidesharecdn.com/ss_thumbnails/vmdhfkttclbrtcstrq5w-branka-zukic-big-data-personalized-medicine-231130112724-18b0635c-thumbnail.jpg?width=640&height=640&fit=bounds)










































